








看别人的代码和自己写代码,两种的难度和境界真是不一样。昨天和今天尝试着写一个简单的全连接神经网络,用来学习一个基本的模型,在实现的过程中遇到了不少的坑,虽然我已经明白了其中的原理。
我想了一个教材上面没有的简单例子,尝试着自己构造训练数据集和测试集。
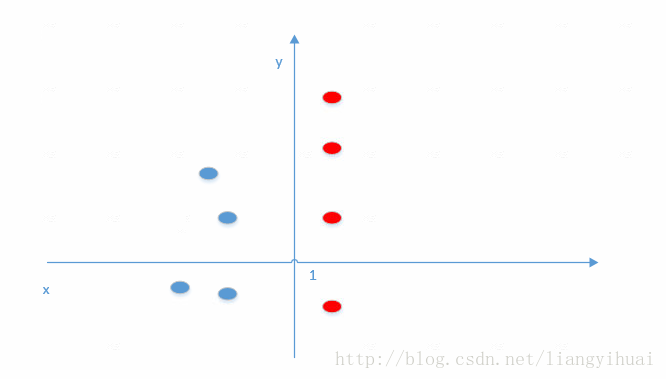
我希望训练一个能够区分红点和蓝点的模型。在我构造的数据集中,当x < 1的时候,为蓝点;当x >1的时候为红点。
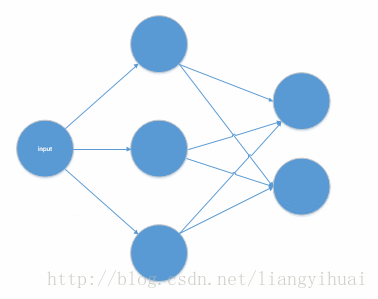
对于这个全连接网络,输入节点只有一个,表示x轴的坐标。有一个隐藏层,隐藏层的节点数量为3.最后是输出层,有两个节点。对于输出层,如果为[1, 0]表示蓝点,[0, 1]为红点。也就是区分两种不同的结果。
下面是代码实现:(使用了tensorflow框架)
import tensorflow as tf;
import numpy as np;
def train_data():
x = [[0.2], [0.4], [0.7], [1.2], [1.4], [1.8], [1.9], [2], [0.11], [0.16], [0.5]];
y = [[1, 0], [1, 0], [1, 0], [0, 1], [0, 1], [0, 1], [0, 1], [1, 0], [1, 0], [1, 0], [1, 0]];
return (x, y);
def test_data():
x = [[0.3], [0.6], [0.8], [1.3], [1.5]];
y = [[1, 0], [1, 0], [1, 0], [0, 1], [0,1]];
return (x, y);
# 数据数据集
x = tf.placeholder(dtype=tf.float32, shape=[None, 1], name='x-input');
# 训练数据集中的label
y_ = tf.placeholder(dtype=tf.float32, shape=[None, 2], name='y-input');
# 输入数据和隐藏层连接的权重
w1 = tf.get_variable('weight1', shape=[1, 3],
initializer=tf.random_normal_initializer(stddev=1, dtype=tf.float32))
# 输入层和隐藏层之间的偏移量,个数等于隐藏层节点的个数。
b1 = tf.get_variable('biase1', shape=[3],
initializer=tf.random_normal_initializer(stddev=1, dtype=tf.float32))
# 隐藏层和输出层链接的权重
w2 = tf.get_variable('weight2', shape=[3, 2],
initializer=tf.random_normal_initializer(stddev=1, dtype=tf.float32))
# 隐藏层和输出层之间的偏移量,个数等于输出层节点的个数。
b2 = tf.get_variable('biase2', shape=[2],
initializer=tf.random_normal_initializer(stddev=1, dtype=tf.float32))
layer1 = tf.nn.sigmoid(tf.matmul(x, w1) + b1);
y = tf.matmul(layer1, w2) + b2; # 模型预测的y值
loss = tf.nn.l2_loss(y-y_); # 使用预测的值和训练数据的label的方差作为损失函数,方差越小越好。
# 开始训练过程。
train_op = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss);
with tf.Session() as sess:
# 初始化所有的张量(变量)
sess.run(tf.global_variables_initializer());
x_train = train_data()[0];
y_train = train_data()[1];
for i in range(10000):# 迭代一万次
sess.run(train_op, feed_dict={x:x_train, y_:y_train})
# 代码执行到这里就已经训练完成了。下面是测试。
# 测试的思路是:比较预测的值和真实值
x_test = test_data()[0];
y_test = test_data()[1];
count = 0;
y_max_value_index = np.argmax(y_test, axis=1);
for i in range(5):
y_value = sess.run(y[i], feed_dict={x:x_test});
if np.equal(y_max_value_index[i], np.argmax(y_value)):
count += 1;
print("the right proportion: %f"%(count/len(y_test)));下面写一下所遇到的坑
1. 每一层的数据、权重和偏移量的维数需要严格对应。从输入数据到输出数据,它们的维数为:[none, 1] ->[1, 3] -> [3, 2], 这里none表示为不确定。也就是输入数据集是一个只有一列行数不确定的数据。隐藏层的权重矩阵是一个一行3列的矩阵。输出层为三行2列的矩阵。
结束感谢.














 1893
1893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









