






SVM是一系列用于分类、回归、异常值检查的有监督学习方法。
SVM的优势:
- 在高维空间有效。
- 当样本特征维数比样本数大的时候依然有效。
- 在决策函数中只使用一部分训练样本(支持向量),所以内存使用效率很高。
- 多种使用方式:决策函数中可以指定不同的核函数,虽然提供了常用的核函数,但是也可以指定定制的核函数。
SVM的劣势:
- 如果特征的数目远远大于样本数,这种方法的表现可能很差。
- SVMs不会直接提供概率估计,这可以通过5折交叉验证计算。(参考得分和概率部分)
1.4.1.分类
SVC,NuSVC和LinearSVC可以对数据集进行多分类。
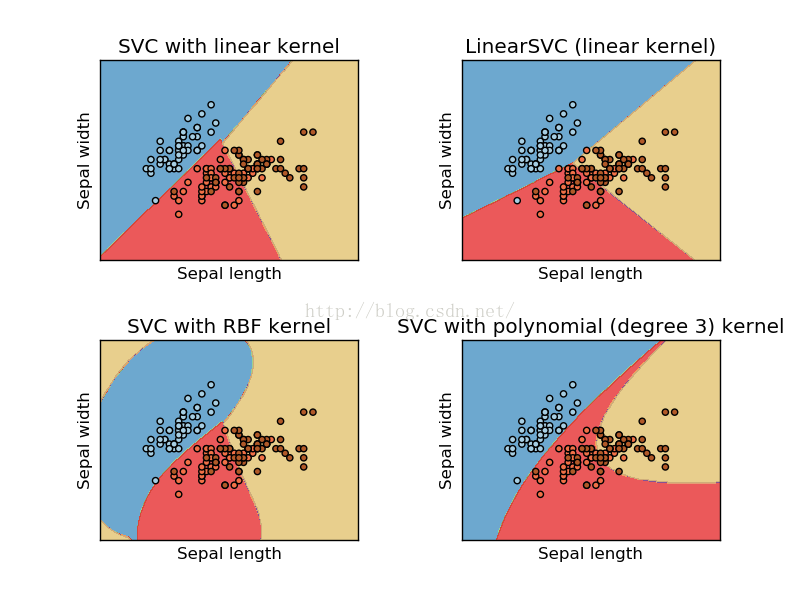
SVC和NuSVC是类似的方法,但是输入参数略有不同,并且有不同的数学描述(参考数学公式部分)。但是LinearSVC是支持向量分类针对线性核函数情况的另一种实现。需要注意的是因为LinearSVC的假定是线性的,所以不需要指定核函数,它也缺少了SVC和NuSVC的一些成员,比如support_。
1.4.1.1.多分类
SVC和NuSVC使用“one-against-one”的方法(Knerr et al., 1990)来进行多分类。如果n_class是类别的数目,那么需要构建n_class * (n_class - 1) / 2个分类器,每个分类器从两个类别的数据训练。为了提供一个与其他分类器兼容的接口,通过decision_function_shape这个参数合并所有的“one-against-one”分类器结果成一个shape(n_samples, n_classes)的决策函数。
LinearSVC使用“one-vs-the-rest”的多分类策略,因此只需要训练n_class个模型。如果只有两类,那么只需要训练一个模型:
1.4.2.回归
支持向量分类理论可以被扩展到解决回归问题。这种理论被称为支持向量回归。
(未完结)














 3451
3451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









