







第一阶段:Spark streaming、spark sql、kafka、spark内核原理(必须有一个大型项目经验);
第二阶段:spark运行的各种环境,各种故障的解决,性能优化(精通spark内核、运行原理);
第三阶段:流处理、机器学习为鳌头,需要首先掌握前两个阶段的内容;
跟随王家林老师的零基础讲解,注重动手实战,成为spark高数,笑傲大数据之林!
本期内容:
1 通过手动绘图的方式解密Spark内核架构
2 通过案例来验证Spark内核架构
3 Spark架构思考
一、详细剖析Spark运行机制
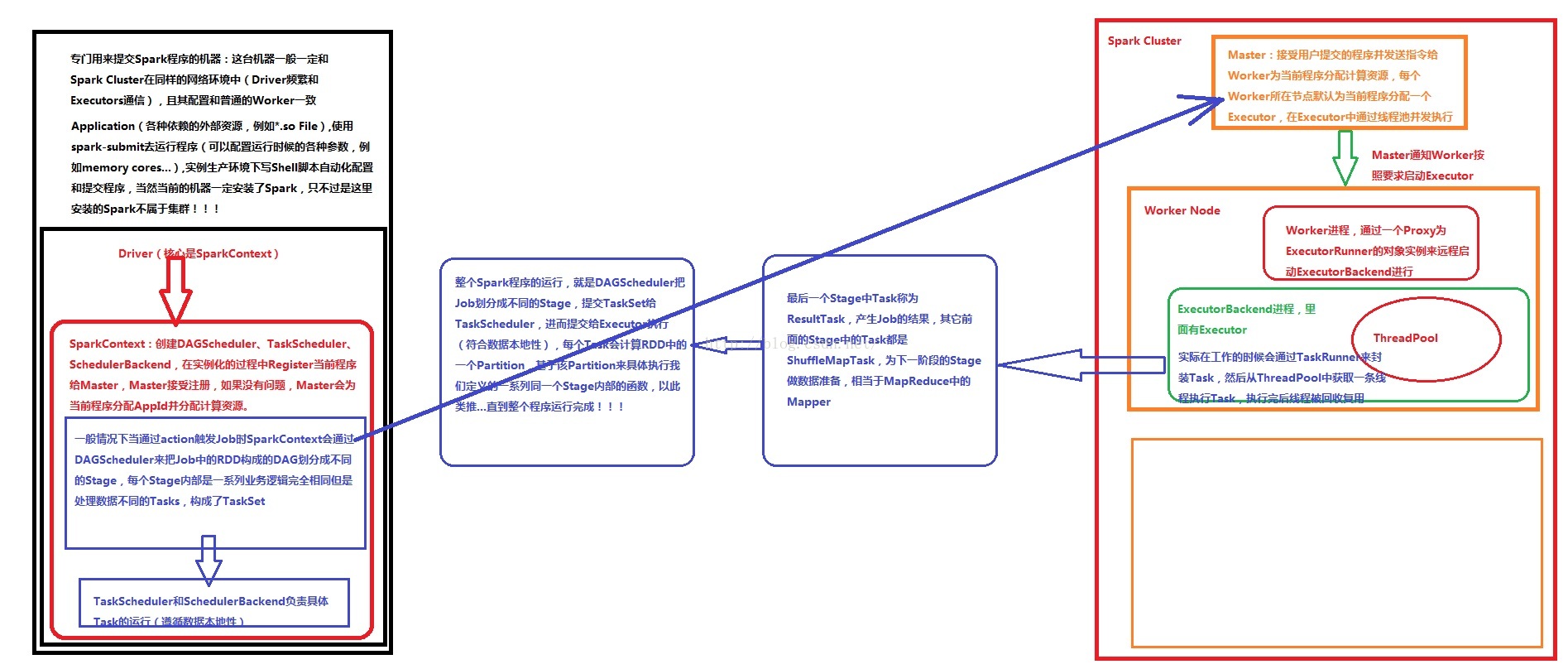
(1)Driver端架构
Driver部分代码包含了SparkConf+SparkContext,基本一切应用程序代码由Driver端的代码和分布在集群其他机器上的Executor代码组成(textFile flatMap map),Executor(executor是运行在worker上的进程里的对象)是由线程池并发执行和线程的覆用,线程处理task任务,task从disk和mem上读取数据。
SparkApplication的运行不依赖于ClusterManager,也就是说运行时不需要ClusterManager的参与(粗粒度分配资源即一次性分配完成)。
Driver运行程序的时候创建了SparkContext并且有main方法,SparkContext本身是程序调度器(分高低度调度器DAGScheduler和TaskScheduler)。Driver端是用来提交Spark程序的机器,这台机器一般和Spark cluster集群在相同的网络环境下,因为要保证Driver和Executor进行频繁的通信,并且Driver的机器配置基本和Worker相同,Driver的机器安装了Spark,但不属于Spark集群的范围。Application提交的时候使用spark-submit(可配置运行时的参数MEM、CPU等),而生产环境下使用自动化shell脚本提交。
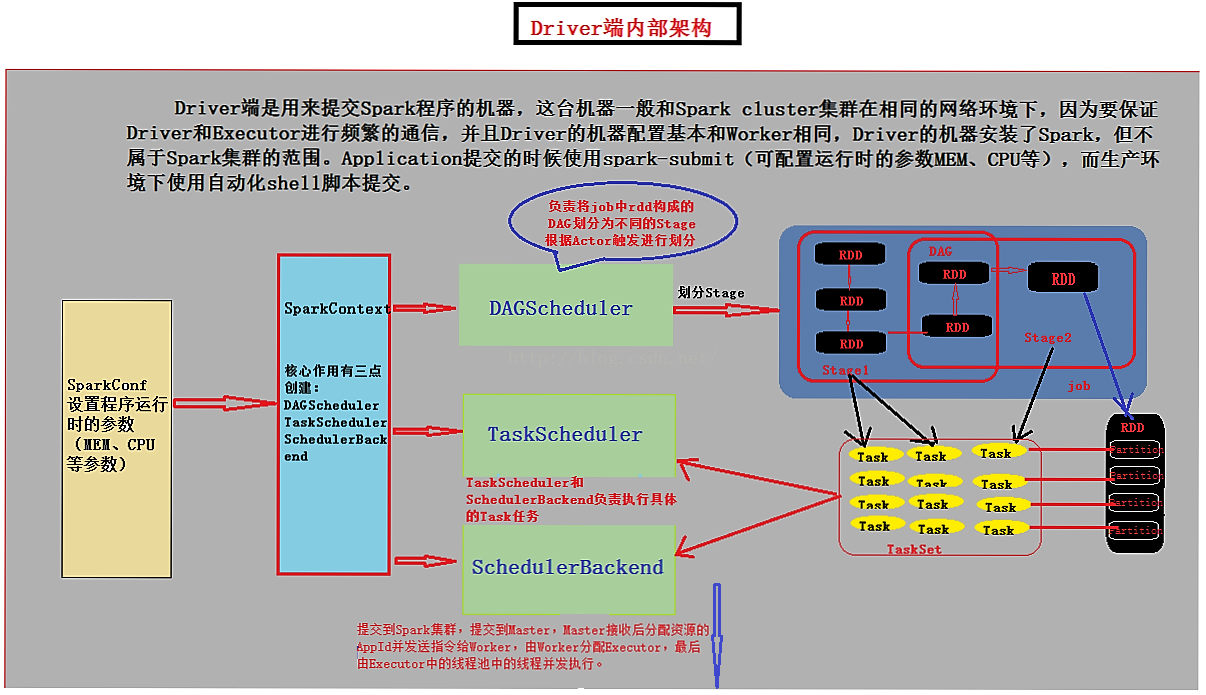
首先Driver端的应用程序包含了Executor和Driver代码部分。应用程序本身Driver代码(SparkConf和SparkContext),SparkConf中包含了设置程序名称setAppName、setMaster等,SparkContext包含了DAGScheduler、TaskScheduler、SchedulerBackend以及SparkEnv,Executor代码包含了对业务逻辑的具体实现的代码(map、flatmap、ReduceByKey等)。
可以看出Driver端由SparkConf中将程序运行的配置信息传给SparkContext的上下文,由SparkContext创建DAGScheduler(高层调度器)、TaskScheduler(底层调度器:负责一个作业内部运行)、SchedulerBackend(负责握住计算资源),实例化的过程中注册当前程序给Master。然后DAGScheduler根据Actor触发job,SparkContext通过DAGScheduler将job中RDD形成的DAG有向无环图划分为不同的Stage(Task具体运行于哪台机器上?就是在划分Stage的时候确定,这里就是根据数据本地行定位发送的Executor位
置),TaskScheduler会将不同Stage中的一系列的Task发送到对应的Executor去执行,具体划分的的过程在前面WordCount背后的数据流中详细进行了分析描述,即不同的(map、flatmap、ReduceByKey)函数RDD api产生的RDD形成的DAG进行划分,得到不同的Stage,而每个Stage都由相同业务逻辑,不同处理数据的Task组成,Task又一一对应RDD中的每个Partition。将划分Stages得到的TaskSet提交到TaskScheduler,进而提交给executor执行。
Driver端划分好Stage后,提交到Spark集群,即提交到Master由Master接收后分配资源的AppId并发送指令给Worker,然后Worker分配Executor,最后由Executor(并发处理数据分片)中的线程池中的线程并发执行。
(2)Spark集群运行架构
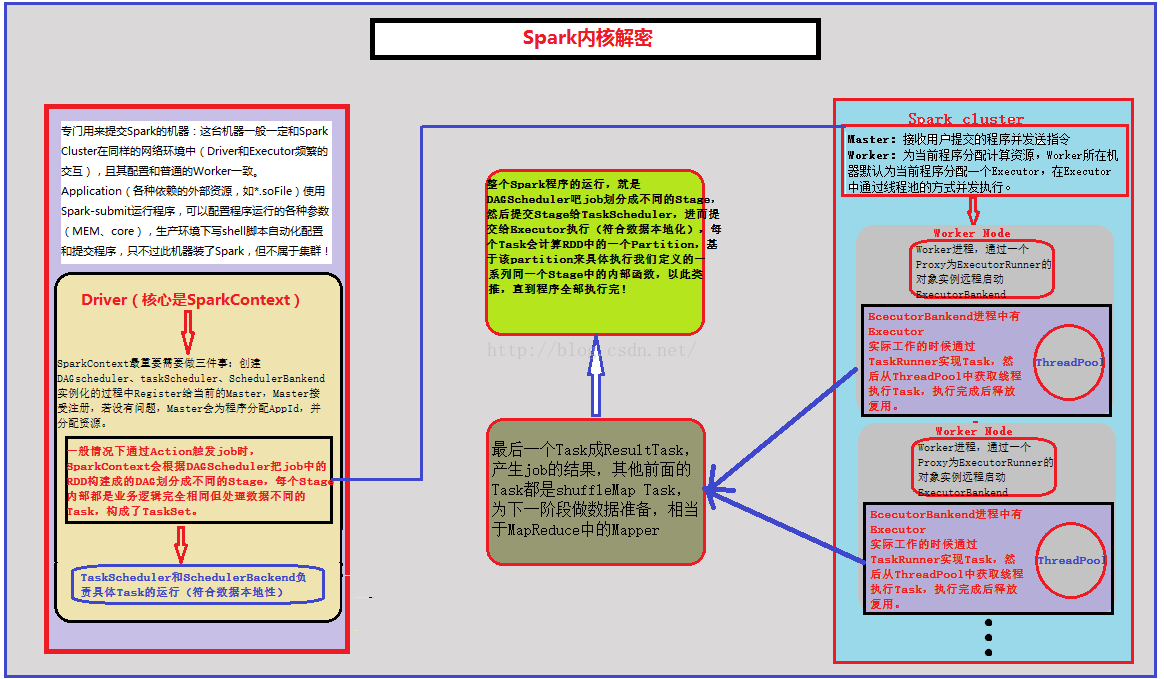
Driver端提交程序Tasks后,由Master检测没有问题便进行资源的分配和AppId的分配,然后发送指令给Worker节点,Worker节点默认会分配一个Executor,然后在Executor的线程池中进行并发执行。
Master收到提交的程序,Master根据以下三点为程序分配资源:
1,spark-env.sh和spark-defaults.sh
2,spark-submit提供的参数
3,程序中SparkConf配置的参数
Worker管理当前Node的资源,并接受Master的指令来分配具体的计算资源(Executor)。Worker进程通过一个Proxy(代理句柄)为ExecutorRunner的对象实例远程启动ExecutorBackend进程,实际工作的时候会通过TaskRunner(一个Runner的接口,线程一般会用Runner的接口封装业务逻辑,有run方法所以可以回调)来封装Executor接收到的Task,然后从ThreadPool中获取一个线程执行,执行完成后释放并覆用。
在最后一个Stage前的其他Stage都进行shuffleMapTask,此时是对数据进行shuffle,shuffle的结果保存在Executor所在节点的本地文件系统中,最后一个Stage中的Task就是ResultTask,负责结果数据生成。Driver会不断发送Task给Executor进行执行,所以Task都正确执行,到程序运行结束;若超过执行次数的限制,或者没有执行时会停止,待正确执行后会进入下一个stage,若没有正确执行成功,高层调度器DAGSchedular会进行一定次数的重试,若还是执行不成功就意味着整个作业的失败。
每个Task具体执行RDD中的一个Partition,(默认情况下为128M,但最后一个记录跨两个Block)基于该Partition具体执行我们定义的一系列内部函数,直到程序执行完成。
二、Spark运行架构概要
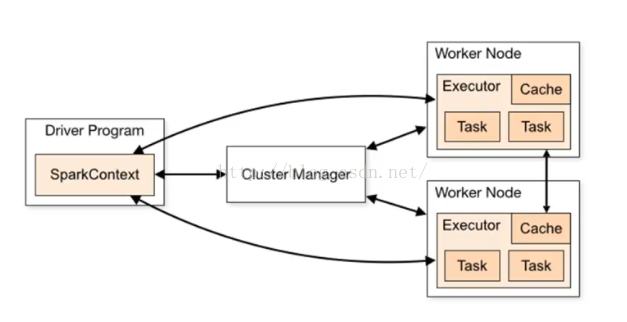
首先用户创建SparkContext,新创建的SparkContext会根据编程时设置的参数或系统默认的配置连接到ClusterManager上,ClusterManager会根据用户提交时的设置(如:占用CPU、MEN等资源情况),来为用户程序分配计算资源,启动相应的Executor;而Driver根据用户程序调度的Stage的划分,即高层调度器(RDD的依赖关系),若有宽依赖,会划分成不同的Stage,每个Stage由一组完全相同的任务组成(业务逻辑相同,处理数据不同的Tasks组成),该Stage分别作用于待处理的分区,待Stage划分完成和TaskSet创建完成后,Driver端会向Executor发送具体的task,当Executor收到task后,会自动下载运行需要的库、包等,准备好运行环境后由线程池中的线程开始执行,因此Spark执行是线程级别的。
Hadoop运行比Spark代价大很多,因Hadoop中的MapReduce运行的JVM虚拟机不可以复用,而Spark运行的线程池中的线程可以进行复用。
执行Task的过程中,Executor会将执行的Task汇报给Driver,Driver收到Task的运行状态情况后,会根据具体状况进行更新等。
三、Spark内部组件简介
1、Task划分:Task根据不同的Stage的划分,会被划分为两种类型
(1)shuffleMapTask,在最后一个Stage前的其他Stage都进行shuffleMapTask,此时是对数据进行shuffle,shuffle的结果保存在Executor所在节点的本地文件系统中;
(2)第二种Task:ResultTask,负责生成结果数据;
Driver会不断发送Task给Executor进行执行,所以Task都正确执行或者超过执行次数的限制,或者没有执行时会停止,待正确执行后会进入下一个stage,若没有正确执行成功,高层调度器DAGSchedular会进行一定次数的重试,若还是执行不成功就意味着整个作业的失败。
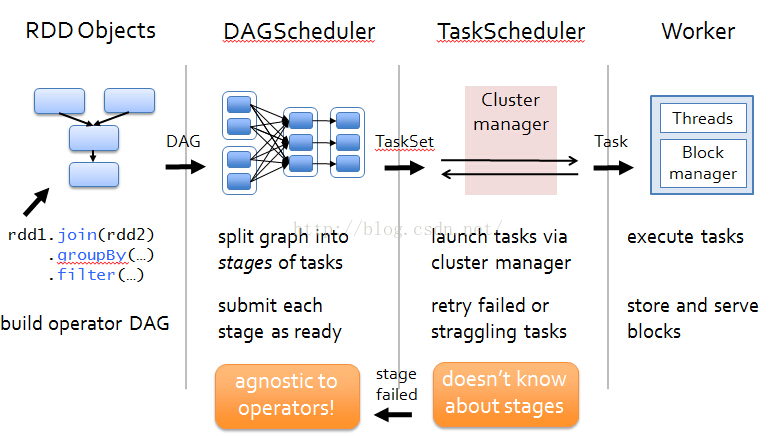
2、DAGScheduler:负责将job中rdd构成的DAG划分为不同的Stage
3、Worker:集群运行节点,Worker上不会运行Application的程序,因为Worker管理当前Node的资源资源,并接受Master的指令来分配具体的计算资源Executor(在新的进程中分配),Worker不会向Master发送Worker的资源占用情况(MEN、CPU),Worker向Master发送心跳,只有Worker ID,因为Master在程序注册的时候已经分配好了资源,同时只有故障的时候才会发送资源的情况。
4、Job:包含了一系列Task的并行计算。Job由action(如SaveAsTextFile)触发的,其前面是若干RDD,而RDD是Transformation级别的,transformation是Lazy的,因为是Lazy的所以不计算往前推(如:WordCount中collect触发了job,执行的时候由mapPartitionRDD往前推到hadoopRDD,之后开始一步步执行),若两个RDD之间回数的时候是窄依赖的话就在内存中进行迭代,也是Spark之所以快的原因,不是因为基于内存,因为其调度和容错及其他内容。
5、宽依赖和窄依赖
在RDD中将依赖划分成了两种类型:窄依赖(narrow dependencies)和宽依赖(wide dependencies)。
窄依赖是指父RDD的每个分区都只被子RDD的一个分区所使用(一对一);
宽依赖就是指父RDD的分区被多个子RDD的分区所依赖(一对多)。
例如,map就是一种窄依赖,而join则会导致宽依赖(除非父RDD是hash-partitioned
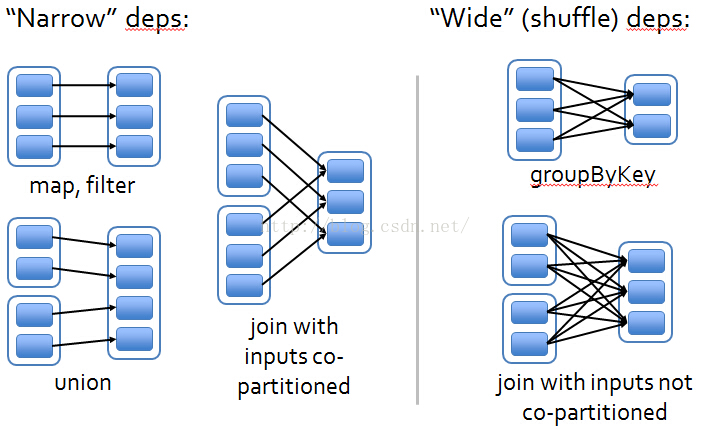
这种划分有两个用处。首先,窄依赖支持在一个结点上管道化执行。例如基于一对一的关系,可以在filter之后执行map。其次,窄依赖支持更高效的故障还原。因为对于窄依赖,只有丢失的父RDD的分区需要重新计算。而对于宽依赖,一个结点的故障可能导致来自所有父RDD的分区丢失,因此就需要完全重新执行。因此对于宽依赖,Spark会在持有各个父分区的结点上,将中间数据持久化来简化故障还原,就像MapReduce会持久化map的输出一样。
注:一个Application里面可以有多个Jobs 一般一个action对应一个job。;Stage内部是RDD构成的,RDD内部是并行Task的集合
(注:有任何有误的地方请不吝指出,方便大家学习)














 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









