







初次在VM上配置Hadoop,开了三台虚拟机,一个作namenode,jobtracker
另外两台机子作datanode,tasktracker
配置好后,启动集群
通过http://localhost:50700查看cluster状况
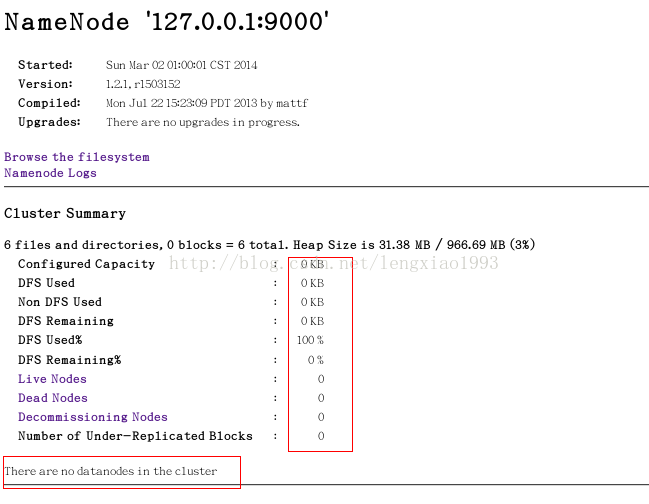
发现没有datanode
检查结点,发现datanode 进程已经启动,查看datanode机器上的日志
2014-03-01 22:11:17,473 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: Master.hadoop/192.168.128.132:9000. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
2014-03-01 22:11:18,477 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: Master.hadoop/192.168.128.132:9000. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
2014-03-01 22:11:19,481 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: Master.hadoop/192.168.128.132:9000. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
2014-03-01 22:11:20,485 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: Master.hadoop/192.168.128.132:9000. Already tried 3 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
2014-03-01 22:11:21,489 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: Master.hadoop/192.168.128.132:9000. Already tried 4 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
发现datanode 无法连接到master ,但是经过尝试,可以ping通,到结点查看,9000端口也处于监听状态,百思不得其解
最终发现core-site.xml 中
<property><name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
才意识到监听127.0.0.1端口,并不能被外机访问
改为主机名,一切正常
<property><name>fs.default.name</name>
<value>hdfs://Master.Hadoop:9000</value>
</property>














 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









