







结构:
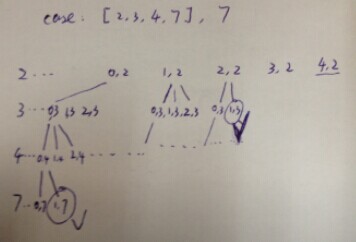
1.1 有重复的push_back()和 pop_back()操作
class Solution {
private:
void visit(vector<int> &candidates, int i, int sum, int target, vector<int> &tmp, vector<vector<int>> &rs) {
//特别注意边界条件的顺序
if (sum == target) {
rs.push_back(tmp);
return;
}
if (sum > target) return;
if (i == candidates.size()) return; //注意和sum == target的顺序
for (int mul = 0; mul * candidates[i] <= target; ++mul) {
if (mul == 0) {
visit(candidates, i+1, sum, target, tmp, rs);
continue;
}
sum += mul * candidates[i];
for (int j=1; j<=mul; ++j) tmp.push_back(candidates[i]);
visit(candidates, i+1, sum, target, tmp, rs);
sum -= mul * candidates[i];
for (int j=1; j<=mul; ++j) tmp.pop_back();
}
}
public:
vector<vector<int> > combinationSum(vector<int> &candidates, int target) {
vector<vector<int> > rs;
vector<int> tmp;
sort(candidates.begin(), candidates.end());
visit(candidates, 0, 0, target, tmp, rs);
return rs;
}
};class Solution {
private:
void visit(vector<int> &candidates, int i, int sum, int target, vector<int> &tmp, vector<vector<int>> &rs) {
//特别注意边界条件的顺序
if (sum == target) {
rs.push_back(tmp);
return;
}
if (sum > target) return;
if (i == candidates.size()) return; //注意和sum == target的顺序
int mul;
for (mul = 0; sum < target; ++mul) {
if (mul != 0) {
sum += candidates[i];
tmp.push_back(candidates[i]);
}
visit(candidates, i+1, sum, target, tmp, rs);
}
for (int j=mul; j>1; --j) tmp.pop_back();
}
public:
vector<vector<int> > combinationSum(vector<int> &candidates, int target) {
vector<vector<int> > rs;
vector<int> tmp;
sort(candidates.begin(), candidates.end());
visit(candidates, 0, 0, target, tmp, rs);
return rs;
}
};2. Subset I and II
思路:
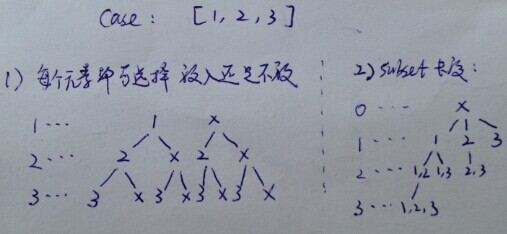
class Solution {
private:
void dfs1(vector<int> &S, vector<int> &tmp, vector<vector<int>> &rs, int i) { //push or not push
if (i == S.size()) {
rs.push_back(tmp);
return;
}
dfs(S, tmp, rs, i+1);
tmp.push_back(S[i]);
dfs(S, tmp, rs, i+1);
tmp.pop_back();
}
void dfs2(vector<int> &S, vector<int> &tmp, vector<vector<int>> &rs, int i) { //length of the subset
rs.push_back(tmp);
for (int k = i; k < S.size(); ++k) {
tmp.push_back(S[k]);
dfs(S, tmp, rs, k+1);
tmp.pop_back();
}
}
public:
vector<vector<int> > subsets(vector<int> &S) {
sort(S.begin(), S.end());
vector<vector<int>> rs;
vector<int> tmp;
dfs(S, tmp, rs, 0);
return rs;
}
};
此题把上题的distinct的元素变成有重复元素的了,而且要求结果不含相同的subset。
思路:case: [1,2,2], 采用第二种思路更为方便去重

class Solution {
private:
void dfs(vector<int> &S, vector<int> &tmp, vector<vector<int>> &rs, int i) {
rs.push_back(tmp);
for (int k = i; k < S.size(); ++k) {
if (k > i && S[k] == S[k-1]) continue; //去重
tmp.push_back(S[k]);
dfs(S, tmp, rs, k+1);
tmp.pop_back();
}
}
public:
vector<vector<int> > subsetsWithDup(vector<int> &S) {
vector<int> tmp;
vector<vector<int>> rs;
sort(S.begin(), S.end());
dfs(S, tmp, rs, 0);
return rs;
}
};此题我想说明,有注释的那行,到底在干什么。
我想大家都知道注释为1.的那行tmp.pop_back(); 是做什么的; 但是注释为2.的那行tmp.pop_back(); 是干什么的呢?
请看下图:

1->2->3->... 的回退过程就是注释2.那句tmp.pop_back(); 做的事情。
class Solution {
private:
void visit(int left, int right, int n, string& tmp, vector<string>& rs) {
if (left == right && left == n) {
rs.push_back(tmp);
return;
}
if (left > n) return;
if (left < n) {
tmp.push_back('(');
visit(left+1, right, n, tmp, rs);
tmp.pop_back(); //1.向上回退
}
if (right < left) {
tmp.push_back(')');
visit(left, right+1, n, tmp, rs);
tmp.pop_back(); //2. 向上回退
}
}
public:
vector<string> generateParenthesis(int n) {
vector<string> rs;
string tmp;
visit(0, 0, n, tmp, rs);
return rs;
}
};














 2043
2043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









