









今天写了一个小程序,对比了一下拷贝文件的三种方式。然后再比较一下所用的时间.
首先是第一种方式,也是最简单的一种,那就是用File流;
//先判断一下有没有此文件,如果没有则返回提示信息
//先判断一下有没有此文件,如果没有则返回提示信息
if(!src.exists()){
System.out.println("很抱歉没有此目录");
return;
}
//要拷贝的源文件
FileInputStream fi=new FileInputStream(src);
//拷贝过后的文件
FileOutputStream fo=new FileOutputStream(file);
int i=0; //一个标示表示从第一个字节开始读取
byte[] buffer=new byte[8*1025]; //设置一个byte数组,并初始化大小
/*/
* 里面的循环表示从fi路径下面的源文件里面读取字节
* 写入到buffer这个数组里面,从第1个字节开始读取
* 读取到最后一个字节
*/
while((i=fi.read(buffer))!=-1){
//buffer里面的字节写入到fo这个路径下面的文件里面
fo.write(buffer);
}
//关闭流
fi.close();
fo.close();
}
接下来我们测试一下第一种方法所需要的时间
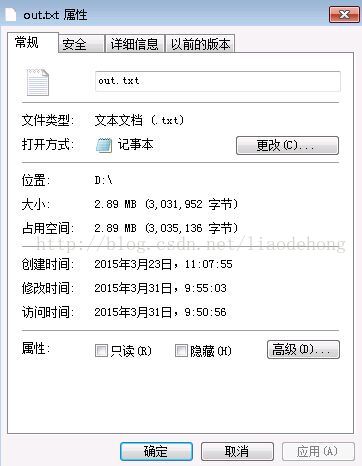
这是目标源文件有3.031.952字节,下面我们来复制读取一下;看看他所需要的时间
ut.CopyFile(src, file);
long endTime1=System.currentTimeMillis();
System.out.println("time1: " + (endTime1 - startTime1)+ " ms");
long startTime2=System.currentTimeMillis();
打印到控制台
time1: 44 ms; 话费了44毫秒;
再来看第二种方法
/*/
* 第二种方法,用的是file的装饰类data
*/
public void CopyDateFile(File src,File file) throws Exception{
if(!src.exists()){
System.out.println("很抱歉没有此目录");
return;
}
DataInputStream dis=new DataInputStream(new FileInputStream(src));
dos=new DataOutputStream(new FileOutputStream(file));
int i=0;
byte[] bs=new byte[8*1025];
while((i=dis.read(bs))!=-1){
//这一步是将读取的数据放入到string类中;
String s=new String(bs);
//然后再从string类中写入数据到文件中
dos.writeBytes(s);
}
dis.close();
dos.close();
}
同样的打印一下控制台信息
time2: 6868 ms;
我们发现话费了6868点毫秒这效率实在是太低了;
再来看第三种方法
/*/
* 第三种方法,带有缓冲区的
*/
public void CopyBufferFile(File src,File file) throws Exception{
if(!src.exists()){
System.out.println("很抱歉没有此目录");
return;
}
FileInputStream fi=new FileInputStream(src);
FileOutputStream fo=new FileOutputStream(file);
BufferedInputStream bis=new BufferedInputStream(fi);
BufferedOutputStream bos=new BufferedOutputStream(fo);
int i=0;
byte[] buffer=new byte[512];
while((i=fi.read(buffer))!=-1){
//这里会有一个缓冲的过程,我们把buffer里面的数据都写入到缓冲区里面
bos.write(buffer);
}
bos.flush();
bos.close();
bis.close();
fi.close();
fo.close();
}
打印一下结果: 23 ms;
对比这三种方式,我们会发现带有缓冲区的是最快的,而file的装饰类dataoutputstream则是最慢的,而且非常慢;
那么他们的区别就很明显了。为什么会有这种原因啦?下面我来分析一下
当使用bufferedoutputstream的时候,我们首先给他构造一个对象,再创建一个引用bos;
看一看源代码

当我们创建bos的对象的时候,实际上就为输出流指定了一个8192大小的缓冲区;
当我们执行write方法的时候就调用了源文件里面的
public synchronized void write(byte b[], int off, int len) throws IOException方法;
因为默认的如果我们没有传入int参数,他给定的就是从第一位截取到最后一位;
可以看到这里面是一个同步方法,也就是说我们是按顺序一个字节一个字节读取的,把字节读取到
那个缓冲区大小中,这里缓冲区里面有一个刷新方法,会不断的传入数据,直到写入完毕;
这种方法的效率还不是最快的因为他是同步的,但是安全性比较高,而且效率还比较快,一般都用这种方法;
DataOutputStream的效率非常慢,但是它的优势再与他写入,写出的时候 可以指定对应的数据类型;他里面有int ,char,utf,bytes等等,
其实也就是把里面的方法进行了修饰;














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









