







1.词法分析器的主要工作
(1)从源程序文件中读入字符。
( 2)统计行数和列数用于错误单词的定位。
( 3)删除空格类字符,包括回车、制表符空格。
( 4)按拼写单词,并用(内码,属性)二元式表示。 (属性值——token 的机内表示)
( 5)如果发现错误则报告出错
( 6)根据需要是否填写标识符表供以后各阶段使用
2.单词的基本分类
- 关键字:由程序语言定义的具有固定意义的标识符。也称为保留字例如if、 for、 while、 printf ; 单词种别码为 1。
- 标识符:用以表示各种名字,如变量名、数组名、函数名;
- 常数: 任何数值常数。如 125, 1,0.5,3.1416;
- 运算符: +、 -、 *、 /;
- 关系运算符: <、 <=、 = 、 >、 >=、 <>;
- 分界符: ;、,、(、)、 [、 ];
3.有限状态机
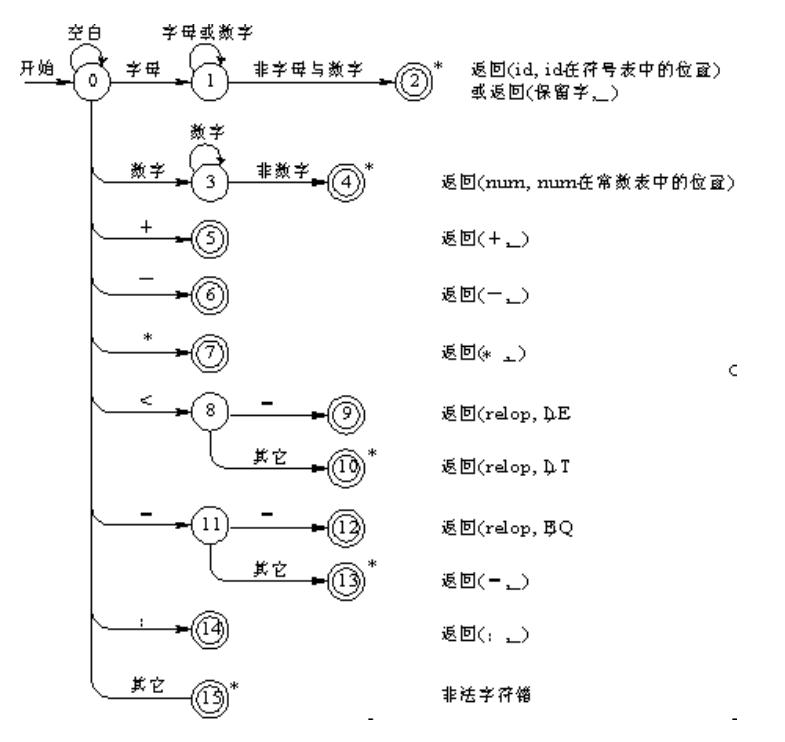
4.程序流程图
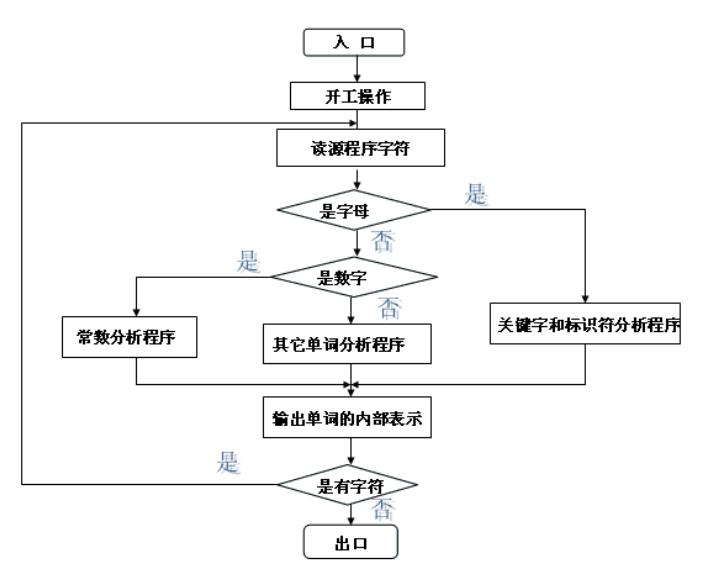
5.以下为完整代码
//compiler
#include<iostream>
#include<ctype.h>
#include<cstring>
#include<cstdio>
using namespace std;
const char *k[12] = {"for","if","else","do","while","return","int","char","short","float","double","string"};
char instring[80];
char outtoken[10];
//char id[10] = {'\0'};
//int ci[10];
int m;
//int num = 0;
int t;
int p;
char ch;
int row = 1,col = 0;
int j = 0;
void scan()
{
ch = instring[p ++];
m = -1;
for(int i = 0; i < 10; i ++)
outtoken[i] = '\0';
if(ch == ' ')ch = instring[p ++];
if(ch == '\n'){
ch = instring[p ++];
row = row + 1;
col = 0;
}
if(isalpha(ch)){
while(isalpha(ch)||isdigit(ch)){
outtoken[++ m] = ch;
ch = instring[p ++];
}
outtoken[++ m] = '\0';
ch = instring[p --];
int flag = 0;
for(int n = 0; n < 12; n++){
if(strcmp(outtoken,k[n]) == 0){
t = 1;
flag = 1;
break;
}
}
if(flag == 0){
//strcpy(id,outtoken);
t = 6;
}
col = col + 1;
}
else if(isdigit(ch)){
while(isdigit(ch) || ch == '.'){
m = m + 1;
outtoken[m] = ch;
//num = num * 10 + ch - '0';
ch = instring[p ++];
}
//cout<<m<<endl;当时写出这个语句,是为了检测m的值,以判断程序是否有bug
for(int num = 0; num < m; num ++){
if(outtoken[num] == '.')
j = j + 1;//判断是否有多个“.”,如果有多个就说明该数字是错误的,如:1.2.2
}
int tag = 0;//设立标志
if(j > 1){
outtoken[++ m] = '\0';
ch = instring[p --];
t = -1;//t=-1,报错。
tag = 1;//tag置1
}
if(isalpha(ch)){
outtoken[++ m] = ch;
outtoken[++ m] = '\0';
t = -1;
}
else if(tag == 0){//执行了第一个if语句,就一定不会执行这句。
outtoken[++ m] = '\0';
ch = instring[p --];
t = 5;
}
col = col + 1;
}
else{
switch(ch){
case '+':
outtoken[++ m] = ch;
ch = instring[p ++];
if(ch == '+')
outtoken[++ m] = ch;
else
ch = instring[p --];
case '-':
case '*': case '/':t = 3;col = col + 1;break;
case ',': case ';':
case '(': case ')':
case '{': case '}':
case '[': case ']':t = 2;outtoken[0] = ch;col = col + 1;break;
case '#':
t = 0;outtoken[++ m] = ch;break;
case '=':
outtoken[++ m] = ch;
ch = instring[p ++];
if(ch == '='){
outtoken[++ m] = ch;
t = 4;
}
else{
ch = instring[p --];
t = 4;
}
col = col + 1;
break;
case '<':
outtoken[++ m] = ch;
ch = instring[p ++];
if(ch == '='||ch == '>'){
outtoken[++ m] = ch;
t = 4;
}
else{
t = 4;
ch = instring [p --];
}
col = col + 1;
break;
case '>':
outtoken[++ m] = ch;
ch = instring[p ++];
if(ch == '='){
outtoken[++ m] = ch;
t = 4;
}
else{
t = 4;
ch = instring[p --];
}
col = col + 1;
break;
default:
outtoken[0] = ch;
t = -1;
col = col + 1;
break;
}
}
}
int main()
{
cout<<"请输入要进行词法分析的代码块(C++):\n";
p = -1;
do{
ch = getchar();
instring[p ++] = ch;
}while(ch != '#');
p = -1;
//ch = instring[p ];
cout<<"单词\t二元序列\t类型\t\t位置(行,列)"<<endl<<endl;
do{
scan();
switch(t){
case 1:
cout<<outtoken<<"\t"<<"("<<1<<","
<<outtoken<<")\t\t"<<"关键字\t\t"
<<"("<<row<<","<<col<<")"<<endl;
break;
case 2:
cout<<outtoken<<"\t"<<"("<<2<<","
<<outtoken<<")\t\t"<<"分界符\t\t"
<<"("<<row<<","<<col<<")"<<endl;
break;
case 3:
cout<<outtoken<<"\t"<<"("<<3<<","
<<outtoken<<")\t\t"<<"算术运算符\t"
<<"("<<row<<","<<col<<")"<<endl;
break;
case 4:
cout<<outtoken<<"\t"<<"("<<4<<","
<<outtoken<<")\t\t"<<"关系运算符\t"
<<"("<<row<<","<<col<<")"<<endl;
break;
case 5:
cout<<outtoken<<"\t"<<"("<<5<<","
<<outtoken<<")\t\t"<<"常量\t\t"
<<"("<<row<<","<<col<<")"<<endl;
break;
case 6:
cout<<outtoken<<"\t"<<"("<<6<<","
<<outtoken<<")\t\t"<<"标识符\t\t"
<<"("<<row<<","<<col<<")"<<endl;
break;
case -1:
cout<<outtoken<<"\t\t\t"<<"Error!\t\t"
<<"("<<row<<","<<col<<")"<<endl;
case 0:
break;
}
}while(t != 0);
return 0;
}
6.运行结果
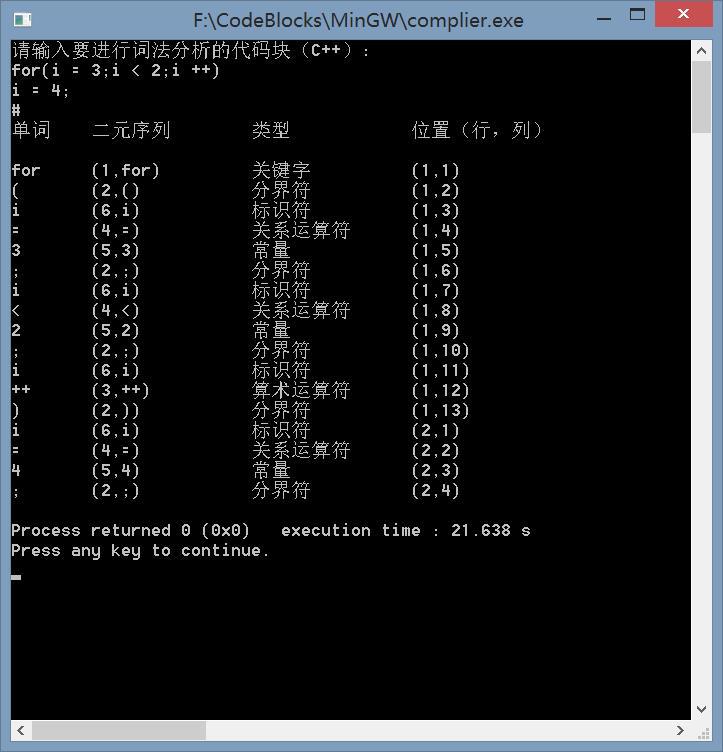
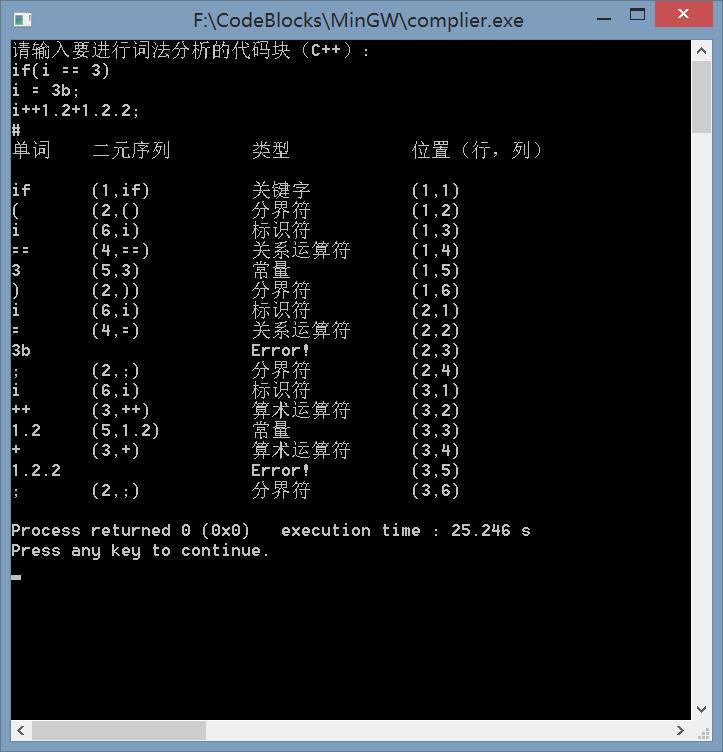
7.说明
一开始本来不想贴代码的,毕竟太长了,但不贴代码,内容好像又太少了。还是说一下,本代码仅供交流、参考之用,建议不要复制粘贴。词法分析器的整个逻辑相对还是很清楚、简单的。稍微花点时间,并不难写出来。
顺便写下自己做这个实验时发现的自己一直存在的错误:
多个if和else if以及else语句同时出现时会出现二义性。
如如下代码片段:
if(condition1){...}
if(condition2){...}
else {...}
在此程序中,执行了第一个if语句后,若第二个if语句也执行,则不会出错;但若第二个 if不执行,那么就会执行else语句,此时else语句里的代码会和第一个if语句里的代码产生冲突。这个问题可以通过设置一个标志tag得到解决:先给tag赋予一个初值,若执行了第一个if语句,则修改tag的值,再将tag的初值作为第二个if的判断条件。
即改为:
int tag = 0;
if(condition1){
…
tag = 1;
}
if(condition2){
…
}
else if(tag == 0){
…
}
这样的话就可以有效避免冲突了。这个技巧还是挺有用的,哈哈。















 2372
2372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









