






12月23-24日

正文共3017个字 4张图,预计阅读时间:18分钟。
pandas有两个最主要的数据结构,分别是Series和DataFrame,所以一开始的任务就是好好熟悉一下这两个数据结构。

官方文档: pandas.Series (http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.html#pandas.Series )
Series是类似于一维数组的对象,由一组数据(各种numpy的数据类型)以及一组与之相关的标签组成。首先看一下怎么构造出Series来。
class pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
参数:
data : 类array的,字典,或者是标量
index : 索引列表,和data的长度一样
dtype : numpy.dtype,没有的话,会根据data内容自动推断
copy : boolean,默认是False
接下来给出属性,常用的属性经常用到的不多,其他的属性可以查上面给出的文档。
属性:
dtype 数据元素的类型.
empty 是否为空.
index 索引对象
ix A primarily label-location based indexer, with integer position fallback.
loc Purely label-location based indexer for selection by label.
name
nbytes return the number of bytes in the underlying data
ndim 返回数据部分的维度大小
shape 返回一个元组,表示数据的形状
size 返回元素的数量。
strides return the strides of the underlying data
values 返回Series对象中的值部分,ndarray类型
这里直接给出例子来创建Series。有很多中创建方式,很繁杂,所以就把例子放在一起,就一目了然了。
# -*- coding: utf-8 -*-
from __future__ import print_function,division
#from pandas import Series,DataFrame
import pandas as pd
#传入data却不传入索引列表,那么自动创建0~N-1的索引
S=pd.Series(data=[1,2,3,4])
print ("S:\n",S)
#传入了data和索引列表
print ()
S2=pd.Series(data=[4,3,2,1],index=["a","b","c","d"])
print ("S2:\n",S2)
print (S2.index)
#通过索引的方式来访问一个或者一列值(很像字典的访问)
print (S2['c'])
print (S2[['a','b','c']])#通过字典创建(上面还说了很像一个字典)
print () dict={"leo":24,"kate":23,"mat":11}
S3=pd.Series(data=dict)
print ("S3:\n",S3)
#即使是传入一个字典,还是可以传入一个索引的,
# 要是索引和字典中的相同,那么就会并进去
# 要是不相同,那么找不到值,相应的value就会被设为NaN
print () idx=["leo","kate","pig","cat"]
S4=pd.Series(data=dict,index=idx)
print ("S4:\n",S4)
结果:详解看注释 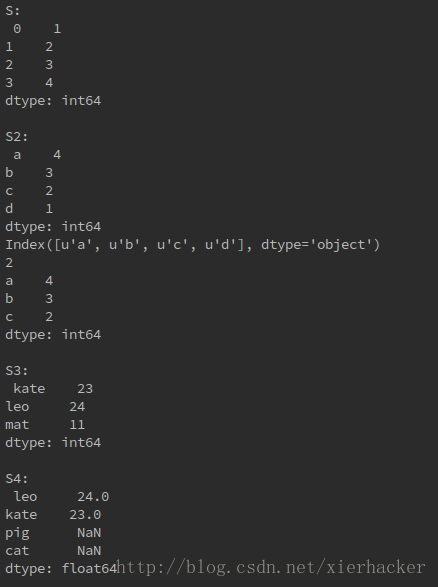

官方文档:DataFrame
很自然的,首先依旧是要看一下怎么创建DataFrame对象.下面是构造函数.
class pandas.DataFrame(data=None,index=None,columns=None, dtype=None, copy=False)
参数:
data : 传入的数据,可以是二维的ndarray,字典,或者一个DataFrame对象.还可以传入各种类型组合的数据,这里不细讲了,在实际中遇到再讲
index : Index对象或者array-like型,可以简单的理解为”行”索引.
columns :Index对象或者array-like型,可以简单的理解为列索引.
dtype : 元素的类型.
copy : 布尔值,表示是否显式复制.默认为False.
这里直接通过例子来说明DataFrame的创建.
创建DataFrame对象最常用的就是传入等长列表组成的字典啦:
import numpy as np
import pandas as pd
#等长列表组成的字典
data={
"name":["leo","tom","kate","pig"],
"age":[10,20,30,40],
"weight":[50,50,40,200]
}
frame=pd.DataFrame(data=data)
print("frame:")
print(frame)
#指定列顺序columns
frame2=pd.DataFrame(data=data,columns=["name","weight","age"])
print("frame2:")
print(frame2)
#指定index,其中columns参数里面没有的,会被设置为NaN
frame3=pd.DataFrame(data=data,columns=["name","weight","age","height"],index=["one","two","three","four"])
print("frame3:")
print(frame3)
#索引一列
print("name:\n",frame3["name"])
print("weight:\n",frame3.weight)
#改变一列的值
frame3["height"]=100
print("frame3")
print(frame3)
结果: 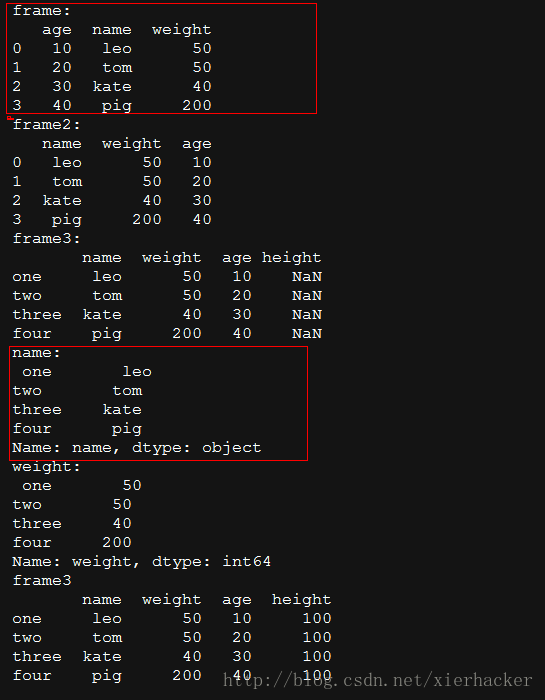
T:转秩
at 基于索引的快速标量访问器,比如使用的时候xxx.at[index,colume]
iat 整形索引快速访问标量,使用方式例如obj.iat[1,2],相当于依靠位置访问某个元素
dtypes 返回各个列的元素类型.
empty 判断是否是空
loc 通过index来选择,可以得到标量,也可以得到一个Series对象.使用方式可以参照at属性.
iloc 整形索引,作用和loc一模一样,只是这个是通过整形来索引.这些都只能够得到单个的行或者列.
ix 可以根据标签选择单个或者一组行,单个列或者一组列,是非常灵活的属性.
ndim 维度数目Number of axes / array dimensions
shape 形状
size 所有元素数量
values 返回表示值的ndarray
这里是第一部分的一些示例代码:XierHacker/LearnPandas
原文链接:http://blog.csdn.net/xierhacker/article/details/60878855
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看

TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络

点击“阅读原文”直接打开报名链接














 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









