 Doc2Vec实战
Doc2Vec实战





 本文介绍Doc2Vec的原理及应用,通过IMDB电影评论数据集的情感分析案例,演示gensim库实现过程。实验结果显示,Doc2Vec能有效区分正面与负面评论。
本文介绍Doc2Vec的原理及应用,通过IMDB电影评论数据集的情感分析案例,演示gensim库实现过程。实验结果显示,Doc2Vec能有效区分正面与负面评论。
摘要:本文主要描述了一种文章向量(doc2vec)表示及其训练的相关内容,并列出相关例子。两位大牛Quoc Le 和 Tomas Mikolov(搞出Word2vec的家伙)在2014年的《Distributed Representations of Sentences and Documents》所提出文章向量(Documents vector),或者称句向量(Sentences vector),当然在文章中,统一称这种向量为Paragraph Vector,本文也将已doc2vec称呼之。文章中讲述了如何将文章转换成向量表示的算法。
1、Word2vec的基本原理
先简述一下Word2vec相关原理,因为本文要讲述的doc2vec是基于Word2vec思想的算法。w2v的数学知识还比较丰富,网络上相关资料也很多。如果要系统的讲述,我可能会涉及包括词向量的理解、sigmoid函数、逻辑回归、Bayes公式、Huffman编码、n-gram模型、浅层神经网络、激活函数、最大似然及其梯度推导、随机梯度下降法、词向量与模型参数的更新公式、CBOW模型和 Skip-gram模型、Hierarchical Softmax算法和Negative Sampling算法。当然还会结合google发布的C源码(好像才700+行),讲述相关部分的实现细节,比如Negative Sampling算法如何随机采样、参数更新的细节、sigmod的快速近似计算、词典的hash存储、低频与高频词的处理、窗口内的采样方式、自适应学习、参数初始化、w2v实际上含有两中方法等,用C代码仅仅700+行实现,并加入了诸多技巧,推荐初识w2v的爱好者得看一看。
Google出品的大多都是精品 ,w2v也不例外。Word2Vec实际上使用了两种方法,Continuous Bag of Words (CBOW) 和Skip-gram,如下图所示。在CBOW方法中,目的是将文章中某个词的上下文经过模型预测该词。而Skip-gram方法则是用给定的词来预测其周边的词。而词向量是在训练模型中所得到的一个副产品,此模型在源码中是为一个浅层的神经网络(3层)。在训练前,每一个词都会首先初始化为一个N维的向量,训练过程中,会对输入的向量进行反馈更新,在进行大量语料训练之后,便可得到每一个词相应的训练向量。而每一种模型方法都可以使用两种对应的训练方法Hierarchical Softmax算法和Negative Sampling算法,有兴趣的盆友可以自行查阅相关内容。
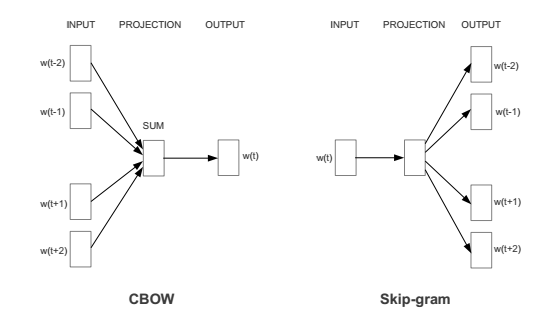
训练出的向量有一定的特性,即相近意义的词在向量空间上其距离也是相近。
有一个经典例子就是 V(‘king’) – V(‘man’) + V(‘woman’) ≈ V(‘queen’)
2、Doc2Vec的基本原理
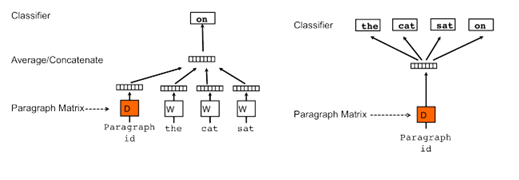
基于上述的Word2Vec的方法,Quoc Le 和Tomas Mikolov又给出了Doc2Vec的训练方法。如下图所示,其原理与Word2Vec非常的相似。分为Distributed Memory (DM) 和Distributed Bag of Words (DBOW),可以看出 Distributed Memory version of Paragraph Vector
(PV-DM)方法与Word2Vec的CBOW方法类似,Bag of Words version of Paragraph Vector (PV-DBOW)与Word2Vec的Skip-gram方法类似。不同的是,给文章也配置了向量,并在训练过程中更新。熟悉了w2v之后,Doc2Vec便非常好理解。具体细节可以看原文《Distributed Representations of Sentences and Documents》
3、gensim的实现
使用Doc2Vec进行分类任务,我们使用 IMDB电影评论数据集作为分类例子,测试gensim的Doc2Vec的有效性。数据集中包含25000条正向评价,25000条负面评价以及50000条未标注评价。
#!/usr/bin/python
import sys
import numpy as np
import gensim
from gensim.models.doc2vec import Doc2Vec,LabeledSentence
from sklearn.cross_validation import train_test_split
LabeledSentence = gensim.models.doc2vec.LabeledSentence##读取并预处理数据
def get_dataset():
#读取数据
with open(pos_file,'r') as infile:
pos_reviews = infile.readlines()
with open(neg_file,'r') as infile:
neg_reviews = infile.readlines()
with open(unsup_file,'r') as infile:
unsup_reviews = infile.readlines()
#使用1表示正面情感,0为负面
y = np.concatenate((np.ones(len(pos_reviews)), np.zeros(len(neg_reviews))))
#将数据分割为训练与测试集
x_train, x_test, y_train, y_test = train_test_split(np.concatenate((pos_reviews, neg_reviews)), y, test_size=0.2)
#对英文做简单的数据清洗预处理,中文根据需要进行修改
def cleanText(corpus):
punctuation = """.,?!:;(){}[]"""
corpus = [z.lower().replace('\n','') for z in corpus]
corpus = [z.replace('<br />', ' ') for z in corpus]
#treat punctuation as individual words
for c in punctuation:
corpus = [z.replace(c, ' %s '%c) for z in corpus]
corpus = [z.split() for z in corpus]
return corpus
x_train = cleanText(x_train)
x_test = cleanText(x_test)
unsup_reviews = cleanText(unsup_reviews)
#Gensim的Doc2Vec应用于训练要求每一篇文章/句子有一个唯一标识的label.
#我们使用Gensim自带的LabeledSentence方法. 标识的格式为"TRAIN_i"和"TEST_i",其中i为序号
def labelizeReviews(reviews, label_type):
labelized = []
for i,v in enumerate(reviews):
label = '%s_%s'%(label_type,i)
labelized.append(LabeledSentence(v, [label]))
return labelized
x_train = labelizeReviews(x_train, 'TRAIN')
x_test = labelizeReviews(x_test, 'TEST')
unsup_reviews = labelizeReviews(unsup_reviews, 'UNSUP')
return x_train,x_test,unsup_reviews,y_train, y_test##读取向量
def getVecs(model, corpus, size):
vecs = [np.array(model.docvecs[z.tags[0]]).reshape((1, size)) for z in corpus]
return np.concatenate(vecs)##对数据进行训练
def train(x_train,x_test,unsup_reviews,size = 400,epoch_num=10):
#实例DM和DBOW模型
model_dm = gensim.models.Doc2Vec(min_count=1, window=10, size=size, sample=1e-3, negative=5, workers=3)
model_dbow = gensim.models.Doc2Vec(min_count=1, window=10, size=size, sample=1e-3, negative=5, dm=0, workers=3)
#使用所有的数据建立词典
model_dm.build_vocab(np.concatenate((x_train, x_test, unsup_reviews)))
model_dbow.build_vocab(np.concatenate((x_train, x_test, unsup_reviews)))
#进行多次重复训练,每一次都需要对训练数据重新打乱,以提高精度
all_train_reviews = np.concatenate((x_train, unsup_reviews))
for epoch in range(epoch_num):
perm = np.random.permutation(all_train_reviews.shape[0])
model_dm.train(all_train_reviews[perm])
model_dbow.train(all_train_reviews[perm])
#训练测试数据集
x_test = np.array(x_test)
for epoch in range(epoch_num):
perm = np.random.permutation(x_test.shape[0])
model_dm.train(x_test[perm])
model_dbow.train(x_test[perm])
return model_dm,model_dbow##将训练完成的数据转换为vectors
def get_vectors(model_dm,model_dbow):
#获取训练数据集的文档向量
train_vecs_dm = getVecs(model_dm, x_train, size)
train_vecs_dbow = getVecs(model_dbow, x_train, size)
train_vecs = np.hstack((train_vecs_dm, train_vecs_dbow))
#获取测试数据集的文档向量
test_vecs_dm = getVecs(model_dm, x_test, size)
test_vecs_dbow = getVecs(model_dbow, x_test, size)
test_vecs = np.hstack((test_vecs_dm, test_vecs_dbow))
return train_vecs,test_vecs##使用分类器对文本向量进行分类训练
def Classifier(train_vecs,y_train,test_vecs, y_test):
#使用sklearn的SGD分类器
from sklearn.linear_model import SGDClassifier
lr = SGDClassifier(loss='log', penalty='l1')
lr.fit(train_vecs, y_train)
print 'Test Accuracy: %.2f'%lr.score(test_vecs, y_test)
return lr##绘出ROC曲线,并计算AUC
def ROC_curve(lr,y_test):
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
pred_probas = lr.predict_proba(test_vecs)[:,1]
fpr,tpr,_ = roc_curve(y_test, pred_probas)
roc_auc = auc(fpr,tpr)
plt.plot(fpr,tpr,label='area = %.2f' %roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.show()##运行模块
if __name__ == "__main__":
#设置向量维度和训练次数
size,epoch_num = 400,10
#获取训练与测试数据及其类别标注
x_train,x_test,unsup_reviews,y_train, y_test = get_dataset()
#对数据进行训练,获得模型
model_dm,model_dbow = train(x_train,x_test,unsup_reviews,size,epoch_num)
#从模型中抽取文档相应的向量
train_vecs,test_vecs = get_vectors(model_dm,model_dbow)
#使用文章所转换的向量进行情感正负分类训练
lr=Classifier(train_vecs,y_train,test_vecs, y_test)
#画出ROC曲线
ROC_curve(lr,y_test)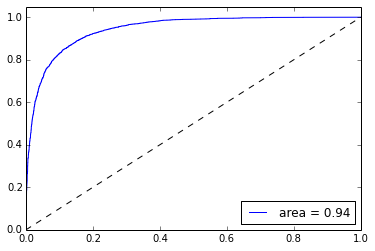
训练结果的,test分类精度为86%,AUC面积为0.94
————————————————————————————————————————
————————————————————————————————————————
相关链接:
[1] 安装Tensorflow(Linux ubuntu) http://blog.csdn.net/lenbow/article/details/51203526
[2] ubuntu下CUDA编译的GCC降级安装 http://blog.csdn.net/lenbow/article/details/51596706
[3] ubuntu手动安装最新Nvidia显卡驱动 http://blog.csdn.net/lenbow/article/details/51683783
[4] Tensorflow的CUDA升级,以及相关配置 http://blog.csdn.net/lenbow/article/details/52118116

















 5999
5999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









