










DateSet的API详解十五
getParallelism
def getParallelism: Int
Returns the parallelism of this operation.
获取DataSet的并行度。执行程序:
//1.创建一个 DataSet其元素为String类型
val input0: DataSet[String] = benv.fromElements("A", "B", "C")
//2.获取DataSet的并行度。
input0.getParallelism执行结果:
res98: Int = 1setParallelism
def setParallelism(parallelism: Int): DataSet[T]
Sets the parallelism of this operation. This must be greater than 1.
设置DataSet的并行度,设置的并行度必须大于1执行程序:
//1.创建一个 DataSet其元素为String类型
val input0: DataSet[String] = benv.fromElements("A", "B", "C")
//2.设置DataSet的并行度。
input0.setParallelism(2)
//3.获取DataSet的并行度。
input0.getParallelism执行结果:
res102: Int = 2writeAsText
def writeAsText(filePath: String, writeMode: WriteMode = null): DataSink[T]
Writes this DataSet to the specified location.
将DataSet写出到存储系统。不同的存储系统写法不一样。
hdfs文件路径:
hdfs:///path/to/data
本地文件路径:
file:///path/to/data执行程序:
//1.创建 DataSet[Student]
case class Student(age: Int, name: String,height:Double)
val input: DataSet[Student] = benv.fromElements(
Student(16,"zhangasn",194.5),
Student(17,"zhangasn",184.5),
Student(18,"zhangasn",174.5),
Student(16,"lisi",194.5),
Student(17,"lisi",184.5),
Student(18,"lisi",174.5))
//2.将DataSet写出到存储系统
input.writeAsText("hdfs:///output/flink/dataset/testdata/students.txt")
//3.执行程序
benv.execute()hadoop web ui中的执行效果:
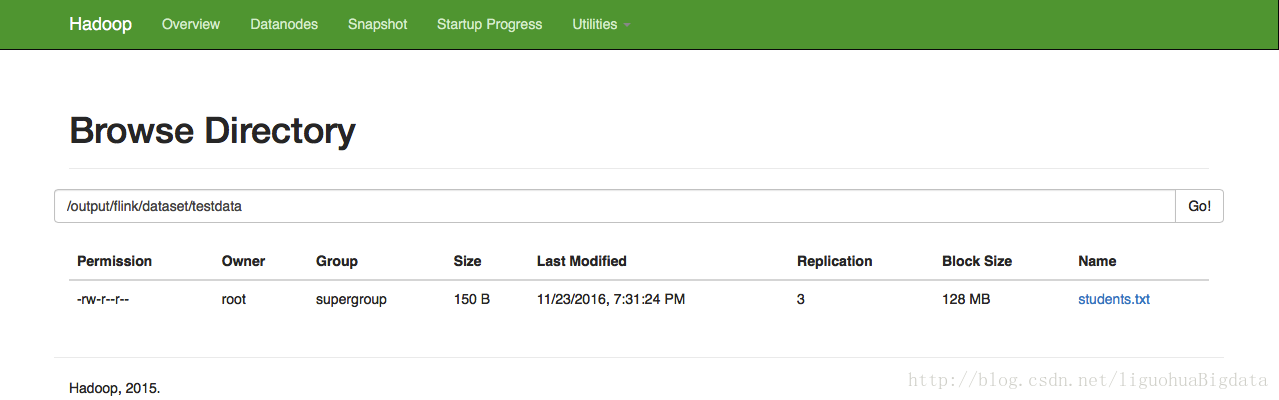
terminal中查看文件效果:















 2112
2112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









