









相信大家都看过CNN的网络框架,我就先从这篇文章框架说起,下面是Alexnet的网络结构:
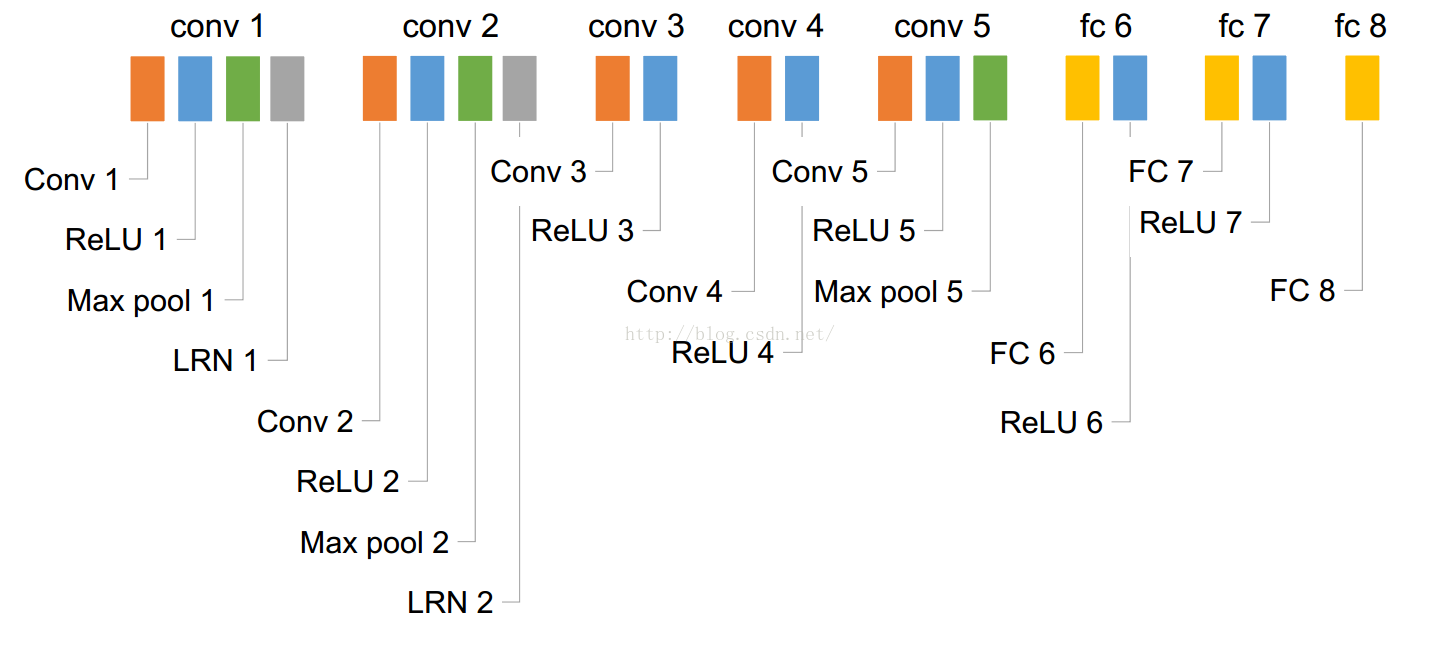
这下面数字流程图的制作参考:http://blog.csdn.net/sunbaigui/article/details/39938097
1. conv1阶段DFD(data flow diagram):
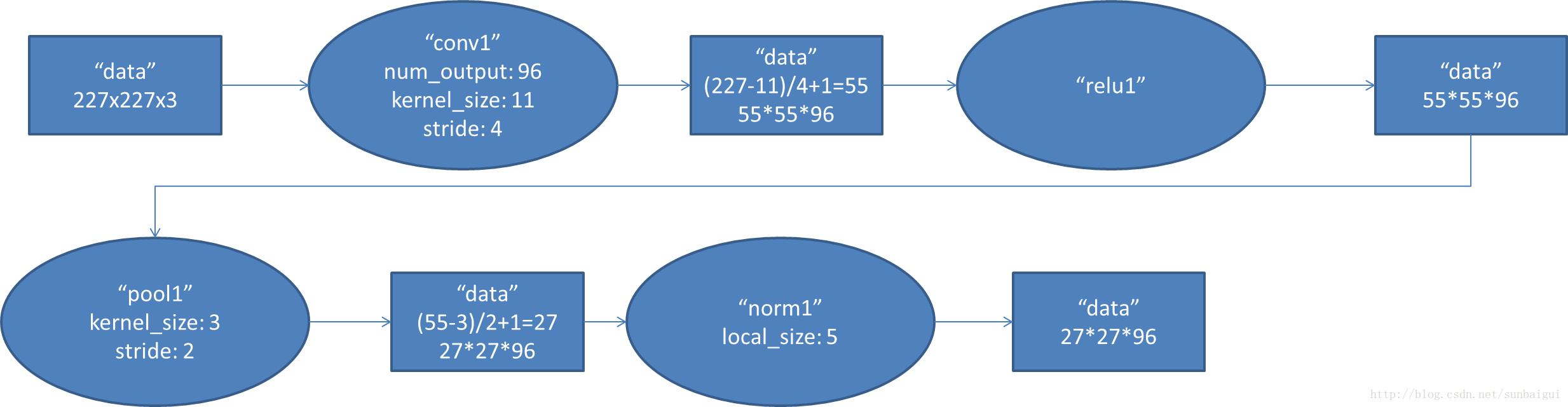
2. conv2阶段DFD(data flow diagram):
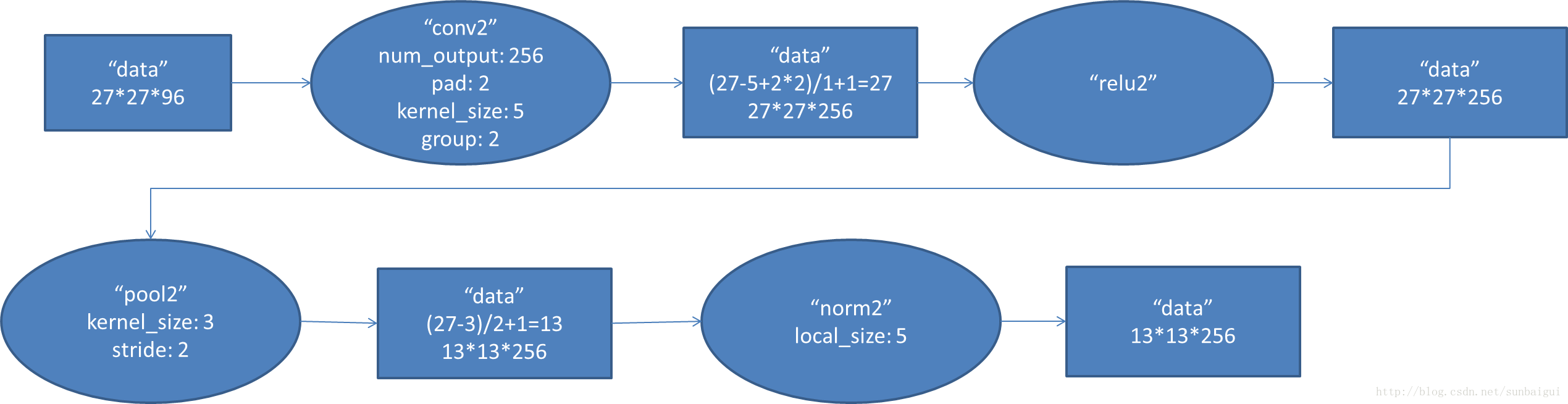
3. conv3阶段DFD(data flow diagram):

4. conv4阶段DFD(data flow diagram):

5. conv5阶段DFD(data flow diagram):
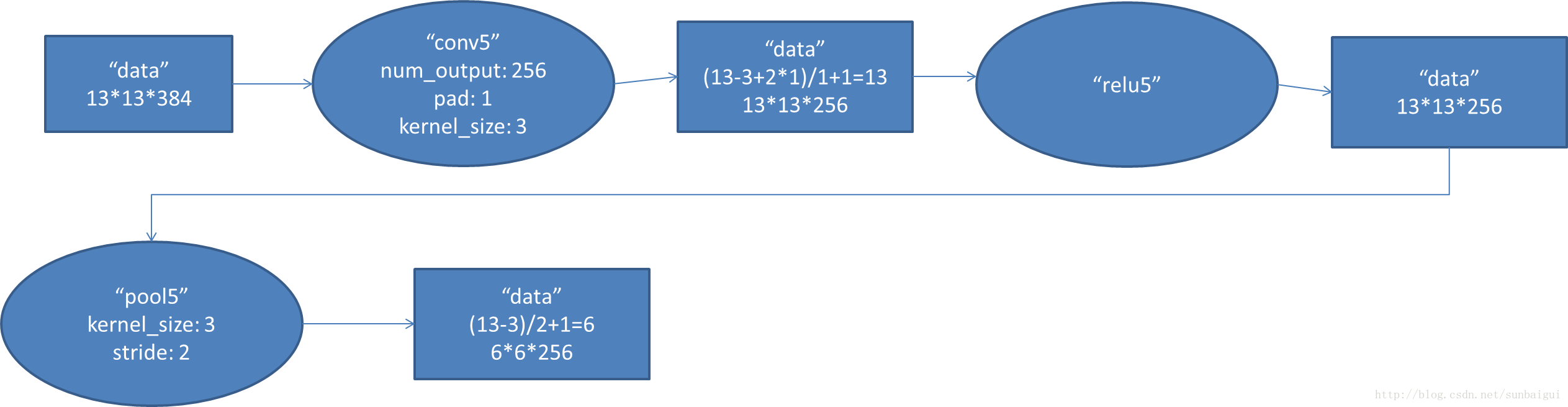
6. fc6阶段DFD(data flow diagram):
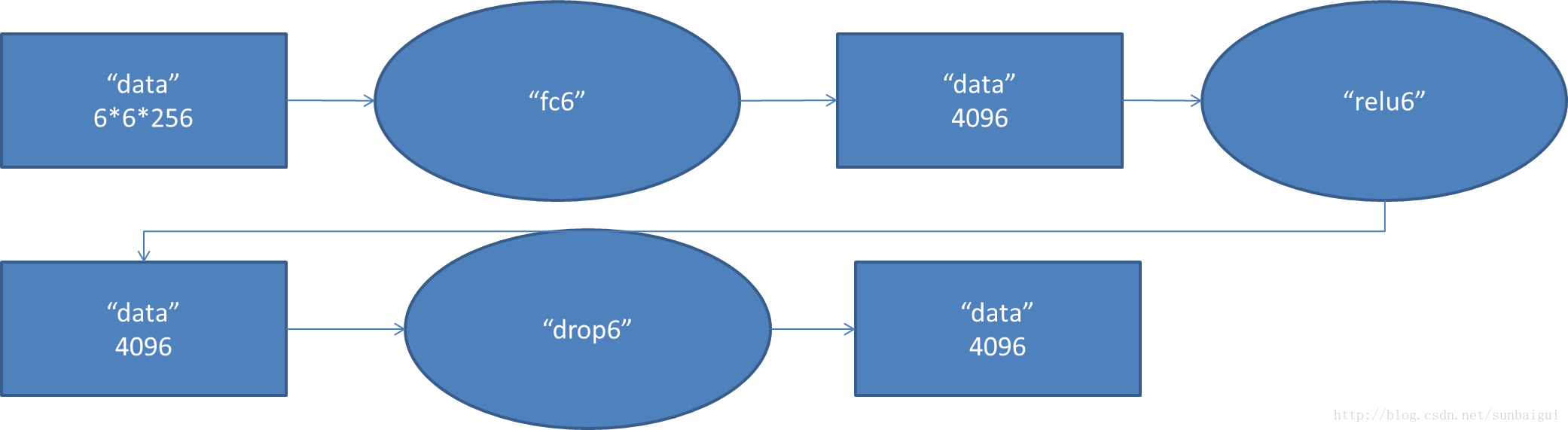
7. fc7阶段DFD(data flow diagram):
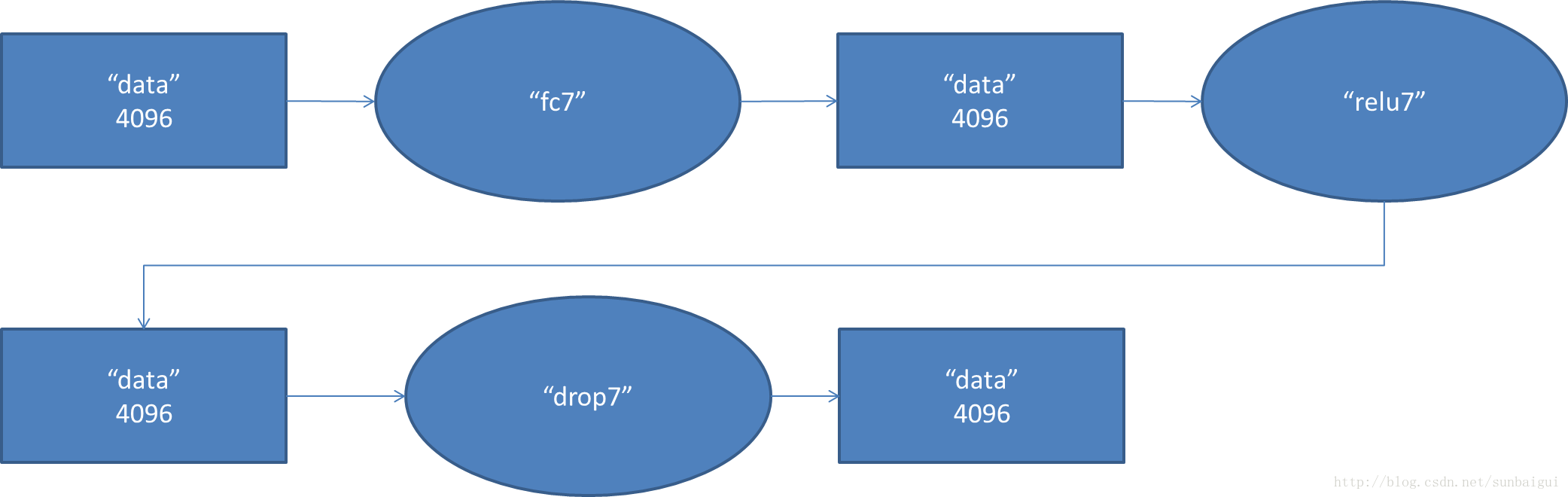
8. fc8阶段DFD(data flow diagram):

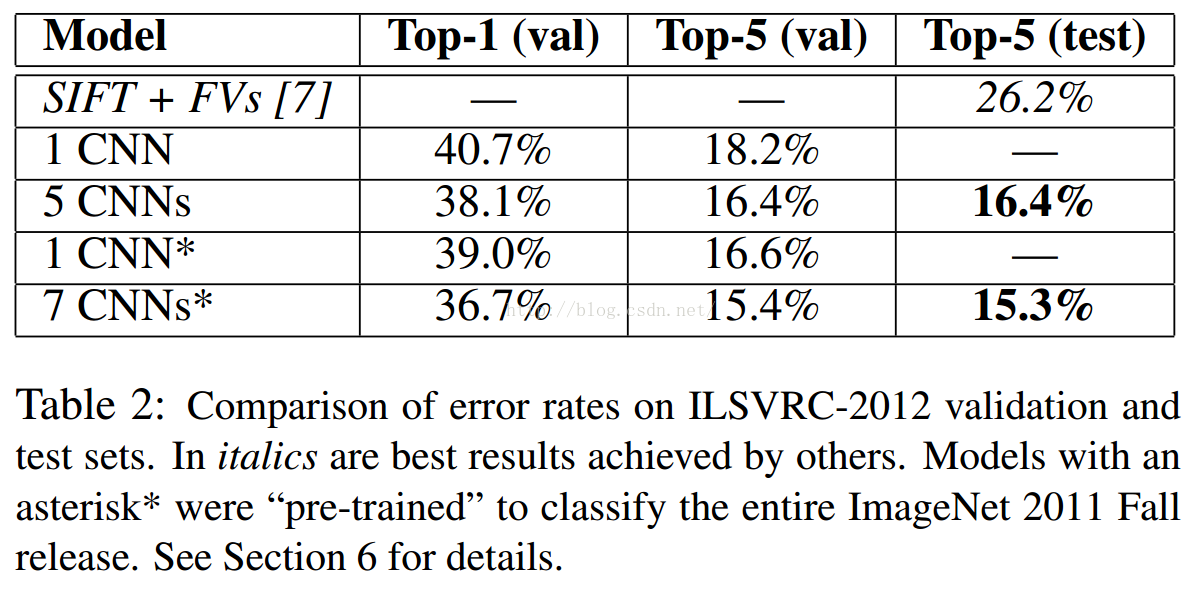
一、先介绍一下大牛的结果,在imagenet上的图像分类challenge上Alex提出的alexnet网络结构模型赢得了2012届的冠军。在ILSVRC2010中,top-1和top-5的成绩分别为37.5%和17.0%;这个大的网络包含6千万个参数和65万的神经元;由5个卷基层,3个全连接层和最终分类器构成。利用了RELU,dropout,data augmentation等多种防止过拟合的技术
二、长话短说,先说一下这篇文章用的数据,
ILSVRC使用ImageNet的一个子集,一共1000个类别,每个类别包含大约1000张图片;训练集120万张,验证集5万张,15万张测试集。输入的图像(size 256*256)随机提取224*224的图像集合,输入的data(原图中224是处理过的,crop后的image实际上是227*227的)【crop 为将图片进行四个边界crop+中心crop】
三、ReLU非线性激活函数部分,详细说明见http://blog.csdn.net/langb2014/article/details/48154539
四、关于文中GPU方面,作者把网络一分为二,分配到2个GPU上,通过并行计算来解决。文中也没有详细说明是GPU机理,我们看一下模型并行的来源:Deep CNNs网络只在特定层(如输入层、全连接层)与其他层有全面的连接,而其他较为独立的直线连接关系即可作为模型的可并行部分。将模型的可并行部分拆分到多个GPU上,同时利用多个GPU的计算能力各执行子模型的计算,可以大大加快模型的单次前向-后向训练时间。DeepCNNs网络的层次模型实际上是一张有向无环图(DAG图),分配到每个模型并行Worker上的层集合,是有向无环图的拓扑排序子集,所有子集组成整个网络的1组模型。卷积神经网络CNN的模型并行和数据并行框架的结构(如下图所示):

CNN模型并行和数据并行框架对GPU卡分组,组内两个GPU卡做模型并行,组间做数据并行。如上图所示,4个GPU卡分成Worker Group 0和1。组内两卡各持有CNN模型的一部分,称为partition,协作完成单个模型的训练。模型并行中,卡间数据传输通过引入Transfer Layer透明的完成。组间数据并行按同步随机梯度下降进行训练,并采用精巧的拓扑完成参数交换,但注意只有各组内属于同一个partition的数据各自交换,即图中GPU0和GPU2、GPU1和GPU3分别进行参数交换。引入数据并行和模型并行后,从磁盘读取训练数据,训练数据预处理,CNN训练分别占用磁盘、CPU、GPU资源,且均耗时较大。因此,我们引入流水线,使得磁盘、CPU、GPU资源可以同时得到利用,提升整体性能。alexnet只是用了两个GPU进行计算,也就是一个worker group,在3,6,7层进行cross。
五、Local Response Normalization(局部归一化)
局部归一化公式:
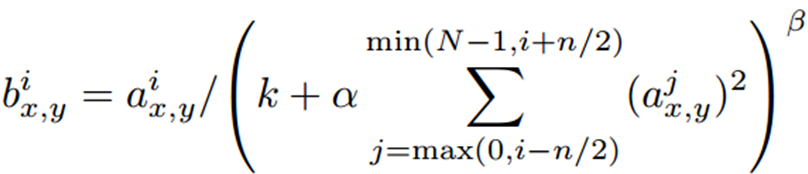
(其中a是每一个神经元的激活,n是在同一个位置上临近的kernel map的数目,N是可kernel的总数目,k,alpha,beta都是预设的一些hyper-parameters,其中k=2,n=5,alpha = 1*e-4,beta = 0.75)
选取临近的n个特征图,在特征图的同一个空间位置(x,y),依次平方,然后求和,在乘以alpha,在加上K。这个局部归一化方式“what is the best multi-stage architecture for Object Recognition”中的局部归一化方法不同;本文的归一化只是多个特征图同一个位置上的归一化,属于特征图之间的局部归一化(属于纵向归一化),作者命名为亮度归一化;“what……”论文中在特征图之间基础上还有同一特征图内邻域位置像素的归一化(横向,纵向归一化结合);“what……”归一化方法计算复杂,但是没有本文中alpha,k,n等参数,本文通过交叉验证来确定这三个参数;此外,本文的归一化方法没有减去均值,感觉是因为ReLU只对正值部分产生学习,如果减去均值会丢失掉很多信息。(第五部分,http://blog.csdn.net/whiteinblue/article/details/43202399)
六、重叠pooling部分,pooling区域为z*z=3*3,间隔距离为s=2.对比z=2,s=2的无重叠方式;使用重叠pooling,不容易过拟合。
七、文中提到两个介绍过拟合的策略:
-
结合图像水平反转来增加样本达到数据增益
-
调整RGB像素值,
RGB像素的3*3相关系数矩阵M,对M求特征值lamda(i)和特征向量p(i),alpha(i)是服从高斯分布,标准差为0.1的随机变量,这个不是很明白。
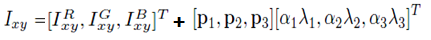
八、dropout部分与CNN机制一样,关于Dropout,没有任何数学解释(Improving neural networks by preventing co-adaptation of feature detectors),Hintion的直观解释和理由如下:
1. 由于每次用输入网络的样本进行权值更新时,隐含节点都是以一定概率随机出现,因此不能保证每2个隐含节点每次都同时出现,这样权值的更新不再依赖于有固定关系隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况。
2. 可以将dropout看作是模型平均的一种。对于每次输入到网络中的样本(可能是一个样本,也可能是一个batch的样本),其对应的网络结构都是不同的,但所有的这些不同的网络结构又同时share隐含节点的权值。这样不同的样本就对应不同的模型,是bagging的一种极端情况。个人感觉这个解释稍微靠谱些,和bagging,boosting理论有点像,但又不完全相同。
3. native bayes是dropout的一个特例。Native bayes有个错误的前提,即假设各个特征之间相互独立,这样在训练样本比较少的情况下,单独对每个特征进行学习,测试时将所有的特征都相乘,且在实际应用时效果还不错。而Droput每次不是训练一个特征,而是一部分隐含层特征。
4. 还有一个比较有意思的解释是,Dropout类似于性别在生物进化中的角色,物种为了使适应不断变化的环境,性别的出现有效的阻止了过拟合,即避免环境改变时物种可能面临的灭亡。
九、细节方面,使用带动量项的梯度下降法SGD(前一篇的介绍http://blog.csdn.net/langb2014/article/details/48262303)
批量D=128;动量项v=0.9,权值削减weightdecay wd=0.0005, W服从均值为0,标准差为0.01的高斯分布。、
偏置项:第2,4,5卷基层和两个全连接层的b=1(促进最初阶段ReLU的学习);其它层b=0。
学习率:初始为0.01,当验证集停止提高时,手动缩减学习率(除以10)
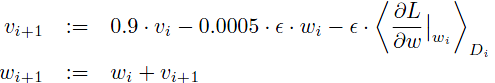
十、结论:
十一、Output_size 与 Input_size/ Kernel_size / Padding / Stride 关系
十二、关于参数设置,96是作者经验值。。。如何生成256个map features这个是一个排列组合问题,384等这些都是经验值,4096(Conv5的256*256*13*13, 先卷积再pooling为 (13-3+2)/3=4, 变成 256*(256*4*4),压扁成为256*4096!)其他的均可以推导出来了,就不详细说明了。
**************************************************************************************************************************************************************************************************
最后网络中的各种layer的operation解释可以参考http://caffe.berkeleyvision.org/tutorial/layers.html,该模型参数大概6kw+。
在DL开源实现caffe的model样例中,也给出了alexnet结构,具体网络配置文件如下https://github.com/BVLC/caffe/blob/master/models/bvlc_reference_caffenet/train_val.prototxt














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









