







Adaboost介绍
Adaboost是一种迭代算法,它的核心思想是在初始的权重数据分布下训练得到一个弱分类器(2类分类器),之后通过这个弱分类器判断准确率,对那些错判(即原本标签是1的因计算得到的0,或者相反情况)的样本的加大权重,而对于分类正确的样本,降低其权重,这样被分错的样本就被突出出来,下次训练就会更多考虑这些被错分的样本,因此得到一个新的样本分布(样本权重都被更新了)。在新的分布下,再进行训练得到一个弱分类器,周而复始得到N个检测能力一般的弱检测器。这些弱检测器只比随机猜测好一点,对于二类问题来说只是比50%的猜测好一点。但是通过一定算法把这些检测能力很弱的分类器融合起来,就会得到一个分类能力很强的强分类器。使用Adaboost分类器可以把那些不重要训练数据权重减弱甚至删除,而把那些关键的数据放在训练的最上层。理论证明,只要每个简单分类器的分类能力比随机猜测好点,当简单分类器数量趋向于无穷时,强分类器的错误率也将趋于零。
Adaboost结构
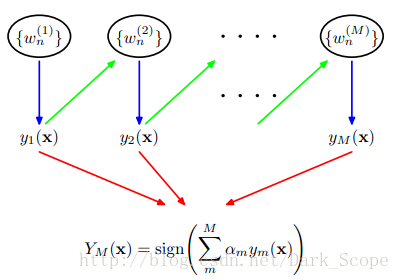
这就是Adaboost的结构,最后的分类器YM是由数个弱分类器(weak classifier)组合而成的,相当于最后m个弱分类器来投票决定分类,而且每个弱分类器的“话语权”α不一样。
Adaboost算法流程
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例 ,而实例空间
,而实例空间 ,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
Adaboost的算法流程如下:
- 步骤1. 首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权重:1/N。

- 步骤2. 进行多轮迭代,用m = 1,2, ..., M表示迭代的第多少轮
a. 使用具有权值分布Dm的训练数据集学习,得到基本分类器:
b. 计算Gm(x)在训练数据集上的分类误差率

由上述式子可知,Gm(x)在训练数据集上的 误差率em就是被Gm(x)误分类样本的权值之和。
c. 计算Gm(x)的系数,am表示Gm(x)在最终分类器中的重要程度(目的:得到基本分类器在最终分类器中所占的权重):
d. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代由上述式子可知,em <= 1/2时,am >= 0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。

使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“聚焦于”那些较难分的样本上。
其中,Zm是规范化因子,使得Dm+1成为一个概率分布:

- 步骤3. 组合各个弱分类器

从而得到最终分类器,如下:

由于adaboost算法是一种实现简单,应用也很简单的算法。Adaboost算法通过组合弱分类器而得到强分类器,同时具有分类错误率上界随着训练增加而稳定下降,不会过拟合等的性质,应该说是一种很适合于在各种分类场景下应用的算法。














 6848
6848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









