










背景
最近开始调研YARN-下一代资源管理系统,hadoop 2.0主要由三部分组成Mapreduce, YARN和HDFS,其中HDFS主要增加了HDFS Federation和HDFS HA,Mapreduce是运行在YARN之上的一种编程模型,而YARN是统一资源管理系统,YARN可以认为是HADOOP生态圈的云操作系统,在YARN之上可以运行多种计算编程框架,比如传统的MapReduce,Gigraph图计算,Spark迭代计算,Storm实时流计算模型等等,YARN的引入能极大提高集群的资源利用率,降低运维成本,共享底层数据。HADOOP 1.0发展了6年已经足够稳定,但是YARN出来2年让我们看到更多的优势,各大互联网公司都在往YARN方向迁移,YARN一定是未来。
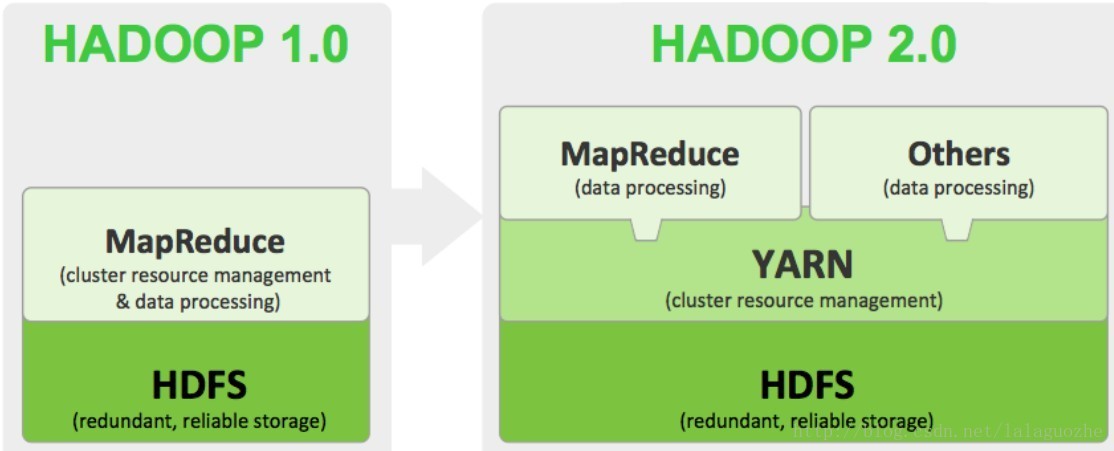
Hadoop 1.0到2.0的架构演化:
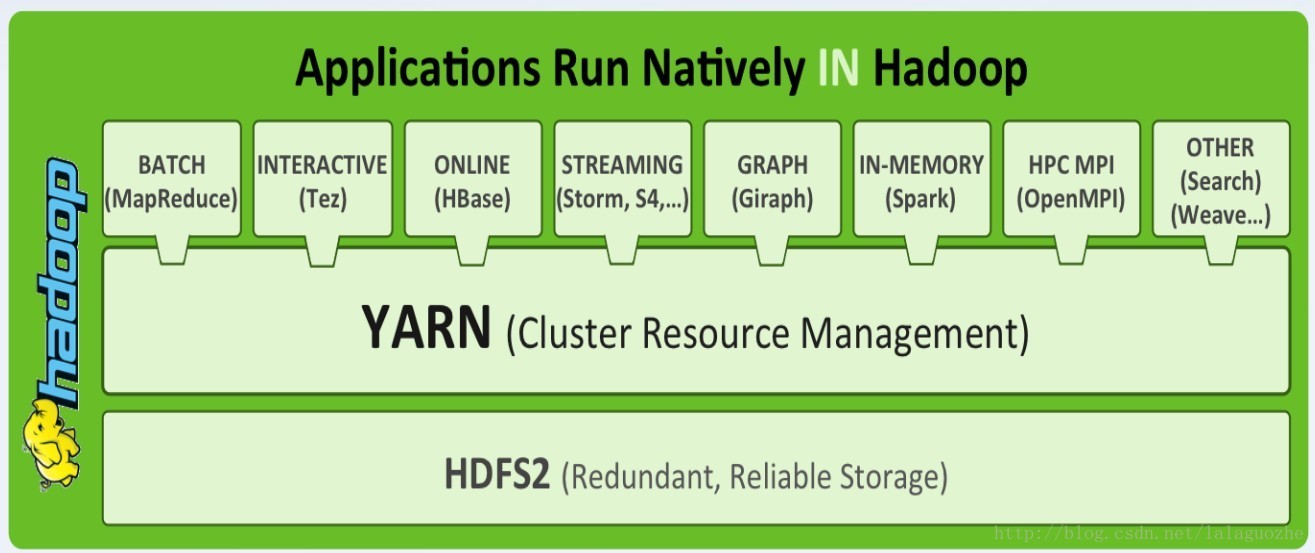
YARN Stack:
需求
我们在考虑hadoop map-reduce框架的时候,最重要需求包括:
1. reliability 可靠性,主要是jobtracker,resource manager可靠性
2. availability 可用性
3. scalability 可扩展性,能支撑10000到20000节点的cluster
4. backward compatibility 向后兼容性,支持之前写mapreduce application能不用修改而直接在新的框架上运行
5. evolution 可演化性,使得用户能对于software stack软件栈(hive, pig, hbase, storm等)能升级使之兼容
6. predictable latency 可预测的延迟时间
7. cluster utilization 集群利用率
其他的需求包括:
1. 支持除了map-reduce之外其他的编程模型,比如图计算,流式计算
2. 支持短时间的services
基于上述的需求,很明显需要对于hadoop架构重新思考,现在的mapreduce框架很慢满足,未来需要一个两层的调度器
下一代MAPREDUCE(YARN)
MRv2拆分了JobTracker两个最重要的功能,Resource Managerment资源管理和Job Scheduling/Monitoring作业调度和监控。会有一个全局的ResourceManager(RM)和每个application独立的一个ApplicationMaster(AM),一个application可以是一个单独的mapreduce job也可以是一个DAG Job。ResourceManager和每个slave节点一个的NodeManager组成了计算框架,对于所有的applications,RM拥有绝对的控制权和对于resource的分配权,而AM则是一个框架下特定的一个库,它会和RM协商资源,同时和NodeManager通信来执行和监控task
ResourceManager有两个组件
1. Scheduler调度器
2. ApplicationsManager (ASM)
MRv2引入了新的概念叫Resource Container(资源容器),它由cpu,内存,disk,network组成,它不同于第一代的map slot和reduce slot,slot只能对于整体node的资源划分粒度很粗,如果slot个数为N,则每个slot就是整台机器资源的1/N,而引入container后,application则可以根据自身的需求动态申请所需的资源。
Scheduler是可插拔的,它来负责分配cluster resources,目前支持的有CapacilityScheduler和FairScheduler
ApplicationsManager负责接收job提交,并且申请第一个container来运行ApplicationMaster,并且在AM failure的时候提供重启
NodeManager是每个slave节点上的daemon,它来负责启动application containers,监控resource使用情况(cpu, memory, disk, network),并且汇报给Scheduler
ApplicationMaster从Scheduler中得到合适的containers,并且跟踪他们的状态和进度
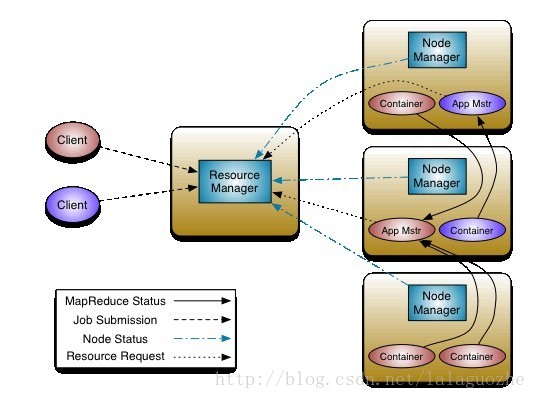
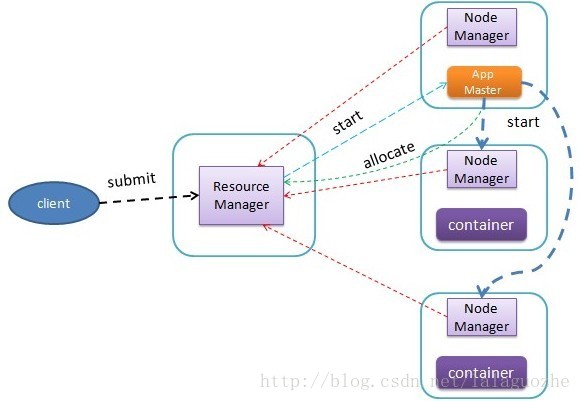
YARN v1.0
yarn 1.0 仅仅考虑了memory,每一个node都有多个minimum size of memory(比如512MB或者1GB),ApplicationMaster可以申请多个minimum memory size(注:现在已经支持CPU和memory两种资源隔离,对于内存采用线程监控方式,对于CPU采用cgroups隔离方式)
AM负责计算资源需求(比如input-splits),并且转换成Scheduler能理解的协议,比如<priority,(host,rack,*),memory, #containers>
比如对于map-reduce,AM得到input-splits后,将基于host地址的倒排表和containers数的限制大小提交给RM Scheduler。
Scheduler会尝试匹配相应的host,如果指定的host不能提供resources,就会提供相同rack下或者不同rack下的resources。AM可以接受,也可以拒接这些资源。
Scheduler调度器
在Scheduler和AM之间只有一个API
Response allocate(List<ResourceRequest> ask, List<Container> release)
AM通过一串ResourceRequest来申请资源,并且释放之前分配到的不需要的Containers
返回的Response中包含了一串新分配的Containers,上次AM和RM通信之后已经完成的container状态,集群可用资源量。AM收集完信息,并对失败的任务作出反应,剩余量(headroom)信息可以用来调整之后申请资源的策略,比如调整map和reduce数来防止死锁的情况(全部被map占满,reduce处于饥饿状态)
Resource Monitoring资源监控
Scheduler会从NM中周期性的获得已分配的container的资源使用情况,然后设置container为可用的状态提供给AM
Application submssion
apllication提交的流程如下:
1. 用户(通常在gateway上)提交job到ASM
1). 用户端首先生成一个ApplicationID
2). 打包Application描述定义,上传到HDFS上${user}/.staging/${application_id}
3). 提交application到ASM
2. ASM接受application提交
3. ASM和Scheduler协商获取第一个container来启动AM并启动之
4. 同时ASM提供AM的详细信息给client,使之能监控到progress状态
ApplicationMaster的生命周期
ASM管理着AM的生命周期,ASM负责启动AM,之后ASM监控AM,AM会周期性heartbeat给ASM来保证它还活着,如果failure的时候重启
ApplicationsManager部件
1. SchedulerNegotiator 负责和Scheduler协调来获得启动AM的container
2. AMContainerManager 负责启动和停止AM的container,会和合适的NM通信来完成
3. AMMonitor 负责管理AM的活跃性,如果有必要的话会重启AM
Availability 可用性
ResourceManager会将自己的状态保存在Zookeeper中还保证HA,基于zk状态保存策略可以迅速重启
NodeManager
一旦scheduler分配容器给application,NM就负责启动这些容器,它还保证分配的容器不会超过机器的资源总额
NM也负责task启动时候的环境设置,包括二进制和jar包等等
NM也提供一个service来管理本地节点的存储资源,比如对于map-reduce application会使用shuffle service来存储本地临时的map outputs,并且shuffle到reduce tasks
ApplicationMaster
AM负责和Scheduler协调资源,在NM中执行和监控task,当container失败的时候,需要从Scheduler中申请其他资源
AM负责计算资源需求,并转换成Scheduler理解的协议
Map-Reudce Job 执行流程如下:
1. MR JobClient提交job到RM中的ASM而不是JobTracker
2. YARN ASM和Scheduler协调获得MR AM的container,并启动它
3. MR AM启动并注册到ASM中
4. MR JobClient从ASM中获取MR AM的信息,然后直接和AM通信来获取status,counters等等
5. MR AM 计算input-splits,创建所有maps的resource requests
6. AM执行job setup API(Hadoop MR OutputCommitter)
7. AM提交map/reduce tasks的resouce requests到YARN Scheduler,从RM中获得containers,然后从获得的containers中得到合适的task来和NM通信启动container
8. MR AM监控到每个task,如果task fail或者不反应时会重新申请资源
9. MR AM执行OutputCommitter的task cleanup代码
10. 一旦map和reduce tasks都完成了,MR AM会执行OutputCommitter的job commit和abort api
11. job完成,MR AM退出
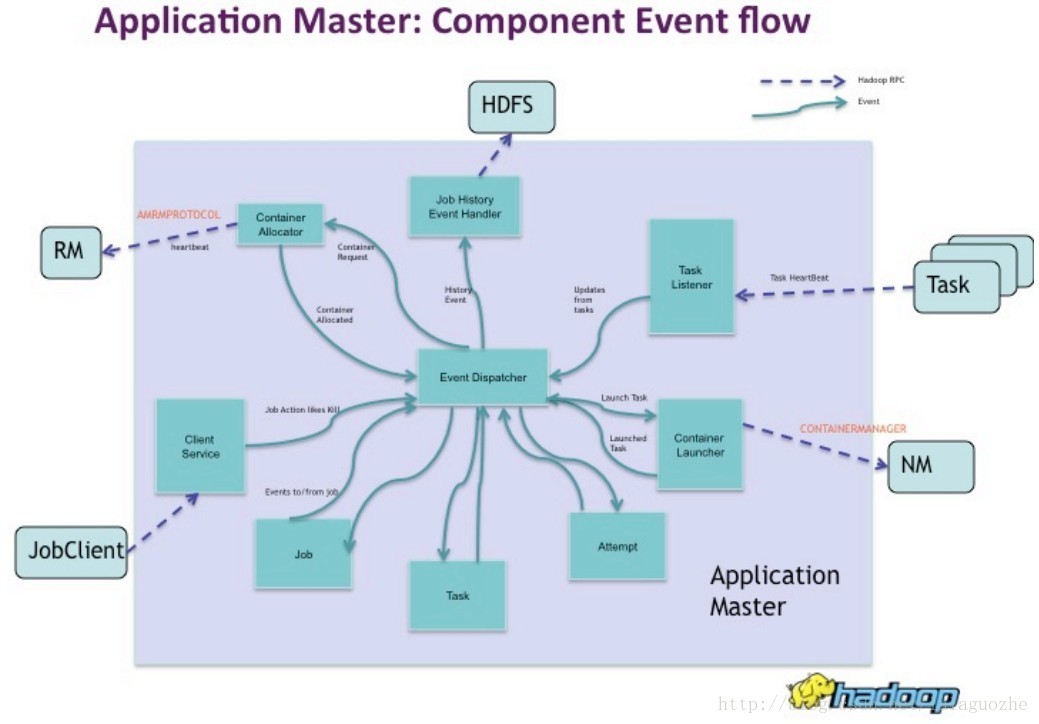
MapReduce ApplicationMaster有以下部件:
1. Event Dispatcher 中央event的协调器
2. ContainerAllocator 负责将task资源需求转换成resource requests协议
3. ClientService 负责和MR JobClient通信来反馈status,counter,进度信息
4. TaskListener 从map/reduce tasks获取heartbeats
5. TaskUmbilical 从map/reduce tasks获取heartbeat和status信息
6. ContainerLauncher 负责和NM通信来启动容器
7. JobHistoryEventHandler 写job history事件到HDFS
8. Job 负责维护job和tasks的状态
参考:
http://dongxicheng.org/mapreduce-nextgen/nextgen-mapreduce-introduction
https://issues.apache.org/jira/browse/MAPREDUCE-279














 1742
1742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









