






摘要:元学习是一种技术,其目的在于理解什么类型的算法解决什么类型的问题。相比之下,聚类是基于对象的相似性把一个数据集划分几个簇,不需要对象类标签的先验知识。本文提出了基于无标签对象特征的提取,使用元学习推荐出聚类算法。基于将要被计算的聚类问题的特征以及不同聚类算法的排序,从而元学习系统对于聚类问题可以精确的推荐出最好的算法。
关键字:聚类,算法推荐,排序,元学习
1.介绍
当今大量的信息被表示和存进行后验分析。研究者开始致力于开发出不同的方法从数据中提取知识;使用这些方法的过程被称之为数据挖掘。当今被各种算法特征化的数据挖掘工具从而能解决每一个数据挖掘任务。然而,这个过程缺少选择最好的算法解决一个给定的数据挖掘问题的指导。
元学习领域以发现哪些问题特征有助于一个更好的或更坏的算法性能,并且以此,为解决一个给定的问题推荐出最适当的算法。为获得这个目标,元学习建立了两个关键的集合:(1)元属性:一类问题的实例的共同特征集合,像对象的数量和二元属性的数量,以及其他的;(2)排序:基于一个性能度量指标,被应用到相同问题的一些算法排序位置的集合。通过这两个集合一个模型被创建,当应用到其他的没有被用做训练的问题时基于被提出的元属性从而推荐出算法的排序。
对于分类任务数据挖掘和元学习之间的联系已经被广泛的研究了。然而,对于聚类任务的研究可得的文献很少。例如,没有研究对于无监督学习问题,例如聚类,哪个特征集最好。
在探讨聚类问题的算法推荐时,执行的实验是基于分类问题相关文献中描述的元属性。尽管如此,这里将选择的特征将不要求类标签的知识,因此基于分类使我们的设计的方法可以泛化到聚类任务。
论文组织如下:第二部分简单的介绍关于元学习的理论背景。第三部分解释了实验中使用的方法并且给出了实验结果。论文在第四部分进行了总结,讨论了实验结果和和我们提出的方法的适应性。
2.元学习
元学习是一个关于学习的学习,例如,应用元学习必须学习机器学习算法的行为以发现最好的算法。在1994年,EU ESPRIT 工程StatLog扩展了这个概念,使算法的性能和对象的特征关联到到分类问题上。
元学习与提取探索元知识的过程紧密相关,从一个算法的学习过程中提取的元知识可以被假设成不同的形式,并且当被应用到一个问题时可以被定义成任何类型的知识。
元知识,也被称做元数据,由元属性和排序组成。元属性是从问题中提取的特征,例如, 为了特征化分类问题,StatLog工程基于简单度量、统计学和信息论提出了十六个元属性的集合。排序即是当算法的性能通过一个度量在相同问题上被度量时算法占据的位置,例如,有性能值最好的算法占据了第一个位置,第二个最好的占据了第二个位置,等等。
元算法负责学习元属性和排序间关系,并且使用这个得到的知识计算算法的排序。典型的机器学习算法经常被用作元算法,例如决策树,神经网络,基于实例的学习,以及其他的。
对于元学习系统的概念模型由三个主要模块构造:(1)特征提取模块:提取特征(元属性)负责特征化和相互区分问题;(2)算法评估模块:在给定的问题上使用预先定义的评估度量生成算法的排序;(3)应用模块:使用一个元算法负责算法的排序。
元学习系统的概念模型
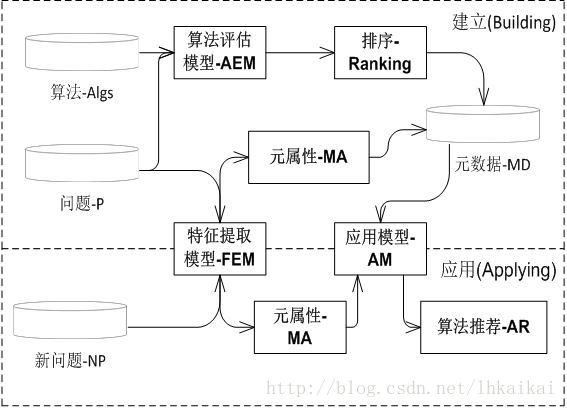
3.实验
本文的目的是研究应用元学习技术到聚类问题的适应性,聚类问题可以通过从无标签数据中提取的元属性进行特征化。实验使用来自于相关文献的数据集和为分类问题定义的数据特征预测聚类算法的排序。
3.1数据集
实验使用的问题集合是30个来自UCI机器学习中心的数据集,有缺失值的对象被移除。选择的数据集如下:哈伯曼的存活率、气球、莺尾花、汽车评估、浴室、乳腺癌、啤酒等等。
3.2元属性
目前为止没有固定的工作研究哪些元属性应该被使用以特征化在聚类任务中数据集。聚类算法通常不能使用对象标签的先验信息,本文研究中将要被提取的是无关虑对象的类标签的元属性。
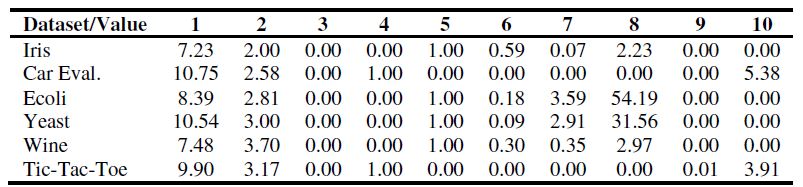
被选择的是基于StatLog和METAL工程以及相关论文的元属性,元属性被规范化到[0, 1]。下表中解释了一个元属性的样本,被选择的元属性是:(1)Log2对象的数量(2)Log2属性的数量;(3)二元属性的比例;(4)离散属性的比例;(5)连续属性的数量;(6)连续属性间的平均绝对相关性;(7)连续属性的平均偏度;(8)连续属性的平均斜度;(9)离散属性间的平均绝对聚集度;(10)离散属性的平均熵。
表1: 对于一些数据集的元属性
3.3聚类算法
本文的研究评估了下列的聚类算法:K-平均(KM);单连接(SL);全连接(CL);中心连接(ML)和自组织特征映射(SOM)。这儿使用的自组织特征映射是二维的,神经元的数量等于数据集簇的数量。所有的算法都使用欧几里德距离作为相异性度量标准。
要评估的聚类结果使用FBCubed度量,计算如下:

其中n是数据集中对象的数量,CL(i)是与对象i在相同的簇并且与对象i有相同的类标签;Cluster(i)是与对象i在相同的簇中的对象数量。Label(i)与对象i有相同的标签的对象的数量。
算法在每一个数据集被执行30次,其性能通过FBC的结果值得到。排序被建立基于每个数据集上每个算法的最好性能,并被用作预测值。
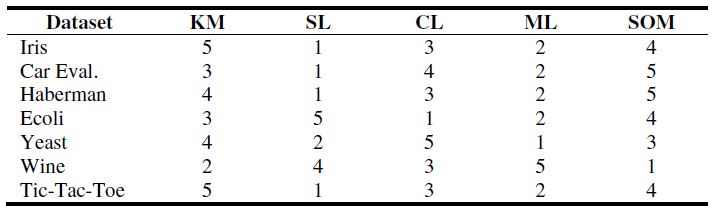
表2显示了对于一些数据集所有聚类算法的最好FBC结果,表3显示了对于相同数据集的预测表,可以发现具有最高FBC值的聚类算法占据了对于一个数据集排序中的第一个位置,并且第二个最高值占据了第二个位置,等等。
表2:最好的FBC结果值对于聚类结果
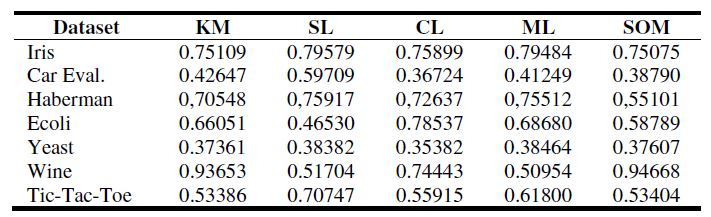
表3:被建立有排序值的预测表
3.4元算法
元算法负责学习元属性和排序之间的关系,本文中将使用有不同的学习机制的4个机器学习算法做为不同的元算法:K-最近邻(KNN);多层感知神经网络(MLP);决策树(CART);和朴素贝叶斯(NB)。
为了评估预测的质量,将使用斯皮尔曼秩相关性(SRC),度量成对的有序的值之间的相关性。SRC给定的结果范围在[-1, 1],其中+1意味着两个排序是相等的,-1意味着它们是相反的。
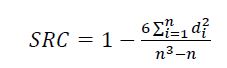
其中n是秩的大小,di是真实的和预测排序值在第i个位置的差异。
为了在元算法之间比较结果,对于KNN和MLP算法一个参数化的估算被执行以选择最好的参数值。
在KNN算法中,初始参数k确定了被考虑的邻居的数量以计算输出。进行了一个实验k的变化从[1, 6],与其他的元算法比较时选择k=2。
在MLP算法中, 使用不同数量的隐藏层神经元,神经元的数量从[1, 10],与其他的元算法比较时选择选择6作为隐藏层神经元的数量。
3.5结果
为了获得每一个元算法在预测和真实的排序间SRC值,进行了30次的10折交叉验证。表4显示了对于所有的元算法的最终的推荐的SRC值的平均值和标准偏差。图2解释了对于所有的元算法的SRC的方差。
表4: 对于排序推荐的斯皮尔曼秩相关性
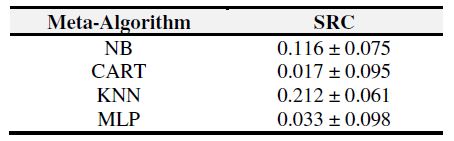
图2: 元算法SRC值盒图
对元算法进行里尔福斯测试以确定数据的正态性。里尔福斯测试的样本来自没有指定期望值和分布的方差的一个均匀分布总体的的空假设。使用0.01的显著性水平,所有的结果被认为来自一个均匀的分布。
为了验证结果平均值之间的差别,一个t-测试被执行。t-测试验证来自具有相等平均值的正态分布样本的空假设。通过KNN元算法获得的结果具有0.01显著性水平被认为是不同的。
SRC有它的显著性测试表的使用秩间没有相关性的空假设,例如,假设验证如果统计上相关性等于0。备择假设(H1)将是一个正相关(SRC>0)或者一致的在排序之间(尾测试)。分析KNN元算法真实的与推荐的排序之间的SRC;对于最好的SRC有0.05的显著性水平,对于平均SRC有0.25的显著性水平。
3.6对于新的数据集运行元学习系统
在设计了完整的元学习系统之后,用它为一个新的、没有看到的数据集推荐出一个算法。为了解释, 使用了哈伯曼生存率数据集。表5显示了从数据中提取的元属性。系统使用这些元属性为每一个聚类算法推荐出一个排序(表6)。因此这个推荐系统在新的问题上不需要运行所有的算法提供了关于算法的性能的信息。
表5: 从新问题中提取的元属性

表6:对于新问题的排序推荐

4.总结
本文研究的目的是分析应用元学习技术到聚类问题时的适应性。为了达到这个目的,开发了一个系统负责从问题中提取元属性、获得选取的算法的排序(建立元知识)、并使用元算法创建一个预测模型。最终,这个元学习系统对于一个新问题只要从中提取元属性就可以进行聚类算法推荐。
现实中的聚类问题,数据标签不是已知的先验知识,提前推荐出可能的聚类算法变得很重要。对于每个类型的问题基于其特征,使用元学习可以为聚类问题选择一个合适的算法提供指导,
通过元学习系统得到的结果表明了元属性的集合可以在问题特征(元属性)和聚类算法的排序之间形成映射。本文中被使用的元属性具有独立与对象的类标签的主要性质,从而元学习系统可以应用到任何聚类问题。保持这个性质,通过提取新的本质特征扩展这个集合可能会得到更好的预测。














 3304
3304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









