






12月23-24日

正文共7865个字,27张图,预计阅读时间:20分钟。
在前言中,已经提到经常使用深度学习的领域就是模式识别。编程初学者都是从打印“Hello World”开始,深度学习中我们则是从识别手写数字开始。
本章中,我会讲解如何在TensorFlow中一步步建立单层神经网络,这个建立的神经网络用来识别手写数字,它是基于TensorFlow官方新手指南中的一个例子改变而来。
根据本书的风格,在本例子中会简化一些概念与理论证明。
如果读者在读完本章后,有兴趣研究例子中相关的理论概念,建议读者去阅读神经网络与深度学习一书,该书同样可在网上获得,该书阐述了本例子中的一些深度理论概念。
MNIST data-set由一些黑白照片集合组成,每张照片包含手写的数字。集合中60000张照片用来训练模型,10000张照片用来测试模型。MNIST data-set可通过网络在MNIST数据库中获得。
对于刚开始基于真实样例学习模式识别确没有时间进行数据预处理或归一化的同学,这个数据集十分理想,因为数据预处理与归一化是非常重要且花时间的两个步骤。
这些黑白照片已经规则化成20*20像素,并保留了宽高比。对于本例子,我们发现由于归一化算法(图片的分辨率降为其中最低水平之一)中使用了抗锯齿,图片中包含了很多灰色像素。通过计算质心,并将照片移至28*28像素方框的正中间。照片如下图所示:
本例子中使用的学习算法同样为监督学习,照片已经用它们代表的数据进行标注。这是一种非常常见机器学习算法.
我们首先收集很大的包含数字的照片集合,每一张照片用它代表的数字进行标注。在训练过程中,模型输入一张照片,输出得分数组,每一个得分代表了一个分类。我们希望想要的那个分类在所有分类中拥有最大的得分,但在训练模型之前这是不太可能发生的。
通过计算一个对象函数来度量错误值,这个错误值代表了输出得分与目标模式得分的差别。模型会修改内部的可调参数(也叫权重)来降低这个错误值。在一个典型的深度学习系统中,可能会有成百上千的可调参数,成百上千的标注数据为训练模型。我们会通过一个较小的例子来帮助讲解这种类型的模型是如何工作的。
为方便下载数据,你可以使用input_data.py脚本,该文件也已放在github上。当在TensorFlow中编程实现神经网络时,可直接通过这个脚本下载数据到当前目录下。在你的应用程序中,只需要导入并调用如下代码:

当执行完这两行命令后,mnist.train会包含了全部的训练数据,mnist.test包含了全部的测试数据集。正如我之前所说的,每一个元素都由一张照片组成,用”xs”来表示,它的标注用“ys”表示,这可以很方便的表示处理代码。请记住,所有数据集,训练集与测试集都包含了“xs”与“ys”;同时,mnist.train.images表示训练照片,mnist.train.labels表示训练标签。
正如之前所说,图像被格式成28*28像素,并可表示成一个数值矩阵。例如,数字1的照片可表示为:
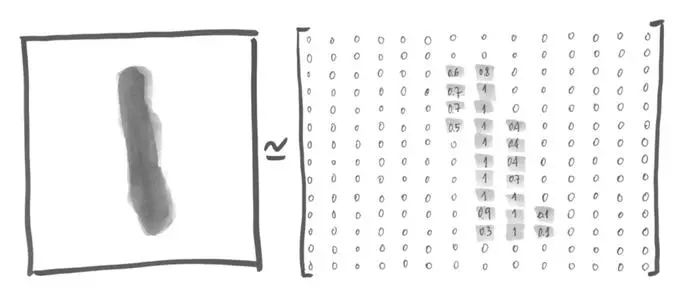
每一个位置代表了每一个像素灰的程序,取值0到1。这个矩阵可表示为一个28*28=784的数组。实际上,照片已经变换成784维向量空间中一系列的点。需要说明的是,当我们将结构降到2维后,我们会失去部分信息,对于一些计算图像算法,这会带来不利影响,但在本例子中使用的算法来说,这没有任何影响。
总结一下,我们有了mnitst.train.images 2D tensor,当调用get_shape()时显示的结果为:
TensorShape([Dimension(60000),Dimension(784)])
第一维度索引了每一张照片,第二维索引了照片中每一像素。Tensor中每一元素是该像素强度值,该值介于0到1之间。
标签都是数字0到9的格式,表明图片代表哪一个数字。本例子中,每个标签表示为10个元素的向量,图片代表的数字相应的位置为1,其余位置为0。所以mnist.train.labelses是一个shape为([Dimension(6000),Dimension(10)]的tensor。
虽然本书不会主要讲神经网络的理论概念,但是简短直观的介绍神经网络如何学习训练数据会帮助读者理解神经网络做了什么。已经非常了解神经网络理论,只是如何学习使用TensorFlow的同学,可以跳过本小节。
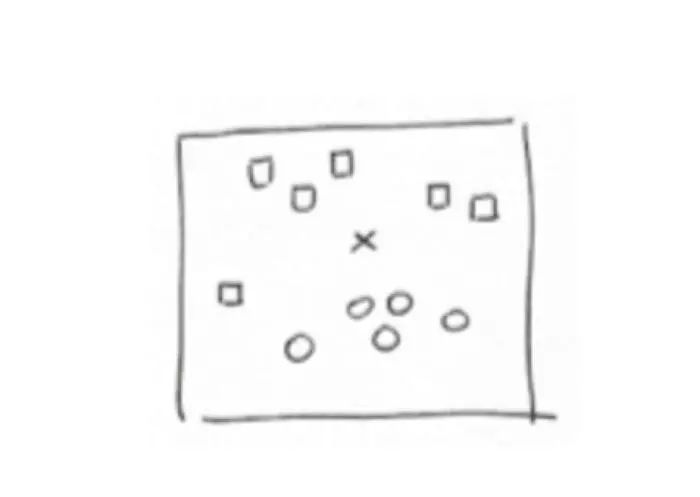
我们可以看一个简单但又很有代表性的例子来说明神经元如何学习。假设一个平面中有一个点的集合,分别被标记为“square”与“circle”。给一个新的点“X”,我们想知道这新点会被标记为哪个标签:
一个通用的方法是画一条直线作为分类器,将点分成两组:
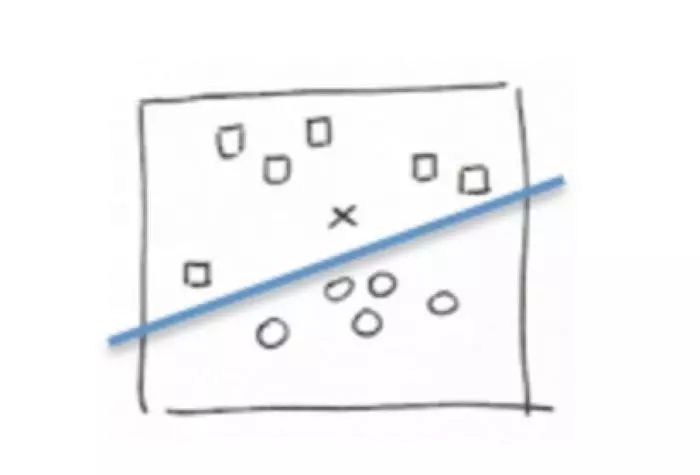
在这种情形下,输入数据表示为shape为(x,y)的vectors,代表了2维空间中的坐标,我们的函数返回0或1(直线之上或之下)来代表将该点分类为“square”还是“circle”。通过线性回归那一小节学到的,从数学上,这条直线(分类器)可表示为y=W*x+b。
一般来说,神经元一定要学到一个权重W(与输入数据X有同样的维度)与偏移b(神经网络中叫bias)来学会将如何分类这些值。根据W和b,神经元会对输入计算一个加权和,并加上偏移b;最后神经元会应用激活非线性函数来产生结果0或1。神经元的函数可形式化表示为:
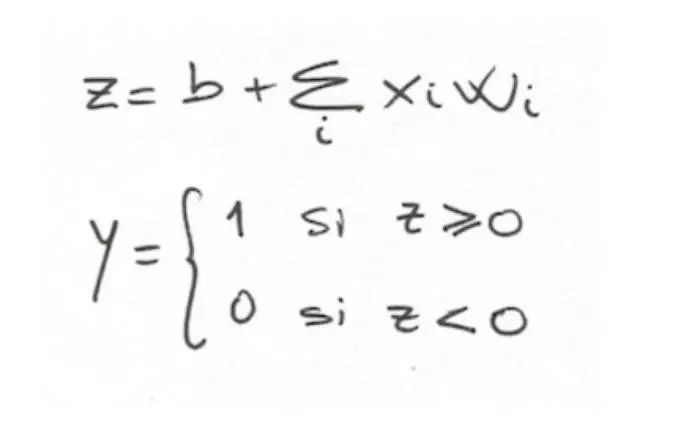
为神经元定义了这个函数后,我们想了解神经元是如何通过这些标注数据(squares与circles)来学得参数W和b,并用来分类新点X。
第一个尝试的方法类似之前提到的线性回归,对神经元输入已知的标注数据,并比较计算结果与真实结果。在迭代时,通过调整参数W和b来最小化错误值,正像第二章中线性回归所做的那样。
一旦有了参数W和b后,就可以计算加权和,现在我们需要一个函数来将结果转化成0或1。有几个激活函数可以做到这样,在本例子中,我们使用一个很流行的函数叫sigmoid来返回一个0到1之间的真实值:
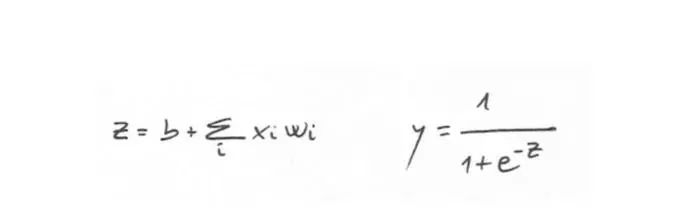
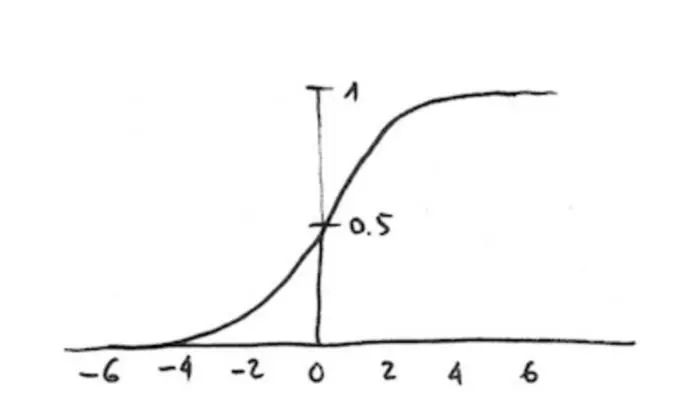
通过公式我们可以看到,它会返回一个非常接近0或1的值。如果输入z是正值且足够大,e的-z次幂为0,然后y为1。如果输入z是负值且足够大,e的-z次幂为无穷大,分母为无穷大,然后y为0。如果用图表画出该函数,大约如下图所示:
到现在为止我们已经讲解了如何描述一个神经元,但神经网络是由很多神经元组成,神经元间以不同方式连接并使用不同的激活函数。本书范围内不会讨论神经网络的很多扩展细节,但向你保证,神经网络是非常有趣的。
需要提一下,现在有具体的神经网络实现方式(第五章中会使用),神经元以层的方式来组织,输入层接受输入,最顶层(输出层)产生响应结果。神经网络可以有很多中间层,叫隐藏层。用图画出神经网络如下所示:

神经网络中,某一层的神经元与前一层的神经元通信来获得该层的输入信息,然后将结果输出给下一层的神经元。
正如之前所说的,除了sigmoid之外,还有很多的激活函数,每个激活函数都有不同的属性。例如,如果我们在输出层想将数据分到多于2类中,需要使用softmax激活函数,是sigmoid函数的通用版。Softmax计算属于每一个分类的概率,概率总和为1,最有可能的结果是概率最大的那一个。
还记的我们的需要解决的问题是,输入一张图片,得到这张图片属于某一数字的概率。例如,我们的模型可以预测一张图片为9的概率为80%,为8的概率为5%,同样其它数字的概率也很低。识别手写数字有一定的不确定性,我们做不到100%的正确性来识别数字。在本例子中,概率分布使得我们可以明白有多大的正确性来预测。
所以,我们会得到向量,它包含了不同输出标签的概率分布,它们之间互斥。也就是说,一个向量带有10个概率值,每一个概率值对应了数字0到9,所有概率之和为1。
如之前所说,我们通过在输出层使用softmax激活函数来达到这个目的。神经元中softmax的输出结果依赖于本层中其它神经元的输出,因为必须保证输出结果之和为1。
Softmax函数有两个主要步骤:1.计算一张图片属于某一标签的“证据”;2.将“证据”转换成属于每一个可能标签的概率。
属于某类的“证据”
如何度量一张图片属于某一分类/标签的证据?一个常用的方法是计算像素强度的加权和。像素的权重为负说明像素有很高的强度表明不属于该类,为正时表明属于该类。
接下来看一个图形例子:假如一个对于数字0学习完的模型(稍后我们会看到模型是如何得到的)。这次,我们将模型定义为包含一些信息来推断一个数字是否属于某一分类。在本例子中,我们选择一个如下所示的模型,红色(或b/n版本中的亮灰色)代表负样本(这些像素不属于0),蓝色(或b/n版本中的深灰)代表了正样本:
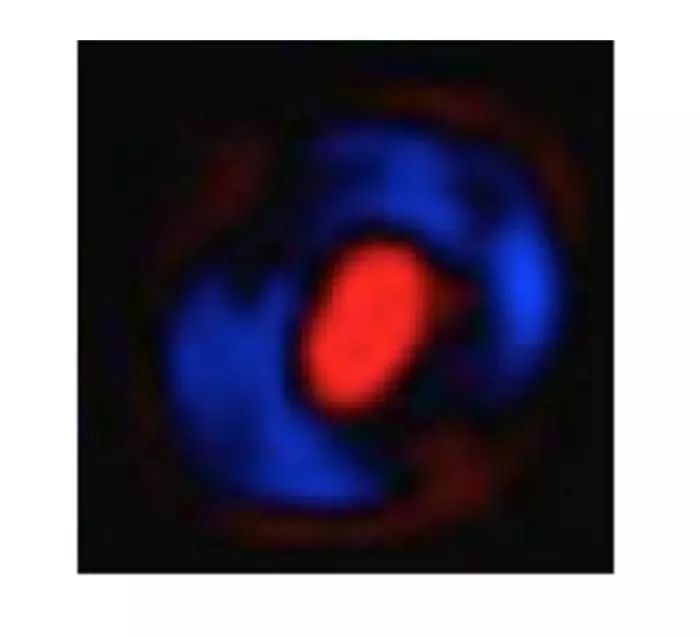
想像在28*28像素的一张白纸下画一个0。一般来说,0会被画在蓝色区域(我们在20*20画的区域周边预留一些空间,用来将它居中)。
非常明显当我们画的穿过红色区域时,很有可能我们画的不是0。所以,穿过蓝色区域对像素加权,红色区域会像素惩罚的机制是合理的。
现在来看3:很明显模型中对于0的红色区域会惩罚它属于0的概率。但是如果相关模型是哪下所示,一般生成3的像素会在蓝色区域;同时画0时也会进入到红色区域。
希望读者通过这两个例子能理解这种方法是如何来预估哪个数字表示了这些图。
下面的这些图片显示了从MNIST数据集中学到的10个不同标签/分类。记住红色(亮灰)代表负权重,蓝色(暗灰)代表正权重:

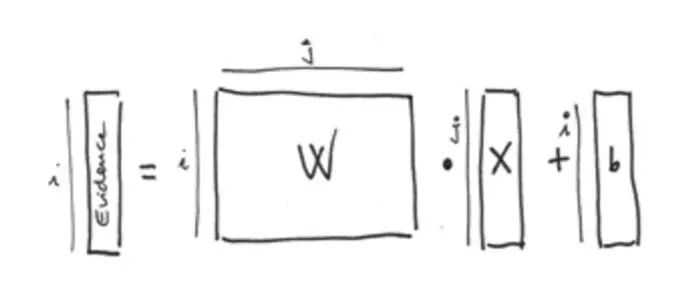
用公式表达的话,输入X属于类别i的证据可表示为:
 i代表分类(本例子中为0到9),j是输入照片求和的索引,wi代表了前面描述的权重。
i代表分类(本例子中为0到9),j是输入照片求和的索引,wi代表了前面描述的权重。
一般来说,模型中也会包含一个额外的参数,表示为bias,用来增加一些不确定性。本例子中,公式如下所示:

对于第一个i(0到9),我们有一个784元素的矩阵Wi,每一个元素j与输入照片784元素中相应位置的元素相乘,然后加上bi。图形化表示为:
之前提到第二步包含了计算概率。我们用softmax函数将“证据”求和转变成可预测的概率,并用y来表示:
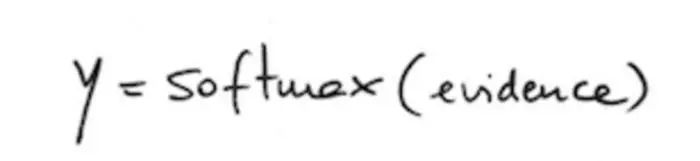
输出的向量一定是一个概率函数且和为1。为归一化每一个元素,softmax函数对每一个输入求指数,然后如下来归一化:
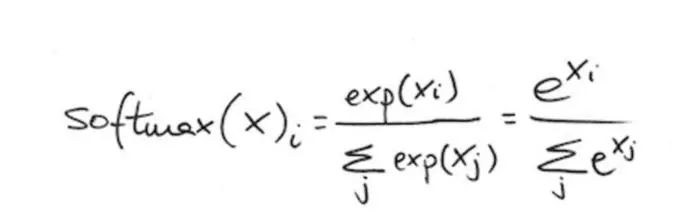
采用指数的效果是在权重上进行乘法的效果。当支持某一类的“证据”很小时,该类的支持会被之前的权重减掉一小部分。更进一步,softmax函数归一化权重,并使得其和为1,同时创建一个概率分布。
该函数比较有意思的一点是好的预测输出结果中一个值接近1,其余的接近0;弱的预测中,一些标签可能是相似的值。
ETensorFlow中编程实现
在简要介绍了算法是如何识别数字后,我们可以在TensorFlow中实现它。先快速了解下tensor如何存储我们的数据和模型参数。基于此,下面的范式描述了相关数据与它闪间的关系(帮助读者容易回忆起问题中的每一个部分):
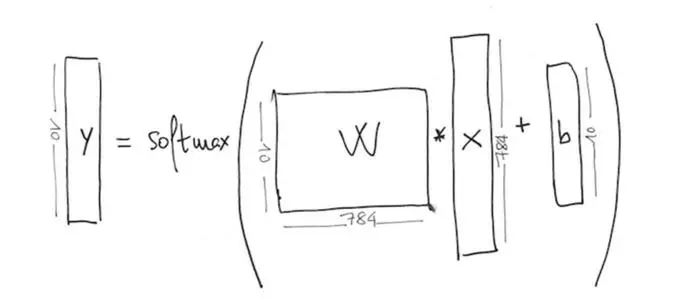
首先创建两个变量来保存权重W和bias b:

这两个变量通过调用tf.Variable来创建并初始化;本例子中,我们用常量0来初始化tensor。
可以看到W的shape为【Dimension(784), Dimension(10)】,这是由它的参数常量tensor tf.zeros[784,10]定义的。参数b也是类似,由它的参数指定形状为[Dimension(10)]。
矩阵W有这样的大小是因为对于10个可能性中的任一个。它都要与图片向量784个位置相乘,加上b之后生成一个“证据”tensor。
本例子中使用了MNIST,同样需要创建一个2维的tensor来保留这些点的信息,代码如下:

tensorx将用来存储MNIST图像向量中784个浮点值(None代表该维度可为任意大小,本例子中将会是学习过程中照片的数量)
定义完tensor后,接下来就可以实现模型。TensorFlow提供了很多操作来实现之前描述的softmax函数,tf.nn.softmax(logits,name)只是众多可用操作中的一个。参数必须是一个tensor,另外一个可选参数是name。函数返回一个同类型的tensor,其shape与参数一样。
在本例子中,我们将图像向量x与权重矩阵W相乘再加上b之后的结果作为参数传给softmax函数:
y=tf.nn.softmax(tf.matmul(x,W)+b)
一旦确认了模型的实现,就可以通过一个迭代训练算法来获得权重W和bias b。在每次迭代中,训练算法读入训练数据,应用神经网络,比较输出结果与预期结果。
为了能够判断一个模型是足够好还是足够坏,我们需要定义足够好的定义。如之前章节中看到的,通用的方法是定义相反面:使用cost function表示一个模型有多坏。这样的话,目标就是找到参数W和b的值来最小化该函数。
有多种不同机制来度量在训练数据上输出结果与期望结果的差异。一个通用的方法是平均方差或平方欧氏距离。即使如此,一些研究小组针对神经网络提出了其它的机制,类似本例子中使用的交叉熵个代价函数。该算法计算公式如下:
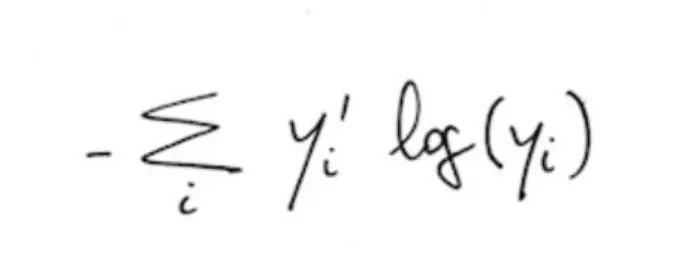
y是预测生成的概率分布,y`是训练数据集中标注的真实分布。这里不会深入到交叉熵背后的数学细节以及它在神经网络中的地位,因为这已经远超过本书的讨论范围;我们需要知道的是当两个分布完全一样的时候,此时获得最小值。再次说明,如果读者希望学习该函数的内部细节,建议阅读神经网络与深度学习一书。
为实现交叉熵,需要创建一个placeholder代表正确的标签:
y_=tf.placeholder("float",[None,10])
使用这个placeholder,可通过下面代码实现交叉熵,用来代表cost function:
cross_entropy=-tf.reduce_sum(y_*tf.log(y))
首先使用tensorflow中内置的tf.log()对每一个元素y求对数,然后再与每一个y_的元素相乘。最后使用tf.reduce_sum对tensor的所有元素求和(稍后我们会看到图片是分批处理的,所以交叉熵的值是一批照片的,并不是一张照片的)。
在迭代中,一旦对样本定义了错误表示,就需要在下次迭代中修正模型(通过修改参数W和b)来减少计算结果与期望结果的差值。
最后,只需要实现迭代最小化的处理过程。神经网络中有一些算法来解决这个问题;我们使用反向传播(backward propagation of errors)算法,正如它的名字所示,该算法会反向传播输出中的错误值,以用来重新计算权重W,该算法对多层神经网络尤其重要。
反射传播算法通常会与梯度下降算法一起使用,梯度下降算法中会使用交叉熵cost function,并使得我们在每次迭代中根据局部可用信息来计算需要多大程度修改参数来降低错误值。在本例子中,它会在每一次迭代中持续一点点修改权重W(这里的每一小步表示为学习速率参数,表示变化的速率)来降低错误值。
由于本例子中我们使用的神经网络只有一层,我们不会详细分析反射传播算法。只需要记住TensorFlow知道全部计算图,并使用优化算法为cost function找到合适的梯度来训练模型。
因为我们使用了MNIST数据集,下面的代码显示我们使用反向传播算法与梯度下降算法来最小化交叉熵,同时学习速率为0.01。
train_step=tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
到现在为止,我们已经实现了所有问题,可以通过创建tf.Session()开始在可用设备CPUS或GPUS上计算各操作:
sess=tf.Session()
接下来,通过一个操作来初始化所有变量:
sess.run(tf.initialize_all_variables())
从现在开始,我们可以训练模型。执行后返回的train_step参数,会对相关参数应用梯度下降。所以训练模型可以通过重复执行train_step来实现。假如我们想迭代1000次train_step;通过下面的代码就能实现:

循环中的第一行表示,每次迭代中,从训练数据集中随机选取100张图片作为一批。在每次迭代时,虽然我们可以使用全部训练数据集,但为了使得本例子更精巧,我们每次选择使用一小部分样本。第二行表示之前获得的输入分别赋给相关的placeholders。
最后说明一点,基于梯度下降的机器学习算法可以充分利用TensorFlow自动对比差值的能力。TensorFlow的用户只需要定义预测模型的计算结构,与目标函数相结合,然后只需要提供数据。
TensorFlow同样负责学习过程背后的导数计算。当minimize()被执行时,TensorFlow辨认出loss function依赖的变量集合,对集合中的每一个变量计算梯度。如果你有兴趣了解对比是如何实现的,可以研究ops/gradients.py文件。
训练得到的模型必须被评估来看该模型是有多好(或多坏)。例如,我们可以计算在预测中正确与错误的比例,查看哪些样本被正确的预测了。在之前的章节中,我们看到tf.argmax(y,1)函数会返回tensor中参数指定的维度中的最大值的索引。在效果上,tf.argmax(y,1)是我们模型中输入数据的最大概率标签,tf.argmax(y_,1)是实际的标签。通过tf.equal方法可以比较预测结果与实际结果是否相等:
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
这行代码返回一个布尔列表。为得到哪些预测是正确的,我们可用如下代码将布尔值转换成浮点数:
accuracy=tf.reduce_mean(tf.cast(correct_prediction,"float"))
例如,[True, False, True, True]会转换成[1,0,1,1],其平均值0.75代表了准确比例。现在我们可使用mnist.test数据集作为feed_dict参数来计算准确率:
printsess.run(accuracy,feed_dict={x:mnist.test.images,y_:mnist.test.labels})
我得到的精度是91%。这个精度好吗?我认为非常好,因为读者已经可以在TensorFlow中编程并执行他们的第一个神经网络。
另外一个问题是其它模型可能提供更好的精度,下一章中的多层神经网络会详细讲解。
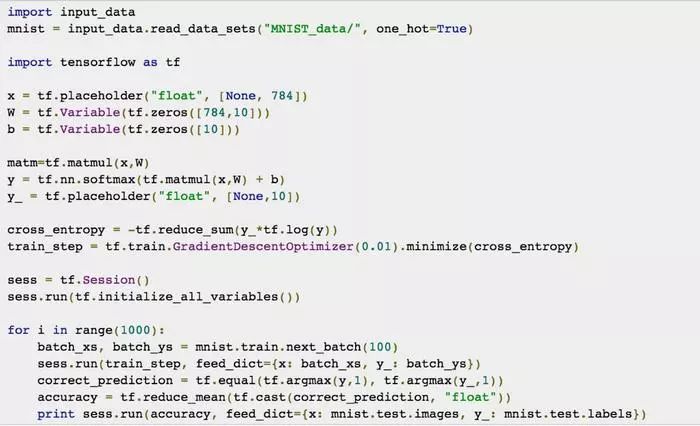
读者可在github上的RedNeuronalSimple.py文件中看到本章中所有代码,全部代码如下:
下一章节中人分析构建多层神经网络。
原文链接:http://www.jianshu.com/p/1f1d9e19373f
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看

TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络

点击“阅读原文”直接打开报名链接














 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









