






正文共:11452个字,8张图,预计阅读时间:29分钟。
01
问题描述
我们的任务是从一个人的面部特征来预测他的年龄(用“Young”“Middle ”“Old”表示),我们训练的数据集大约有19906多张照片及其每张图片对应的年龄(全是阿三的头像。。。),测试集有6636张图片,首先我们加载数据集,然后我们通过深度学习框架Keras建立、编译、训练模型,预测出6636张人物头像对应的年龄。
02
引入所需要的模块
import os
import random
import pandas as pd
import numpy as np
from PIL import Image
03
加载数据集
root_dir=os.path.abspath('E:/data/age') train=pd.read_csv(os.path.join(root_dir,'train.csv')) test=pd.read_csv(os.path.join(root_dir,'test.csv')) print(train.head()) print(test.head())
ID Class
0 377.jpg MIDDLE
1 17814.jpg YOUNG
2 21283.jpg MIDDLE
3 16496.jpg YOUNG
4 4487.jpg MIDDLE
ID
0 25321.jpg
1 989.jpg
2 19277.jpg
3 13093.jpg
4 5367.jpg
04
随机读取一张图片试下
i=random.choice(train.index) img_name=train.ID[i] print(img_name) img=Image.open(os.path.join(root_dir,'Train',img_name)) img.show() print(train.Class[i])
20188.jpg
MIDDLE
05
难点
我们随机打开几张图片之后,可以发现图片之间的差别比较大。大家感受下:
质量好的图片:
Middle:

*Middle**
Young:

**Young**
Old:

*Old**
质量差的:
Middle:

**Middle**
下面是我们需要面临的问题:
1、图片的尺寸差别:有的图片的尺寸是66x46,而另一张图片尺寸为102x87
2、人物面貌角度不同:
侧脸:

正脸:

3、图片质量不一(直接上图):

插图
4、亮度和对比度的差异

亮度

对比度
现在,我们只专注下图片尺寸处理,将每一张图片尺寸重置为32x32;
06
格式化图片尺寸和将图片转换成numpy数组
temp=[]for img_name in train.ID: img_path=os.path.join(root_dir,'Train',img_name) img=Image.open(img_path) img=img.resize((32,32)) array=np.array(img) temp.append(array.astype('float32')) train_x=np.stack(temp) print(train_x.shape) print(train_x.ndim)(19906, 32, 32, 3) 4temp=[]for img_name in test.ID: img_path=os.path.join(root_dir,'Test',img_name) img=Image.open(img_path) img=img.resize((32,32)) array=np.array(img) temp.append(array.astype('float32')) test_x=np.stack(temp) print(test_x.shape)(6636, 32, 32, 3)
另外我们再归一化图像,这样会使模型训练的更快
train_x = train_x / 255.test_x = test_x / 255.
我们看下图片年龄大致分布:
train.Class.value_counts(normalize=True)
MIDDLE 0.542751
YOUNG 0.336883
OLD 0.120366
Name: Class, dtype: float64
test['Class'] = 'MIDDLE
'test.to_csv('sub01.csv', index=False)
将目标变量处理虚拟列,能够使模型更容易接受识别它
import keras
from sklearn.preprocessing import LabelEncoder
lb=LabelEncoder() train_y=lb.fit_transform(train.Class) print(train_y) train_y=keras.utils.np_utils.to_categorical(train_y) print(train_y) print(train_y.shape)
[0 2 0 ..., 0 0 0]
[[ 1. 0. 0.] [ 0. 0. 1.] [ 1. 0. 0.] ..., [ 1. 0. 0.] [ 1. 0. 0.] [ 1. 0. 0.]] (19906, 3)
07
创建模型
#构建神经网络
input_num_units=(32,32,3) hidden_num_units=500
output_num_units=3
epochs=5
batch_size=128
from keras.models import Sequential
from keras.layers import Dense,Flatten,InputLayer model=Sequential({ InputLayer(input_shape=input_num_units), Flatten(), Dense(units=hidden_num_units,activation='relu'), Dense(input_shape=(32,32,3),units=output_num_units,activation='softmax') }) model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
========================================
input_23 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
flatten_23 (Flatten) (None, 3072) 0
_________________________________________________________________
dense_45 (Dense) (None, 500) 1536500
_________________________________________________________________
dense_46 (Dense) (None, 3) 1503
========================================
Total params: 1,538,003
Trainable params: 1,538,003
Non-trainable params: 0
_________________________________________________________________
08
编译模型
# model.compile(optimizer='sgd',loss='categorical_crossentropy',metrics['accuracy'])
model.compile(optimizer='sgd',loss='categorical_crossentropy', metrics=['accuracy']) model.fit(train_x,train_y,batch_size=batch_size,epochs=epochs,verbose=1)
Epoch 1/5
19906/19906 [==============================]
- 4s - loss: 0.8878 - acc: 0.5809 Epoch 2/5 19906/19906 [==============================]
- 4s - loss: 0.8420 - acc: 0.6077 Epoch 3/5 19906/19906 [==============================]
- 4s - loss: 0.8210 - acc: 0.6214 Epoch 4/5 19906/19906 [==============================]
- 4s - loss: 0.8149 - acc: 0.6194 Epoch 5/5 19906/19906 [==============================]
- 4s - loss: 0.8042 - acc: 0.6305
<keras.callbacks.History at 0x1d3803e6278>
model.fit(train_x, train_y, batch_size=batch_size,epochs=epochs,verbose=1, validation_split=0.2)
Train on 15924 samples, validate on 3982 samples Epoch 1/5 15924/15924 [==============================]
- 3s - loss: 0.7970 - acc: 0.6375 - val_loss: 0.7854 - val_acc: 0.6396 Epoch 2/5 15924/15924 [==============================]
- 3s - loss: 0.7919 - acc: 0.6378 - val_loss: 0.7767 - val_acc: 0.6519 Epoch 3/5 15924/15924 [==============================]
- 3s - loss: 0.7870 - acc: 0.6404 - val_loss: 0.7754 - val_acc: 0.6534 Epoch 4/5 15924/15924 [==============================]
- 3s - loss: 0.7806 - acc: 0.6439 - val_loss: 0.7715 - val_acc: 0.6524 Epoch 5/5 15924/15924 [==============================]
- 3s - loss: 0.7755 - acc: 0.6519 - val_loss: 0.7970 - val_acc: 0.6346
<keras.callbacks.History at 0x1d3800a4eb8>
09
优化
我们使用最基本的模型来处理这个年龄预测结果,并且最终的预测结果为0.6375。接下来,从以下角度尝试优化:
1、使用更好的神经网络模型
2、增加训练次数
3、将图片进行灰度处理(因为对于本问题而言,图片颜色不是一个特别重要的特征。)
10
optimize1 使用卷积神经网络
添加卷积层之后,预测准确率有所上涨,从6.3到6.7;最开始epochs轮数是5,训练轮数增加到10,此时准确率为6.87;然后将训练轮数增加到20,结果没有发生变化。
11
Conv2D层
keras.layers.convolutional.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
filters:输出的维度
strides:卷积的步长
更多关于Conv2D的介绍请看Keras文档Conv2D层(http://keras-cn.readthedocs.io/en/latest/layers/convolutional_layer/#conv2d)
#参数初始化
filters=10
filtersize=(5,5) epochs =10
batchsize=128
input_shape=(32,32,3)
from keras.models import Sequential model = Sequential() model.add(keras.layers.InputLayer(input_shape=input_shape)) model.add(keras.layers.convolutional.Conv2D(filters, filtersize, strides=(1, 1), padding='valid', data_format="channels_last", activation='relu')) model.add(keras.layers.MaxPooling2D(pool_size=(2, 2))) model.add(keras.layers.Flatten()) model.add(keras.layers.Dense(units=3, input_dim=50,activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(train_x, train_y, epochs=epochs, batch_size=batchsize,validation_split=0.3) model.summary()
Train on 13934 samples, validate on 5972 samples Epoch 1/1
013934/13934 [==============================] - 9s - loss: 0.8986 - acc: 0.5884 - val_loss: 0.8352 - val_acc: 0.6271
Epoch 2/1
013934/13934 [==============================] - 9s - loss: 0.8141 - acc: 0.6281 - val_loss: 0.7886 - val_acc: 0.6474
Epoch 3/1
013934/13934 [==============================] - 9s - loss: 0.7788 - acc: 0.6504 - val_loss: 0.7706 - val_acc: 0.6551
Epoch 4/1
013934/13934 [==============================] - 9s - loss: 0.7638 - acc: 0.6577 - val_loss: 0.7559 - val_acc: 0.6626
Epoch 5/1
013934/13934 [==============================] - 9s - loss: 0.7484 - acc: 0.6679 - val_loss: 0.7457 - val_acc: 0.6710
Epoch 6/1
013934/13934 [==============================] - 9s - loss: 0.7346 - acc: 0.6723 - val_loss: 0.7490 - val_acc: 0.6780
Epoch 7/1
013934/13934 [==============================] - 9s - loss: 0.7217 - acc: 0.6804 - val_loss: 0.7298 - val_acc: 0.6795
Epoch 8/1
013934/13934 [==============================] - 9s - loss: 0.7162 - acc: 0.6826 - val_loss: 0.7248 - val_acc: 0.6792
Epoch 9/1
013934/13934 [==============================] - 9s - loss: 0.7082 - acc: 0.6892 - val_loss: 0.7202 - val_acc: 0.6890
Epoch 10/1
013934/13934 [==============================] - 9s - loss: 0.7001 - acc: 0.6940 - val_loss: 0.7226 - val_acc: 0.6885
_________________________________________________________________
Layer (type) Output Shape Param #
========================================
input_6 (InputLayer) (None, 32, 32, 3) 0
_______________________________________________________________
conv2d_6 (Conv2D) (None, 28, 28, 10) 760
_______________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 14, 14, 10) 0
_______________________________________________________________
flatten_6 (Flatten) (None, 1960) 0
_________________________________________________________________
dense_6 (Dense) (None, 3) 5883
========================================
Total params: 6,643
Trainable params: 6,643
Non-trainable params: 0
_________________________________________________________________
12
optimize2 增加神经网络的层数
我们在模型中多添加几层并且提高卷几层的输出维度,这次结果得到显著提升:0.750904
#参数初始化
filters1=50
filters2=100
filters3=100
filtersize=(5,5) epochs =10
batchsize=128
input_shape=(32,32,3)
from keras.models import Sequential
model = Sequential() model.add(keras.layers.InputLayer(input_shape=input_shape)) model.add(keras.layers.convolutional.Conv2D(filters1, filtersize, strides=(1, 1), padding='valid', data_format="channels_last", activation='relu'))
model.add(keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(keras.layers.convolutional.Conv2D(filters2, filtersize, strides=(1, 1), padding='valid', data_format="channels_last", activation='relu'))
model.add(keras.layers.MaxPooling2D(pool_size=(2, 2))) model.add(keras.layers.convolutional.Conv2D(filters3, filtersize, strides=(1, 1), padding='valid', data_format="channels_last", activation='relu'))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(units=3, input_dim=50,activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(train_x, train_y, epochs=epochs, batch_size=batchsize,validation_split=0.3) model.summary()
Train on 13934 samples, validate on 5972 samples
Epoch 1/1
013934/13934 [==============================] - 44s - loss: 0.8613 - acc: 0.5985 - val_loss: 0.7778 - val_acc: 0.6586
Epoch 2/1
013934/13934 [==============================] - 44s - loss: 0.7493 - acc: 0.6697 - val_loss: 0.7545 - val_acc: 0.6808
Epoch 3/1
013934/13934 [==============================] - 43s - loss: 0.7079 - acc: 0.6877 - val_loss: 0.7150 - val_acc: 0.6947
Epoch 4/1
013934/13934 [==============================] - 43s - loss: 0.6694 - acc: 0.7061 - val_loss: 0.6496 - val_acc: 0.7261
Epoch 5/1
013934/13934 [==============================] - 43s - loss: 0.6274 - acc: 0.7295 - val_loss: 0.6683 - val_acc: 0.7125
Epoch 6/1
013934/13934 [==============================] - 43s - loss: 0.5950 - acc: 0.7462 - val_loss: 0.6194 - val_acc: 0.7400
Epoch 7/1
013934/13934 [==============================] - 43s - loss: 0.5562 - acc: 0.7655 - val_loss: 0.5981 - val_acc: 0.7465
Epoch 8/1
013934/13934 [==============================] - 43s - loss: 0.5165 - acc: 0.7852 - val_loss: 0.6458 - val_acc: 0.7354
Epoch 9/1
013934/13934 [==============================] - 46s - loss: 0.4826 - acc: 0.7986 - val_loss: 0.6206 - val_acc: 0.7467
Epoch 10/1
013934/13934 [==============================] - 45s - loss: 0.4530 - acc: 0.8130 - val_loss: 0.5984 - val_acc: 0.7569
_________________________________________________________________ Layer (type) Output Shape Param #
========================================== input_15 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________ conv2d_31 (Conv2D) (None, 28, 28, 50) 3800
_________________________________________________________________ max_pooling2d_23 (MaxPooling (None, 14, 14, 50) 0
_________________________________________________________________ conv2d_32 (Conv2D) (None, 10, 10, 100) 125100
_________________________________________________________________ max_pooling2d_24 (MaxPooling (None, 5, 5, 100) 0
_________________________________________________________________ conv2d_33 (Conv2D) (None, 1, 1, 100) 250100
_________________________________________________________________ flatten_15 (Flatten) (None, 100) 0
_________________________________________________________________ dense_7 (Dense) (None, 3) 303
========================================== Total params: 379,303
Trainable params: 379,303
Non-trainable params: 0
_________________________________________________________________
13
输出结果
pred=model.predict_classes(test_x) pred=lb.inverse_transform(pred) print(pred) test['Class']=pred test.to_csv('sub02.csv',index=False)
6636/6636 [==============================] - 7s ['MIDDLE' 'YOUNG' 'MIDDLE' ..., 'MIDDLE' 'MIDDLE' 'YOUNG']
i = random.choice(train.index) img_name = train.ID[i] img=Image.open(os.path.join(root_dir,'Train',img_name)) img.show() pred = model.predict_classes(train_x) print('Original:', train.Class[i], 'Predicted:', lb.inverse_transform(pred[i]))
19872/19906 [============================>.] - ETA: 0sOriginal: MIDDLE Predicted: MIDDLE
14
结果
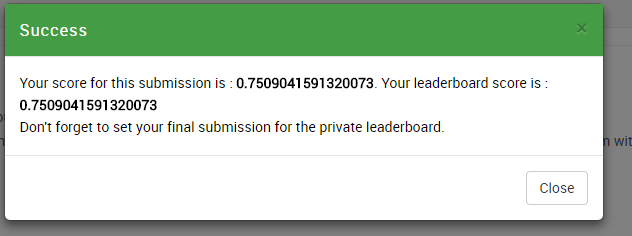
image.png
原文链接:https://www.jianshu.com/p/2354f3424377
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看

TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









