







1、有了dnn和cnn为什么还要有rnn?
因为rnn能够有时间序列的结构,dnn和cnn的数据可以更换位置而不影响训练。但是对于rnn它有严格的先后顺序。这样的模型似乎对于语音识别,自然语言处理等应用场景更为符合。
基础结构如下:
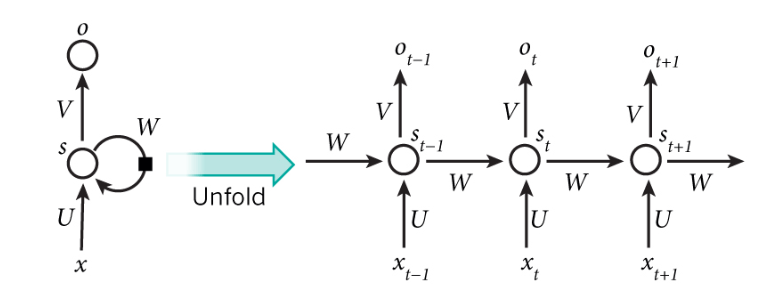
图1:rnn结构
注:
1)图中的 U W V三种权重参数是共享的。
2)St = f(U*Xt+W*St-1) 此处没有写b,有的地方还需要加一个b。f函数一般为tanh
3)Ot = softmax(V*St)
随后就是带入数据,更新权重。但这里有一个问题W与U使用bp更新时会有St-1的输入于是乎就有了BPTT的更新算法
2、BPTT算法 (Back Propagation Through Time)
从英文的字面意思中我们可以了解到,bptt其实就是因为输入变量为时间序列所以需要进行进一步的迭代。核心原理还是bp的链式法则。结合上面2个公式我们进行以简单对w的推导:
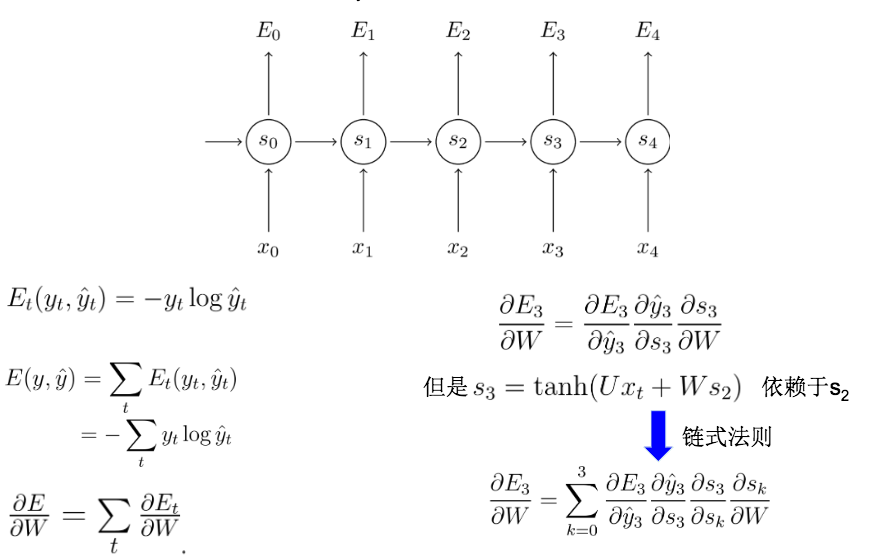
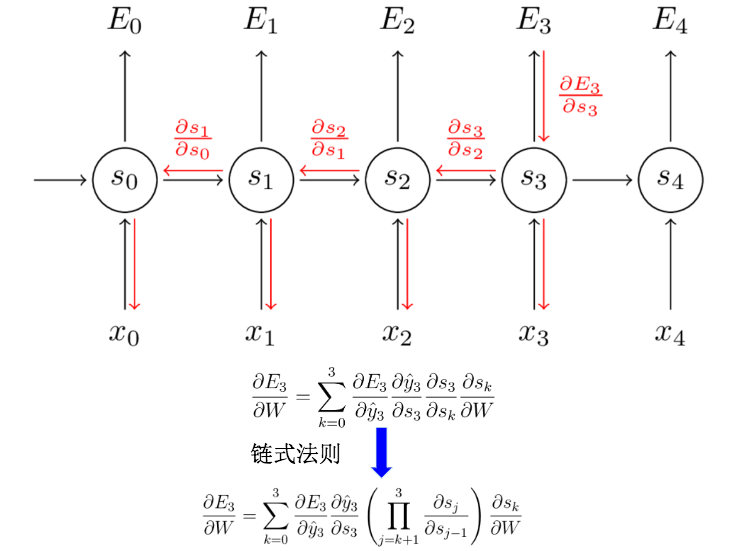
最终就是我们的权重更新公式。
3、RNN问题与LSTM
从上面的权重更新公式中,我们会发现里面有非常多的连乘。那么这就会带来一个很大的问题:梯度弥散。这也意味着像dnn一样,随着层次增多,它的训练效率会急剧降低。
为了解决这个问题,于是乎就有LSTM。
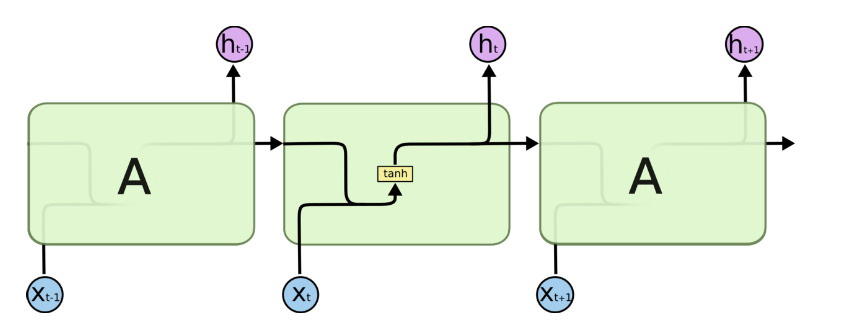
图 原始rnn结构
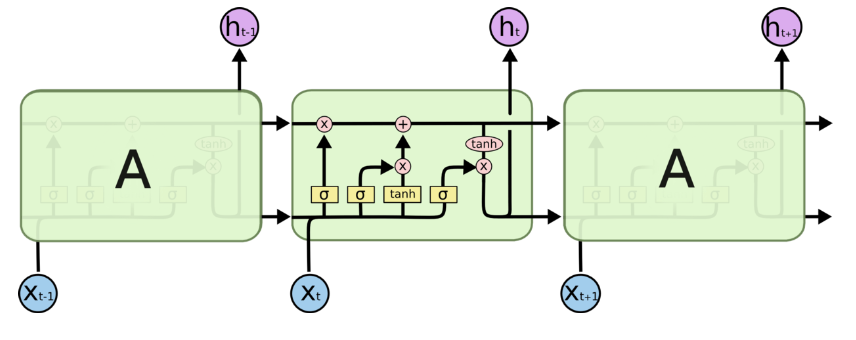
图 lstm结构
主要思想:
LSTM通过某种结构,缓解了梯度下降的程度。
公式推导参考文献:http://blog.csdn.net/u010754290/article/details/47167979
模型概念参考文献:http://www.jianshu.com/p/9dc9f41f0b29
TensorFlow中只有多层lstm代码实现:
参考代码与解释:http://blog.csdn.net/u014595019/article/details/52759104
参考内容:
寒小阳课程














 1645
1645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









