







storm集群搭建
storm核心组件
storm编程模型
storm task并发度
storm 消息容错
storm 通信机制
storm 与zk交互
strom 流式计算的一般架构
kfaka集群搭建
kfaka生产集群的原理/分区
kafka消费者的负载均衡
kafka消费者的负载均衡–kafkaspout
kafka broker核心机制(topic 分片 文件存储机制 )
flume用来获取数据 kafka用来临时保存数据 storm用来计算数据 redis是个内存数据库,用来保存数据。
Data Source:
Spout:从外部数据源获取数据(一条一条,string json javabean序列化 xml),在一个topology中获取数据源的组件
Bolt:处理Spout发送过来数据(Bolt如何处理是根据业务步骤来 )
业务逻辑处理节点,可以有多个
Topology:Storm中运行的一个应用程序的名称(拓扑)
tuple1:消息发送的最小单元,对象有个list
StreamGroup:数据分组策略,即数据流怎么分区
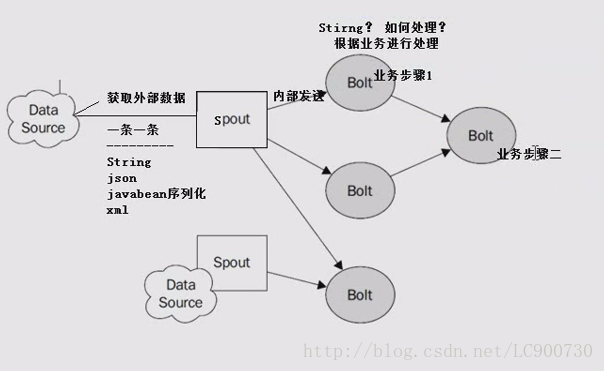
一个storm程序可以获取多个数据源。
每一个topology都有一个数据源。
storm1的的spout不可以发送到storm2中的spout
分发策略
Shuffle Grouping随机分组
- 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
fields Grouping按照字段分组
- 比如按照userid分组,同样userid的tuple被分到相同的bolts中的一个task,不同的userid被分到不同的bolts里的tasks
All Grouping 广播发送
- 对于每一个tuple,所有的bolts都会收到。
Non Grouping 不分组
- stream不关心到底谁会收到它的tuple。目前这种分组和shuffle grouping是一样的效果,有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行
Direct Grouping 直接分组
- 消息发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。
Local or shuffle grouping
- 如果目标bolt有一个或者多个task在一个工作进程中,tuple将会被随机发送给这些tasks。否则和普通shuffle Grouping行为一致。














 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









