









一切为了做个好爸爸。其实爸爸这个词,真的很汗颜,在我们还没有学会如何孝敬父母的时候,却已经马上要为人父母了。惊喜总是来的很快,不自觉中,自己已经成长了。虽然不一定是个称职的爸爸,但是我想大家在这个时候也是想做的更好。
应老婆大人的要求,给俺家小宝宝先下载点胎教的音乐,奈何网上整理好的资源虽然丰富,但是没有成套的地址下载。发现几个挺不错的都是在线的儿童音乐网站。http://music.baby611.com 就是其中之一。作为一个具有极大职业病的程序员,每次看到网站总是习惯性的去查源码,还好,这个网站的对于音乐路径的隐藏并不深,可以说是直接明文显示的。不过,从主页面到子页面,一套音乐大概要好几十首,总不能一个个页面去查看吧。太苦逼了。 所以就想起了网页数据的自动抓取。
做网络数据抓取,其实办法并非唯一的,不过为了直观,我选用了比较麻烦的方式。那就是前台用WebBrowser控件,后台用HtmlAgilityPack这个组件来完成,其实涉及到的知识点也比较简单。
1、WebBrowser的使用,众所周知,这个控件就是一个简单的浏览器,我是用它来展示整个网页,其实也是借助它来下载页面,当然还有其他的方式可以下载。只不过这种比较直观,也可以当做页面查看器来用。
2、HtmlAgilityPack 这个控件很强大,本来之前是想用Xml解析的方式来做的,但是发现HTML页面,果然有很多标签并非很标准的XML方式,解析中出错很多,所以无奈只能选用这个控件,但是好在它的使用方法非常简单。具体的使用方法,在周公(周金桥)http://zhoufoxcn.blog.51cto.com/792419/595344 这篇文档中有详细的介绍,此处我只列举最主要的路径检索部分。
路径表达式:
nodename:选取此节点的所有子节点。
/:从根节点选取。
//:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
.:选取当前节点。
..:选取当前节点的父节点。
<?xml version="1.0" encoding="utf-8"?> <Articles> <Article> <Title>在ASP.NET中使用Highcharts js图表</title> <Url>http://zhoufoxcn.blog.51cto.com/792419/537324</Url> <CreateAt type="en">2011-04-07</price> </Article> <Article> <Title lang="eng">Log4Net使用详解(续)</title> <Url>http://blog.csdn.net/zhoufoxcn/archive/2010/11/23/6029021.aspx</Url> <CreateAt type="zh-cn">2010年11月23日</price> </Article> <Article> <Title>J2ME开发的一般步骤</title> <Url>http://blog.csdn.net/zhoufoxcn/archive/2011/06/12/6540223.aspx</Url> <CreateAt type="zh-cn">2011年06月12日</price> </Article> <Article> <Title lang="eng">PowerDesign高级应用</title> <Url>http://zhoufoxcn.blog.51cto.com/792419/166415</Url> <CreateAt type="zh-cn">2007-09-08</price> </Article> </Articles>
针对上面的XML文件,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
/Articles/Article[1]:选取属于Articles子元素的第一个Article元素。
/Articles/Article[last()]:选取属于Articles子元素的最后一个Article元素。
/Articles/Article[last()-1]:选取属于Articles子元素的倒数第二个Article元素。
/Articles/Article[position()<3]:选取最前面的两个属于 bookstore 元素的子元素的Article元素。
//title[@lang]:选取所有拥有名为lang的属性的title元素。
//CreateAt[@type='zh-cn']:选取所有CreateAt元素,且这些元素拥有值为zh-cn的type属性。
/Articles/Article[Order>2]:选取Articles元素的所有Article元素,且其中的Order元素的值须大于2。
/Articles/Article[Order<3]/Title:选取Articles元素中的Article元素的所有Title元素,且其中的Order元素的值须小于3。
代码中最关键的使用部分如下:
HTMLDocument doc = web.Document as HTMLDocument;//web就是 <WebBrowser Name="web" Grid.Row="1" Width="auto" /> if (doc ==null) { return; } IHTMLElement ielement = doc.documentElement; string body = ((mshtml.HTMLHtmlElement)(ielement)).innerHTML; string path = System.IO.Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "local.html"); StreamWriter sw = new StreamWriter(path, false, encoding); sw.Write(body); sw.Close(); HtmlDocument document = new HtmlDocument(); Encoding PageEncoding = Encoding.GetEncoding("gb2312"); document.Load(path, PageEncoding); HtmlNode rootHtml = document.DocumentNode; HtmlNodeCollection uili = rootHtml.SelectNodes("//div[@class='eglistsj']/ul/li/a"); if (uili == null) { return; } foreach (HtmlNode node in uili) { string href = node.Attributes["href"].Value; list += urlroot + href + ";"; }
另外,因为子页面经常是几十个,所以添加了自动定时刷新webBrowser地址和对页面代码进行分析的功能。
ThreadStart myStart; Thread TheStop; public readonly object MyLockWord = new object(); private void ToStop() { lock (MyLockWord) { this.Dispatcher.Invoke(delegate { btnNextGo_Click_1(null, null); }); Thread.Sleep(7000); this.Dispatcher.Invoke(delegate { btnAnalyUrl_Click_1(null, null); }); } }
最后整个程序的产物就是一个地址列表,如下:
http://music.baby611.com/music/2010/1/Tan.mp3
http://music.baby611.com/music/2010/1/iano.mp3
http://music.baby611.com/music/2010/1/ary.mp3
http://music.baby611.com/music/2010/1/Tons.mp3
http://music.baby611.com/music/2010/1/Thle.mp3
http://music.baby611.com/music/2010/1/Tsg.mp3
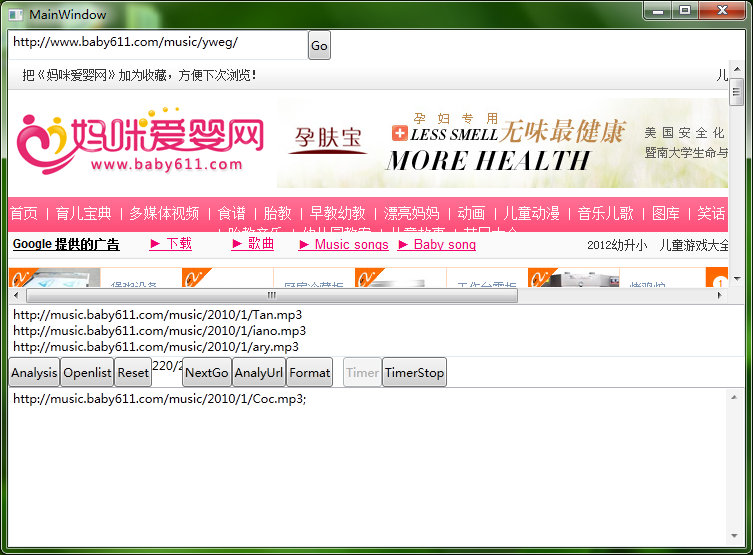
只要COPY整个进迅雷,就可以批量下载了。另外附上极为丑陋的界面一张,晚上熬了两个多小时,只做了功能,界面未做美化,以后有空再弄
吧,主要是歌曲列表可以拿到了。哈哈
以上为比较麻烦的一种网页内容获取方式,下面引用同事在做类似网页内容获取时所用到的方法:
/// <summary> /// 从网上获取指定URL的HTML源码 /// </summary> /// <param name="strURL">URL</param> /// <returns>HTML源码</returns> private static string GetHTMLbyWebRequest(string strURL) { string strRet = string.Empty; Encoding encoding = System.Text.Encoding.Default; WebRequest request = WebRequest.Create(strURL); request.Credentials = CredentialCache.DefaultCredentials; HttpWebResponse response = (HttpWebResponse)request.GetResponse(); if ("OK" == response.StatusDescription.ToUpper()) { //设置获取链接中网页的编码格式 switch (response.CharacterSet.ToLower()) { case "gbk": encoding = Encoding.GetEncoding("GBK"); break; case "gb2312": encoding = Encoding.GetEncoding("GB2312"); break; case "utf-8": encoding = Encoding.UTF8; break; case "big5": encoding = Encoding.GetEncoding("Big5"); break; case "iso-8859-1": encoding = Encoding.GetEncoding("UTF-8"); break; default: encoding = Encoding.UTF8; break; } Stream dataStream = response.GetResponseStream(); StreamReader reader = new StreamReader(dataStream, encoding); strRet = reader.ReadToEnd(); reader.Close(); dataStream.Close(); response.Close(); } else { return string.Empty; } return strRet; }

















 166
166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









