







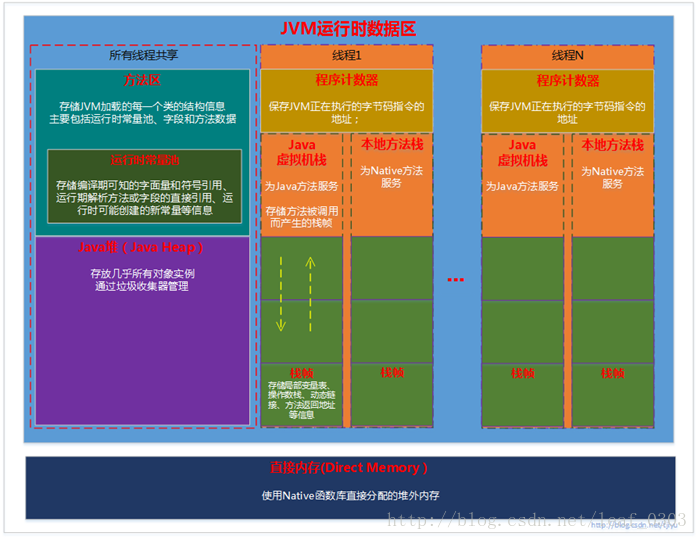
学习《深入理解Java 虚拟机》做些总结。并有参考其他博客的地方。如有不规范大家指出相互学习提高。我们知道java 虚拟机在执行java 程序的过程中会把它所管理的内存划分为若干不同的数据区域,这些区域都有各自的用途,以及创建和销毁的时间。有的区域随着虚拟机进程(方法区、堆)的启动而存在,有些区域则依赖线程的启动和结束而建立和销毁(程序计数器、虚拟机栈、本地方法栈),先看下运行是数据区如下图:
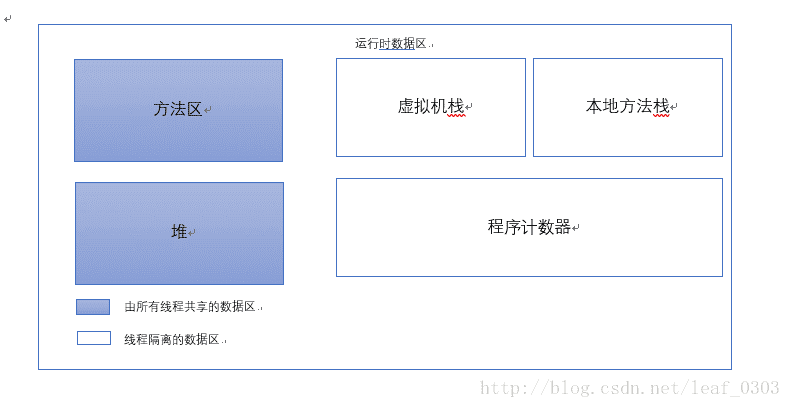
此图只是概念意义,并非实际分配内存大小比例。
虚拟机栈
虚拟机栈描述的是Java 方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每个方法从调用直至执行完成的过程,就对应这一个栈帧在虚拟机栈中入栈到出栈的过程
看如下简图
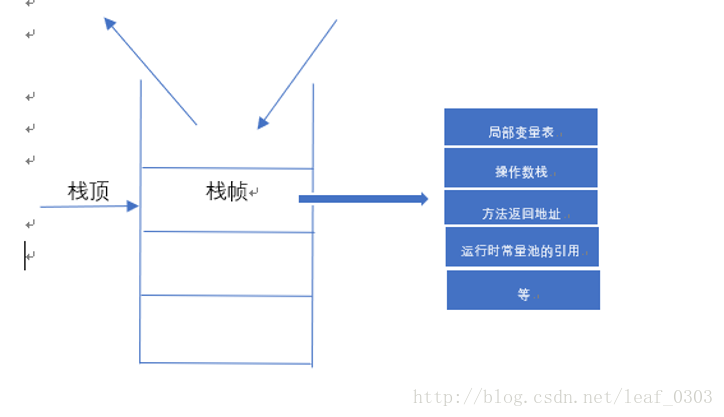
我们常说的java 内存空间分为堆内存(Heap)和栈内存(Stack),这种分法比较粗糙,只是我们平时最关注的、与对象内存分配关系最密切的内存区域是这两块,堆 下面会提到,栈内存就是这里的虚拟机栈。
栈帧的结构图:
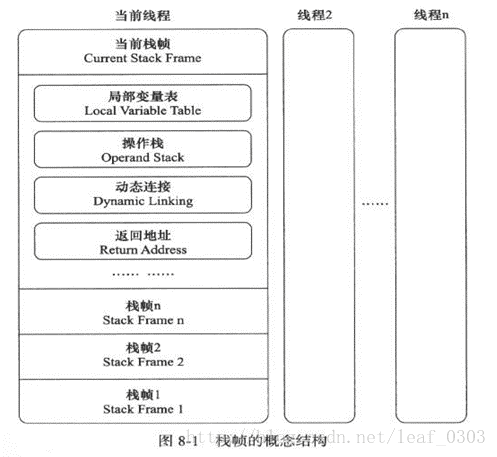
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用和returnAddress类型
异常(根据Java虚拟机规范)
a. 如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常
b. 如果虚拟机栈可以动态扩展(当前大部分Java虚拟机都可动态扩展,只不过Java虚拟机规范中也允许固定长度的虚拟机栈),如果扩展时无法申请到足够的内存,就会抛出OutOfMemoryError异常异常例子
在设置栈内存后进行代码测试,此例子中设置为128 K
package com.xnccs.cn.share;
/**
* 栈溢出测试
*
* VM : -Xss128k 栈内存容量
* @author j_nan
*
*/
public class JavaVMStackSOF {
private int stackLength = 1;
public void stackLeak(){
stackLength ++;
stackLeak();
}
public static void main(String[] args) {
JavaVMStackSOF oom = new JavaVMStackSOF();
try{
oom.stackLeak();
}catch(Throwable e){
System.out.println("stack length:" + oom.stackLength);
throw e;
}
}
}
输出:
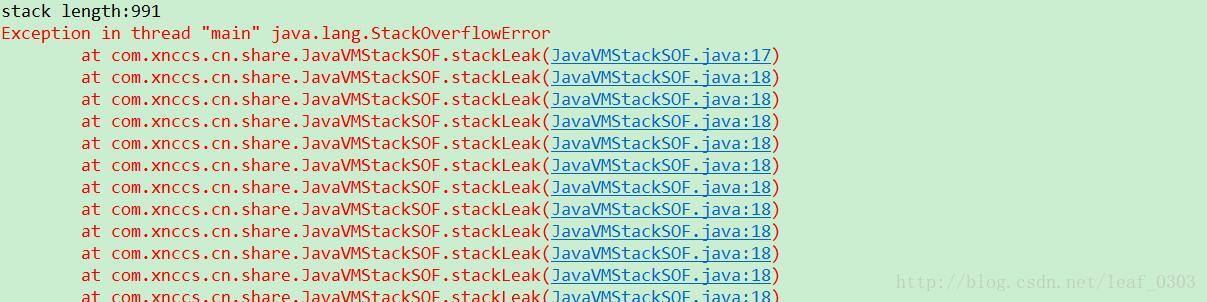
- 代码优化点
由上我们已经知道局部变量表所需的内存空间在编译期完成分配,当进入一个方法时,这个方法需要在栈帧中分配多大的局部变量空间是完全确定的,在方法的运行期间不会改变局部变量表的大小。
所以当方法内的参数过多时,我们可以采取使用参数类来代替也减小局部变量表的大小使得相同栈大小的情况下有更高的栈深。以上个例子来说,如果我们将stackLeak()方法改成 十多个参数,那绝对不会等到stack lenght:991 的时候才报异常。本人试过在stack length:434 时就报错,大家可以自行试试就不再贴代码了
本地方法栈
本地方法栈与虚拟机栈所发挥的作用是非常相似的,它们之前的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的native 方法服务。
如 System.currentTimeMillis(); public static native long currentTimeMillis(); 此获取当前毫秒就是native方法
- 异常
与虚拟机栈一样,本地方法栈区域也回会抛出StackOverflowError 和 OutOfMemoryError异常
方法区
方法区与java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码数据等数据
类信息,每个类的全限定名、每个类的直接超类的全限定名、该类的类还是接口、该类型的访问修饰符,直接超接口的全限定名的有序列表
即时编译器编译后的代码, jvm 加载执行的是二进制字节码Class文件,它最终会翻译成系统能识别机器码,这个过程最初是通过解释器进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”。为了提高热点代码的执行效率,在运行时虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,以便下次直接使用这些编译后的机器码来提高运行效率
- 异常
当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常
堆
对于大多数应用来说,Java 堆 是Java 虚拟机所管理的的内存中最大的一块,此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。在Java 虚拟机规范中的描述是:所有的对象以及数组都要在堆上分配,但是随着JIT编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化发生,所有的对象都分配在堆上也就不那么绝对了。
简单理解就是,在堆上的大部分对象都会在发生GC 时被回收释放内存,但GC 同样是需要耗费资源,那如果确定一个对象只在一个方法区内出现,不存在逃逸现象,则可以考虑将此对象创建在栈上,随着方法的执行完成而回收对象的空间也就优化了GC的负担。但就我们常见的HotSpot 虚拟机来说目前没有这种机制,不存在在栈上创建对象的情况。
Java 堆是垃圾收集器管理的主要区域,从内存回收的角度来看,由于现在收集器基本都采用分代收集算法,所以Java堆中还可以细分为:新生代和老年代;新生代中还可以分为Eden空间、From Survivor空间、To Survivor空间。它们比例默认是 8:1:1 。
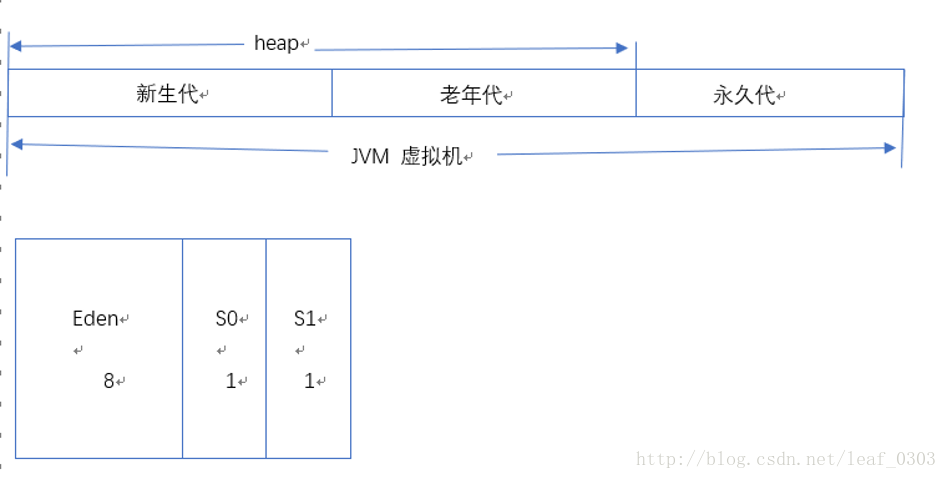
异常
如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常异常例子
package com.xnccs.cn.share;
import java.util.ArrayList;
import java.util.List;
/**
* 堆溢出测试
*
* VM: -Xms20m -Xmx20m
* @author j_nan
*
*/
public class HeapOOM {
static class OOMObject{
}
public static void main(String[] args) throws InterruptedException {
List<OOMObject> list = new ArrayList<OOMObject>();
while(true){
try{
list.add(new OOMObject());
}catch(Throwable e){
System.out.println("集合中对象数量是:"+list.size());
throw e;
}
}
}
}
程序计数器
程序计数器,指向当前线程正在执行的字节码指令地址。详细内容已经总结过,地址如下:
http://blog.csdn.net/leaf_0303/article/details/78953669
java 内存情况,在其他博客中看到此图,感觉挺好理解
直接内存
直接内存,已经单列章节,地址如下:
http://blog.csdn.net/leaf_0303/article/details/78961936














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









