







 本文介绍了如何使用Docker简化Hadoop集群的搭建过程,包括获取镜像、创建容器、配置SSH、配置Hadoop、运行Hadoop及检测集群状况。通过Docker避免了虚拟机的繁琐,使集群部署变得简单快捷。
本文介绍了如何使用Docker简化Hadoop集群的搭建过程,包括获取镜像、创建容器、配置SSH、配置Hadoop、运行Hadoop及检测集群状况。通过Docker避免了虚拟机的繁琐,使集群部署变得简单快捷。
刚开始搭建hadoop集群的时候,使用的是VMware创建的虚拟机。结果卡到心态爆炸。。。
今天尝试使用Docker搭建hadoop集群,发现是如此的好用快捷,也比使用VMware简单。
在这里记录一下防止以后忘记,为以后的学习做准备。
1.获取镜像。
如果是本地使用VMware搭建的话,需要准备java环境,hadoop安装包,还要配置环境变量。虽然不难,但是经常做这些工作也难免烦躁。
使用Docker容器的话,那这一切就变得简单多了。
首先要准备一个镜像,可以使用Dockerfile构建一个合适自己的镜像,或者可以在共有仓库中找一个具有hadoop环境的镜像来使用也可以。由于我是配置的阿里云的加速器,所以在阿里云的仓库中找了一个具有hadoop环境的镜像。hadoop镜像地址
使用命令拉到本地:
docker pull registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop下载完成之后,通过docker images 可以查看到该镜像:

2.创建容器。
有了镜像之后,我们根据该镜像创建三个容器,分别是一个Master用来作为hadoop集群的namenode,剩下两个Slave用来作为datanode。
可以使用命令:
docker run -i -t --name Master -h Master registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop /bin/bash命令中的-h为该容器设置了主机名,这里设置为Master,否则创建容器之后是一串随机的数字和字母不好辨认使用。–name指定了容器的名字,也是为了方便区分使用。
建立好Master节点的容器之后,再分别使用两次该命令,创建两个Slave节点。稍微改变其中的参数即可:
例如创建Slave1节点:
docker run -i -t --name Slave1 -h Slave1 registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop /bin/bash这样集群的基本环境就准备好了。
3.配置SSH。
如果是本地搭建的话,需要配置的大概分为三步:
1.配置java环境。
2.配置无秘SSH。
3.配置hadoop环境。
但是下载的镜像已经包含了这些内容,我们只需要简单的配置一下就可以使用了。
在这个镜像中,有关java和hadoop的内容都存放在了/opt/tools目录下。
先查看下环境变量都包含了什么:

从中间可以看出包含了jdk和hadoop的bin目录,所以我们可以直接使用这两个命令。
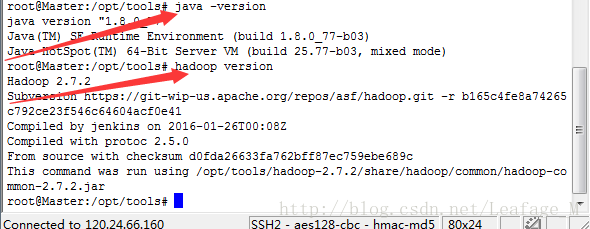
java环境已经不需要我们来配置了。
接下来配置一下无秘的SSH。
首先将SSH运行起来。
/etc/init.d/ssh start然后生成秘钥,保存到authorized_keys中。这个地方可以看一下这篇博客:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









