







最近工作需要,摸索着搭建了Hadoop 2.2.0(YARN)集群,中间遇到了一些问题,在此记录,希望对需要的同学有所帮助。
本篇文章不涉及hadoop2.2的编译,编译相关的问题在另外一篇文章《hadoop 2.2.0 源码编译笔记》中说明,本篇文章我们假定已经获得了hadoop 2.2.0的64bit发行包。
由于spark的兼容问题,我们后面使用了Hadoop 2.0.5-alpha的版本(2.2.0是稳定版本),2.0.5的配置有一点细微的差别,文中有特别提示
1. 简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。 MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心.HDFS在集群上实现分布式文件系统MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。介绍一下安装hadoop 2.2.0的几个步骤
2.安装JDK(公司服务器已经装好)
3.编辑hosts文件 增加域名
4.关闭防火墙
5.部署免密码ssh
6.载hadoop2.2 并解压
7.修改配置文件
8.分发hadoop到各个节点(复制7个配置文件到从节点服务器)
9.启动集群
这里我们搭建一个由三台机器组成的集群:
10.19.106.112 主
10.19.106.113 从
10.19.106.114 从
系统版本
CentOS 6.4 64bituname -a
Linux ** 2.6.32_1-7-0-0 #1 SMP *** x86_64 x86_64 x86_64 GNU/Linux
新建用户
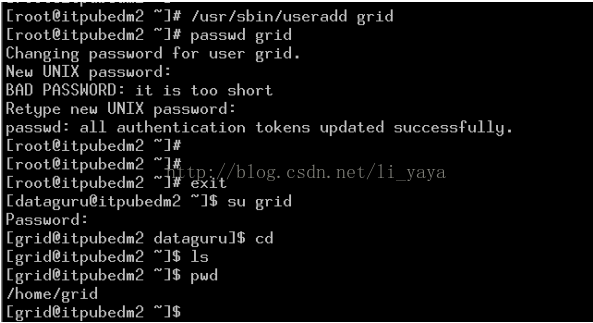
cat /etc/group 可以查看用户所属组
该用户会在目录 /home/下生成 grid文件夹
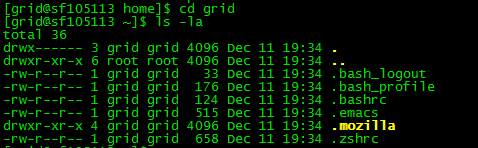
以上文件都是grid文件夹隐藏的系统文件
JAVA环境
安装jdk(建议每台机器的JAVA_HOME路径信息相同)
注意:这里选择下载jdk并自行安装,而不是通过源直接安装(apt-get install)下载jkd(http://www.Oracle.com/technetwork/java/javase/downloads/index.html)
对于32位的系统可以下载以下两个Linuxx86版本(uname -a 查看系统版本)64位系统下载Linux x64版本 (即x64.rpm和x64.tar.gz)
安装jdk(这里以.tar.gz版本,32位系统为例)
安装方法参考http://docs.oracle.com/javase/7/docs/webnotes/install/linux/linux-jdk.html
选择要安装java的位置,如/usr/目录下,新建文件夹java(mkdir java)
将文件jdk-7u40-linux-i586.tar.gz移动到/usr/java解压:tar -zxvfjdk-7u40-linux-i586.tar.gz
删除jdk-7u40-linux-i586.tar.gz(为了节省空间)至此,jkd安装完毕,下面配置环境变量
打开/etc/profile(vim/etc/profile)在最后面添加如下内容:
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib
export JAVA_HOME PATH CLASSPATH
source /etc/profile 使其配置文件生效
验证是否安装成功:java – version
【注意】每台机器执行相同操作,最后将java安装在相同路径下(不是必须的,但这样会使后面的配置方便很多)
编辑hosts文件
增加域名 设置/etc/hosts文件(每台机器上都要设置),添加如下内容
10.19.106.112 sf106112 10.19.106.113 sf106113
10.19.106.114 sf106114
关闭防火墙
每台服务器都需要关闭 以下是我自己测试通过的命令
/etc/init.d/iptables stop 关闭防火墙。
chkconfig iptables off 关闭开机启动。以下方法是我摘自别人写的内容 本人没有测试过 不过觉得是行得通的
严格来说,应该是打开某些对应的端口。为了简单起见,我们这里关闭selinux和iptalbes.
关闭selinux的方法setenforce 1 设置SELinux 成为enforcing模式
setenforce 0 设置SELinux 成为permissive模式
如果永久关闭,编辑/etc/selinux/config
SELINUX=disabled
关闭iptables的方法
service iptables stop
service ip6tables stop
如果需要永久关闭(各个运行级别)
chkconfig iptables off
chkconfig ip6tables off
部署免密码ssh
以下步骤必须要是 grid用户登入进行 因为如果是root用户 就会在root 文件夹下生成.ssh文件
1. ssh-keygen -t rsa 执行此命令会在112 服务器 /home/grid/ 下生成
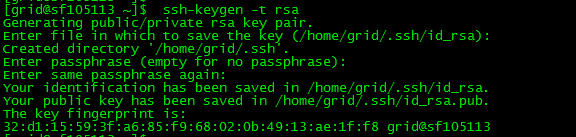
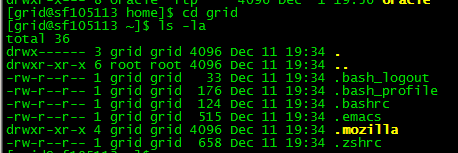
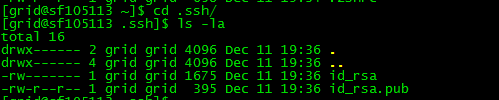
id_rsa.put 就是公钥 key , id_rsa 是私钥key
以上步骤首先要在3台服务器同时进行操作都要生成.ssh文件
此时我们3台服务器 在/home目录下都会有grid文件夹 /home/grid/.ssh/ 里有各自的KEY
有这样的前提我们就可以做设置了
scp -P 22022 -r root@10.19.106.113:/home/grid/.ssh/id_rsa.pub /home/grid/.ssh/authorized_keys以上命令是代表从 113服务器把KEY值复制到本机目录 /home/grid/.ssh/ 并生成文件 authorized_keys
同时也要把114和本机(112服务器)的key值都要添加进 authorized_keys里
如下:

这样就能在112服务器上 对本机 113 114 进行ssh了
同理要在 113 114服务器上也要生成 authorized_keys 并且要记录3台服务器的KEY值
可以先在各自服务器使用命令 cp id_rsa.pub authorized_keys 生成文件 authorized_keys 然后可以用复制粘贴的方式保存退出只要每台服务器都要有3个公钥就OK了
最终改完之后要切换至root用户 重启SSH服务命令使其生效:service sshdrestart
只有这样3台服务器才能真正做到互相 无密码ssh了
这里端口号不对 应要改成 ssh -p 22022 10.19.106.113 就会链接成功了 对于这个问题我在做最终测试的时候也困扰到了 最后我在 /sbin/slaves.sh 做了修改才解决的
这里我在后面再做介绍
下载hadoop2.2 并解压
以下是目前最新版本 15M的是没有进行编译过的 140M的是进行编译的 这里我是直接从别的地方下载的 2.2版本进行部署的 由于 hadoop 集群中每个机器上面的配置基本相同,所以我们先在 namenode也就是112服务器上面进行配置部署,然后再复制到其他节点。所以这里的安装过程相当于在每台机器上面都要执行。
但需要注意的是集群中64位系统和32位系统的问题。
注意:每台机器的安装路径要相同!!
这里我是解压到grid文件夹也是在grid用户里操作的
这里我们需要注意的hadoop的环境变量是可配置可不配置 java变量是必须要配置的
修改配置文件之前,需要在hadoop-2.2.0本地文件系统创建以下文件夹:
namdata
tmp
这里要涉及到的配置文件有7个:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml以上个别文件默认不存在的,可以复制相应的template文件获得。
配置文件1:hadoop-env.sh
修改JAVA_HOME值(exportJAVA_HOME=/usr/java/jdk1.7.0_40)
配置文件2:yarn-env.sh
修改JAVA_HOME值(exportJAVA_HOME=/usr/java/jdk1.7.0_40)
配置文件3:slaves(这个文件里面保存所有slave节点)
写入以下内容:
sf106175
sf106178
配置文件4:core-site.xml
</pre><p></p><p></p><p style="background:white"><span style="color:#333333;"><span style="font-family:宋体;">配置文件</span></span><span style="color:#333333;">5</span><span style="color:#333333;"><span style="font-family:宋体;">:</span></span><span style="color:#333333;">hdfs-site.xml</span></p><p style="background:white"><span style="color:#333333;"></span></p><pre code_snippet_id="549582" snippet_file_name="blog_20141211_3_5139463" name="code" class="html"><configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sf106172:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/grid/hadoop-2.2.0/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/grid/hadoop-2.2.0/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置文件6:mapred-site.xml (这个文件默认是没有的 我是手动创建一个这样的文件再添加内容的)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>sf106172:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>sf106172:19888</value>
</property>
</configuration>配置文件7:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>sf106172:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sf106172:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sf106172:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sf106172:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sf106172:8088</value>
</property>
</configuration>这样呢以上7个文件都已经修改好了 我的建议是把这7个文件直接覆盖到另外2个节点服务器上以确保完全一致的效果
下面我们就可以做验证hadoop是否可以正常测试部署了 这里前提我们必须是 grid用户登入的不然就会ssh不了
进入安装目录: cd /home/grid/hadoop-2.2.0/
1.格式化namenode:./bin/hdfs namenode –format
我做这一步的时候它会提示没有权限name文件夹写的权限
我就干脆把它权限放到最大 执行命令 chmod -R 777 /home/grid/hadoop-2.2.0/name/
于是乎我再次格式化就可以了
2.启动hdfs: ./sbin/start-dfs.sh
此时在112服务器上面运行的进程有:namenode,secondarynamenode
113和114上面运行的进程有:datanode
3.启动yarn: ./sbin/start-yarn.sh
此时在112上面运行的进程有:namenode,secondarynamenode,resourcemanager
113和114上面运行的进程有:datanode,nodemanaget
执行 ./sbin/start-all.sh
该命令会依次启动hdfs和yarn,分别调用start-hdfs.sh和start-yarn.sh;
在这里我启动会出现

为什么呢?就像前面所说的 公司端口号是22022 而默认端口又是22
我的解决办法是修改 /home/grid/hadoop-2.2.0/sbin/slaves.sh

要注意 3台服务器都要改 然后我再次启动它又会出现一个问题
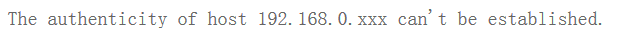
于是我找了一些资料最终解决了还是修改 /home/grid/hadoop-2.2.0/sbin/slaves.sh
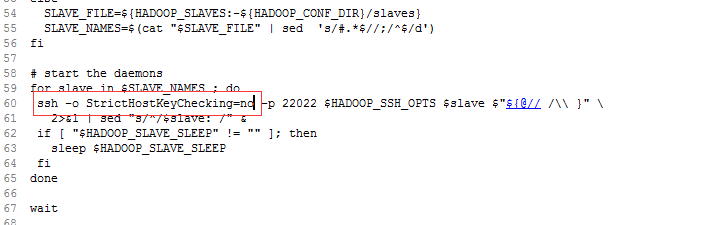
和上面一样3台服务器都要改 我是参考的 http://blog.csdn.net/qdujunjie/article/details/30282825
再之后我重新执行./sbin/start-all.sh
奇怪的所有的进程我都启动没问题 只有从节点服务器113 114 不能启动 datanode
我把错误信息贴出来
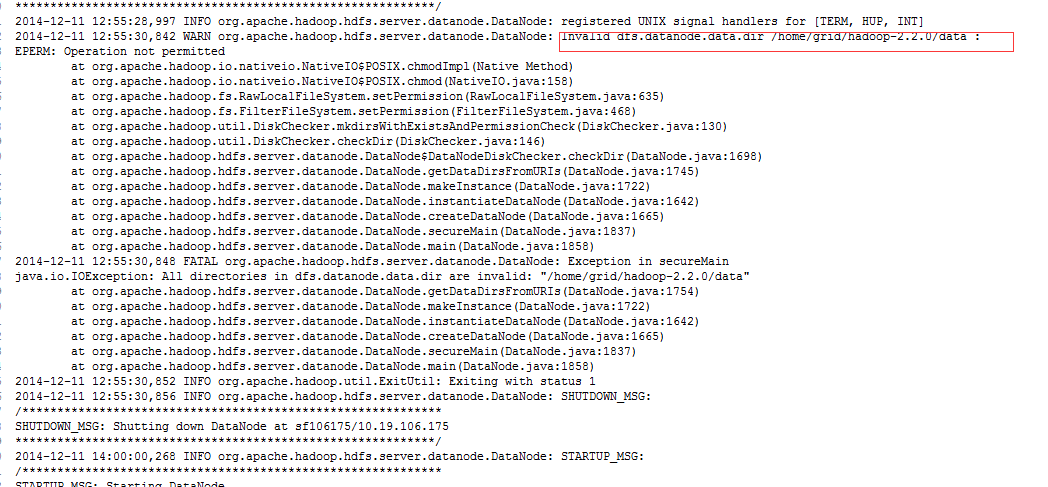
看到以上信息我猜测是没有权限的原因 说是data文件夹没有写的权限 这里为什么呢 我已经把data文件夹权限放在最大了
之后我发现一个很低级的错误 就是发现data文件夹只有root权限才能写 而此时我是grid用户操作的 所以一直都不行
于是我给data文件夹给用户grid 加了权限 执行命令:chown grid:grid /home/grid/hadoop2.2.0/data
grid:grid 前一个代表用户 后一个代表所属组 因为在创建用户的时候该用户所属组会自动生成一个用户一样的名字
因此这个问题就解决了

最后呢 我再次执行启动命令 这里就没有任何问题 所有的进程都已经启动好了
现在我们就可以在3台服务上查看各自的进程了
首先是主节点 112

其次是从节点服务器113 114
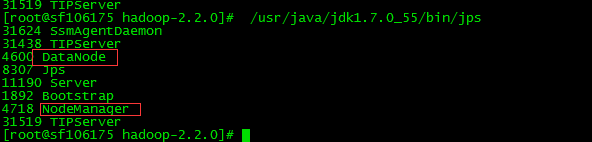

查看集群状态:./bin/hdfs dfsadmin –report
查看文件块组成: ./bin/hdfsfsck / -files-blocks
运行示例程序:
先在hdfs上创建一个文件夹
/bin/hdfsdfs –mkdir /kk
>hdfsdfs -ls /
查看集群信息:如下图正常
hdfs dfsadmin -report
FAQ:
使用命令> hadoop fs -ls /
WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-
问题:Hadoop本地库与系统版本不一致引起的错误。
解决:
查看本地文件
Ø file /hadoop-2.2.0/lib/native/libhadoop.so.1.0.0
libhadoop.so.1.0.0:ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), dynamicallylinked, not stripped
即hadoop是32位的。
一.重新下载hadoop 64位版本安装。
二.可以直接用编译好的 native.tar.gz替换 /opt/hadoop/hadoop-2.2.0/lib/native
2.在执行start-all.sh命令后,datanode中检查到服务已经启动,但是不久后就自动关闭。
可能是datanode与master通信失败造成的。
解决:master的监听端口未开启成功,或者被master主机的防火墙阻止。尝试查看master上的监听端口这关闭防火墙以解决问题
>serviceiptables stop
3.本地代码操作 HDFS时报错:
CallFrom ZBS9WJ52FEO4TQK/10.10.113.163 to hadoop1:9000 failed on connectionexception:java.net.ConnectException: Connectionrefused: no further information;
解决:
经过调代码发现: hdfs对象的URL属性为 hdfs://hadoop1:49002
与配置的端口不一至,应该是hdfs://hadoop1:9000,修改URL值报
Permissiondenied: user=Administrator, access=WRITE,inode="/":root:supergroup:drwxr-xr-x
写入目录权限问题:
hadoop fs -chmod 777 /user/hadoop
然后调试,就正常了
注意:uri指的是 core-site.xml ,一定不能同时配 fs.default.name节点。
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
4.使用http://hadoop1:50070查看信息。但”Browse the filesystem”打不开。
点击browsethe filesystem后,网页转向的地址用的是hadoop集群的某一个datanode的主机名,由于客户端的浏览器无法解析这个主机名,因此该页无法显示。
解决:本台机器无法访问datanode节点。
C:\Windows\System32\drivers\etc\hosts
增加对应的主机名和ip。如:
hadoop2192.168.101.115
hadoop1192.168.101.116
5.hadoop运行程序是出现javaheap space
方法1:修改hadoop环境配置文件conf/hadoop-env.sh,加入下面两行:
export HADOOP_HEAPSIZE=2000
export HADOOP_CLIENT_OPTS="-Xmx1024m $HADOOP_CLIENT_OPTS"
方法2:以上方法是对所有程序有效,如果只针对某一个程序,可以在运行时加入参数,例如:
bin/hadoop jar hadoop-examples-*.jar grep -D mapred.child.java.opts=-Xmx1024Minput output 'dfs[a-z.]+'














 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









