






第一部分:Lucene描述
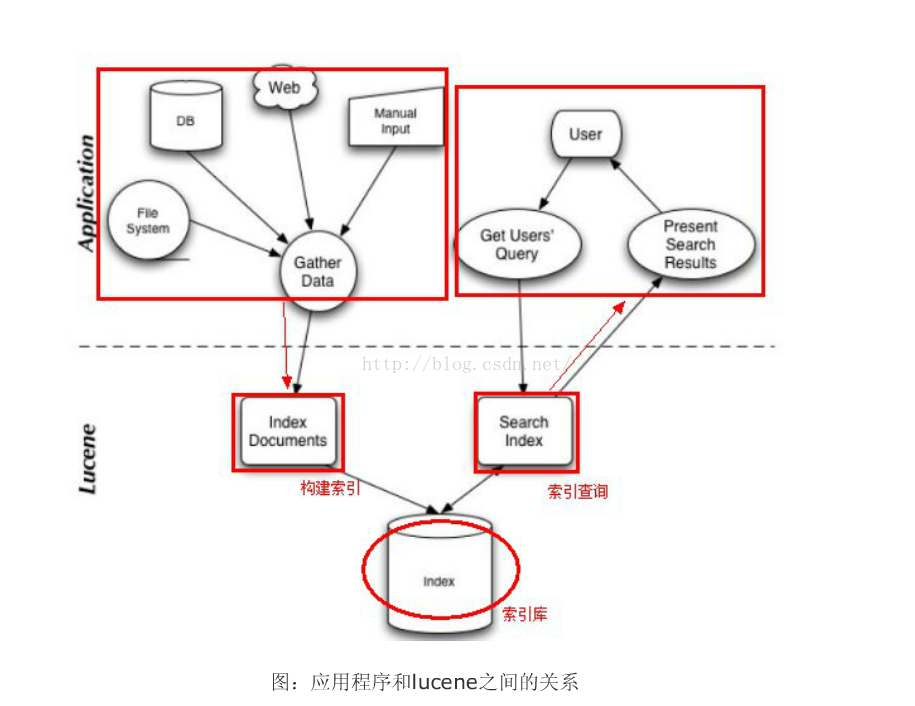
建立索引:
为了对文档进行索引,Lucene 提供了五个基础的类,他们分别是 Document, Field, IndexWriter, Analyzer, Directory。下面分别介绍一下这五个类的用途:
Document: Document 是用来描述文档信息。一个 Document 对象由多个 Field 对象组成的。可以把一个 Document 对象想象成数据库中的一个记录,而每个 Field 对象就是记录的一个字段。
例如:Document doc = new Document();
doc.add(new Field("id", article.getId().toString(),Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.add(new Field("title", article.getTitle().toString(),Field.Store.YES, Field.Index.ANALYZED));
doc.add(new Field("content", article.getContent().toString(),Field.Store.YES, Field.Index.ANALYZED));
Field:Field 对象是用来描述一个文档的某个属性的。
例如 User类里面有 name,description两个变量,两个变量可以当成Filed两个属性
Field nameField=new Field("name", article.getName().toString(),Field.Store.YES, Field.Index.NOT_ANALYZED));
Field descriptionField=new Field("description", article.getDescription().toString(),Field.Store.YES, Field.Index.NOT_ANALYZED));
Document doc = new Document();
doc.add(nameField);
doc.add(descriptionField);
Analyzer:在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由 Analyzer 来做的。Analyzer 类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的 Analyzer。Analyzer 把分词后的内容交给 IndexWriter 来建立索引。
IndexWriter:是 Lucene 用来创建索引的一个核心的类,他的作用是把一个个的 Document 对象加到索引中来。
Directory:这个类代表了 Lucene 的索引的存储的位置,这是一个抽象类,它目前有两个实现,第一个是 FSDirectory,它表示一个存储在文件系统中的索引的位置。第二个是 RAMDirectory,它表示一个存储在内存当中的索引的位置。
搜索文档:
利用 Lucene 进行搜索就像建立索引一样也是非常方便的。在上面一部分中,我们已经为一个目录下的文本文档建立好了索引,现在我们就要在这个索引上进行搜索以找到包含某个关键词或短语的文档。Lucene 提供了几个基础的类来完成这个过程,它们分别是呢 IndexSearcher, Term, Query, TermQuery, Hits. 下面我们分别介绍这几个类的功能。
Query:这是一个抽象类,他有多个实现,比如 TermQuery, BooleanQuery, PrefixQuery. 这个类的目的是把用户输入的查询字符串封装成 Lucene 能够识别的 Query。
Term:Term 是搜索的基本单位,一个 Term 对象有两个 String 类型的域组成。生成一个 Term 对象可以有如下一条语句来完成:Term term = new Term(“fieldName”,”queryWord”); 其中第一个参数代表了要在文档的哪一个 Field 上进行查找,第二个参数代表了要查询的关键词。
TermQuery:TermQuery 是抽象类 Query 的一个子类,它同时也是 Lucene 支持的最为基本的一个查询类。生成一个 TermQuery 对象由如下语句完成: TermQuery termQuery = new TermQuery(new Term(“fieldName”,”queryWord”)); 它的构造函数只接受一个参数,那就是一个 Term 对象。
IndexSearcher:IndexSearcher 是用来在建立好的索引上进行搜索的。它只能以只读的方式打开一个索引,所以可以有多个 IndexSearcher 的实例在一个索引上进行操作。
第二部分:Lucene过程
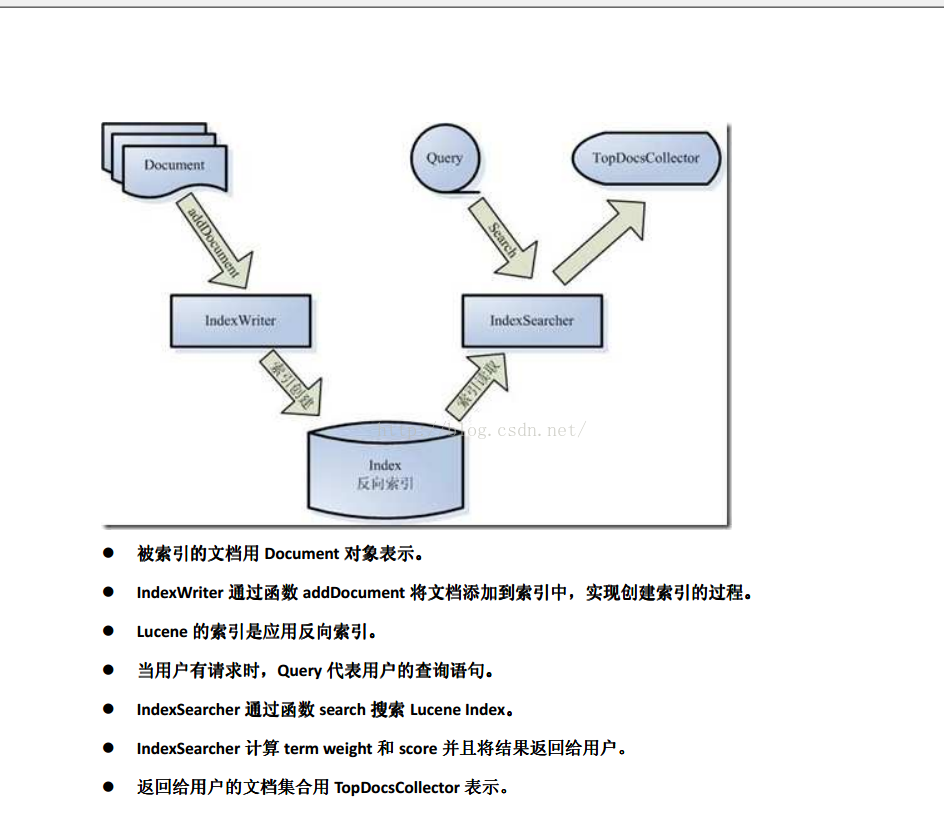
索引过程如下:
创建一个 IndexWriter 用来写索引文件,它有几个参数, INDEX_DIR 就是索引文件所存放的位置, Analyzer 便是用来对文档进行词法分析和语言处理的。
创建一个 Document 代表我们要索引的文档。 将不同的 Field 加入到文档中。我们知道,一篇文档有多种信息,如题目,作者,修改时间,内容等。不同类型的信息用不同的 Field 来表示,在本例子中,一共有两类信息进行了索引,一个是文件路径,一个是文件内容。其中FileReader 的SRC_FILE 就表示 要索引的源文件。 IndexWriter 调用函数 addDocument 将索引写到索引文件夹中。
搜索过程如下:
IndexReader 将磁盘上的索引信息读入到内存, INDEX_DIR 就是索引文件存放的位置。
创建 IndexSearcher 准备进行搜索。
创建 Analyer 用来对查询语句进行词法分析和语言处理。
创建 QueryParser 用来对查询语句进行语法分析。QueryParser 调用 parser 进行语法分析,形成查询语法树,放到Query中,indexSearcher调用search 对Query进行搜索查询。
第三部分:Lucene结构
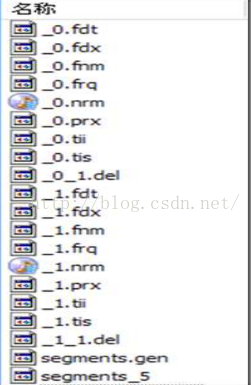
Lucene 的索引结构是有层次结构的,主要分以下几个层次:
(1)索引(Index):在 Lucene 中一个索引是放在一个文件夹中的。 如上图,同一文件夹中的所有的文件构成一个 Lucene 索引。
(2) 段(Segment): 一个索引可以包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以合并。 如上图,具有相同前缀文件的属同一个段,图中共两个段 "_0" 和 "_1"。 segments.gen 和 segments_5 是段的元数据文件,也即它们保存了段的属性信息。
(3)文档(Document):文档是我们建索引的基本单位,不同的文档是保存在不同的段中的,一个段可以包含多篇文档。 新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中。
(4) 域(Field):一篇文档包含不同类型的信息,可以分开索引,比如标题,时间,正文,作者等,都可以保存在不同的域里。 不同域的索引方式可以不同,在真正解析域的存储的时候,我们会详细解读。
(5)词(Term):词是索引的最小单位,是经过词法分析和语言处理后的字符串。
按层次保存了从索引,一直到词的包含关系:索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)
第四部分:编写一个索引的功能项目
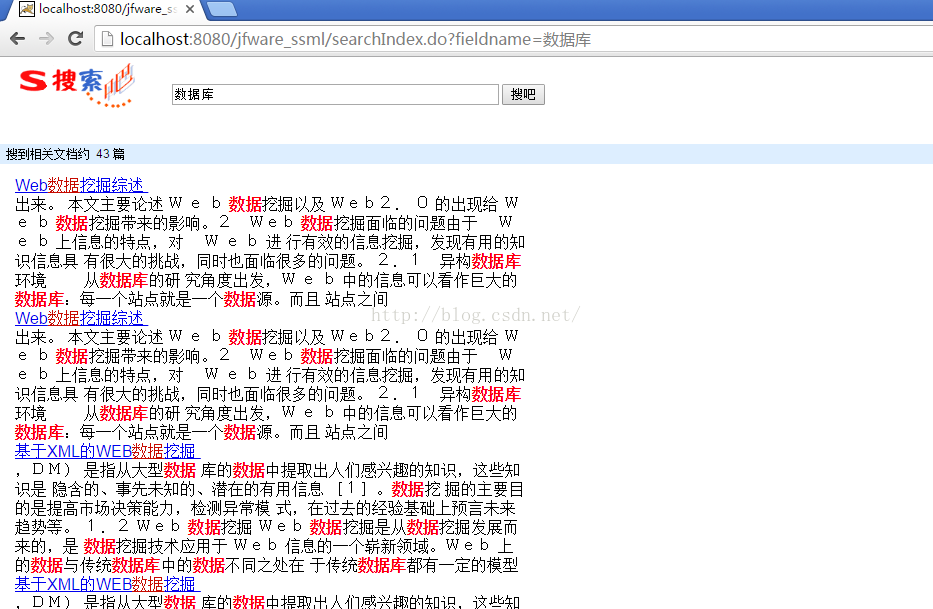
本项目使用springMVC+Lucene索引
4.1:创建一个SystemConstant类,主要记录索引所存放的路径
/**
* 系统常量
*/
public class SystemConstant {
public static String basedir = "\\";
public static String CONTEXT = "\\jfware";
public static String indexDir = "d:\\lucene\\luceneindex";
public static String PDFdir = basedir + "datadir\\pdfdir\\";
public static String PDFTxtdir = "d:\\lucene\\datadir\\pdftxtdir\\";
public static String ConvertorPATH = "D:\\lucene\\xpdf\\bin32\\pdftotext";
public static String Docdir = basedir + "datadir\\worddir\\";
public static String getRootRealPath(String str, HttpServletRequest request) {
basedir = request.getRealPath("datadir");
if ("pdf".equals(str)){
return request.getRealPath(PDFdir);
}else{
return request.getRealPath(Docdir);
}
}
}
4.2:创建一个LuceneUtil类,索引的主要工具类:
public IndexSearcher getSearcher(){
try {
if(reader == null){
reader = DirectoryReader.open(directory);
}else{
DirectoryReader tr = DirectoryReader.openIfChanged(reader);
if(tr != null){
reader.close();
reader = tr;
}
}
return new IndexSearcher(reader);
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 获取ScoreDoc
* @param queryStr
* @param headSearchNum 得到查询的靠前的结果数
* @return
* @throws Exception
*/
public ScoreDoc[] getScoreDocs(String queryStr, int headSearchNum)
throws Exception {
directory = FSDirectory.open(new File(SystemConstant.indexDir));
reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
Query query = this.getQuery(queryStr, headSearchNum);
TopDocs topDocs = searcher.search(query, headSearchNum);
ScoreDoc[] hits = topDocs.scoreDocs;
return hits;
}
/**
* 获得查询
* @param queryStr
* @param headSearchNum
* @return
* @throws Exception
*/
public Query getQuery(String queryStr, int headSearchNum) throws Exception {
PaodingAnalyzer analyzer = new PaodingAnalyzer();
String field = "contents";
QueryParser parser = new QueryParser(Version.LUCENE_44, field, analyzer);
Query query = parser.parse(queryStr);
return query;
}
/**
* 获得索引结果
* @param queryStr
* @param currentPageNum
* @param topNum
* @return
* @throws Exception
*/
public List<DocumentEntity> getResult(String queryStr, int currentPageNum,int topNum)
throws Exception {
//初始化列表
List<DocumentEntity> list = new ArrayList<DocumentEntity>();
directory = FSDirectory.open(new File(SystemConstant.indexDir));
reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
//高亮显示设置
Highlighter highlighter = null;
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<font color='red'><b>", "</b></font>");
Highlighter highlighterTitle = null;
SimpleHTMLFormatter formatTitle = new SimpleHTMLFormatter("<FONT color=#c60a00>", "</FONT>");
ScoreDoc[] hits = this.getScoreDocs(queryStr, topNum);
Query query = this.getQuery(queryStr, topNum);
highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
highlighterTitle = new Highlighter(formatTitle, new QueryScorer(query));
highlighter.setTextFragmenter(new SimpleFragmenter(200));//这个200是指定关键字字符串的context
//的长度,你可以自己设定,因为不可能返回整篇正文内容
Document doc;
String fileName="";
int totalNumber = currentPageNum * eachePageNum;
if (totalNumber > hits.length)
totalNumber = hits.length;
for (int i = (currentPageNum - 1) * eachePageNum; i < totalNumber; i++) {
//打印文档的内容
doc = searcher.doc(hits[i].doc);
//高亮出显示
DocumentEntity docEntity = new DocumentEntity();
TokenStream tokenStream = new PaodingAnalyzer().tokenStream("contents", new StringReader(doc.get("contents")));
docEntity.setContents(highlighter.getBestFragment(tokenStream, doc.get("contents")));
fileName = doc.get("fileName");
tokenStream = new PaodingAnalyzer().tokenStream("fileName",new StringReader(fileName));
//需要注意:在处理时如果文本检索结果中不包含对应的关键字返回一个null
String forMatt=highlighterTitle.getBestFragment(tokenStream, fileName);
if(forMatt == null){
docEntity.setFilename(fileName);
}else{
docEntity.setFilename(forMatt);
}
String type1 = doc.get("type");
docEntity.setType(type1);
docEntity.setId(doc.get("id"));
if ("pdf".equalsIgnoreCase(type1)) {
fileName = SystemConstant.CONTEXT + SystemConstant.PDFdir + fileName + "." + type1;
docEntity.setOriginalFileName(fileName);
} else if ("doc".equalsIgnoreCase(type1)) {
fileName = SystemConstant.CONTEXT + SystemConstant.Docdir + fileName + "." + type1;
docEntity.setOriginalFileName(fileName);
}
list.add(docEntity);
}
return list;
}
4.3:基本的索引都准备好,现在写一个SearchController类,用户查询:
@Controller
public class SearchController {
/**
* 文档搜索
* @param request
* @return
* @throws Exception
*/
@RequestMapping("searchIndex")
public ModelAndView searchIndex(HttpServletRequest request) throws Exception {
String page = request.getParameter("page");
String fieldname = request.getParameter("fieldname");
fieldname = new String(fieldname.getBytes("ISO-8859-1"), "UTF-8");
if (page == null) page = "1";
int currentNum = Integer.valueOf(page);
GetSearchResult gsr = new GetSearchResult();
List<DocumentEntity> list = gsr.getResult(fieldname, currentNum, 5);
int recordCount = gsr.getScoreDocs(fieldname, 200).length;
request.setAttribute("sk", fieldname);
request.setAttribute("sk1", URLEncoder.encode(fieldname, "UTF-8"));
return new ModelAndView("result").addObject("pageUrl", "searchIndex.do?page=")
.addObject("rsize", recordCount).addObject("rlist", list);
}
}














 7293
7293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









