







当我们在浏览器输入:http://www.baidu.com/index.html时,幕后都发生了什么?
我们直接来说一个http请求所经历的步骤,中间涉及的其他知识点会穿插做出相应的简单补充说明。
相关知识点一:HTTP协议
HTTP是HyperTextTransfer Protocol的缩写,即超文本传输协议,是一个应用层协议,用来约定从WWW服务器传输超文本到本地浏览器的传输规范。所以当客户端与服务器端进行通信时,应满足此协议。
因为HTTP是应用层协议,而要实现上层协议,还需要使用下面一层提供的服务,即需要运输层为应用层提供服务,而因特网中常用的运输层协议是TCP协议,即TransmissionControl Protocol传输控制协议(面向连接的,能提供可靠的交付),而同理,运输层协议的实现需要网络层为其提供服务,而在TCP/IP体系中,网络层主要的协议是无连接的网际协议IP(Internet Protocol)和许多种路由选择协议,通过网络层,使源主机运输层所传下来的分组能够通过网络中的路由器找到目的主机。
1、 连接
当我们输入这样一个请求时,首先要建立一个tcp连接。而tcp连接的端点是套接字(socket),所谓套接字,即端口号拼接到IP地址即构成了套接字,即(IP地址:端口号)。所以在这之前还有一个DNS解析过程。所谓DNS解析,即Domain Name System(域名系统)解析,通俗地讲就是把计算机名解析成IP地址。通过DNS解析,可以把域名www.baidu.com变为地址,如果url里不包含端口号,就会使用默认端口号80。
我们可以在DOS命令框输入:ping www.baidu.com来查看百度的IP地址。如下图所示:
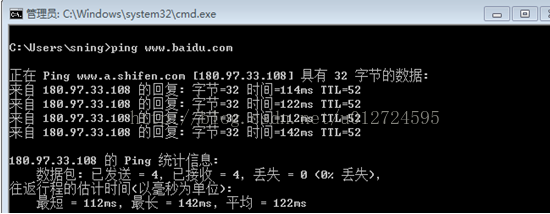
把地址180.97.33.108输入到浏览器的地址栏,与在地址栏输入www.baidu.com的效果是一样的,如下图所示:

直接通过IP地址访问网页

通过域名访问网页
由此可见,通过域名访问与通过IP地址访问的效果是一样的,即此域名与IP地址是对应的。
相关知识点二:DNS
◆域名结构
域名采用了层次树状结构的命名方法。从语法上讲,每一个域名都是由标号(label)序列组成,而各标号之间用点“.”隔开,例如域名www.baidu.com,它是由3个标号组成,其中标号com是顶级域名,标号baidu是二级域名,标号www是三级域名。标号由英文字母和数字组成,每个标号不超过63个字符,不区分大小写,除连字符(-)外不能使用其他标点符号。级别最低的域名写在最左边,而级别最高的顶级域名写在最右边。由多个标号组成的完整域名总共不超过255个字符。DNS既不规定一个域名需要多少个下级域名,也不规定每一级的域名代表什么意思。各级域名由其上一级的域名管理机构管理,而最高的顶级域名由ICANN(The InternetCorporation for Assigned Names and Numbers 互联网名称与数字地址分配机构)进行管理。如下图所示是域名树:
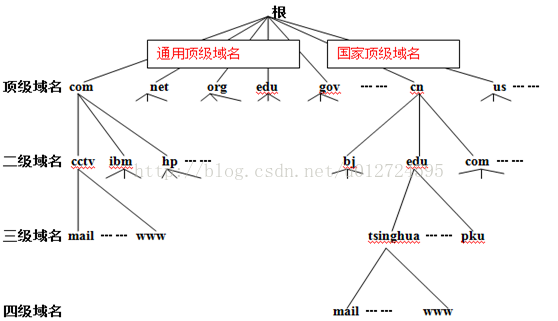
因特网的域名空间
用域名树来表示因特网的域名系统是最清楚的。上图是因特网域名空间的结构,它实际上是一个倒过来的树,在最上面的是根,但没有对应的名字。根下面一级的节点就是最高一级的顶级域名(由于根没有名字,所以在根下面一级的域名就叫做顶级域名)。顶级域名可往下划分子域,即二级域名。再往下划分就是三级域名、四级域名等。如上图所示,凡是在顶级域名com下注册的单位都获得了一个二级域名,图中给出的例子有:中央电视台cctv,以及IBM、惠普(hp)等公司。在顶级域名cn(中国)下举出了几个二级域名,如:bj、edu、com。在某个二级域名下注册的单位就可以获得一个三级域名。图中给出的在edu下面的三级域名有:tsinghua(清华大学)、puk(北京大学)。
使用这种方法可使每一个域名在整个因特网范围内是唯一的,并且也容易设计出一种查找域名的机制来。
◆域名解析的过程
两种DNS查询方式:
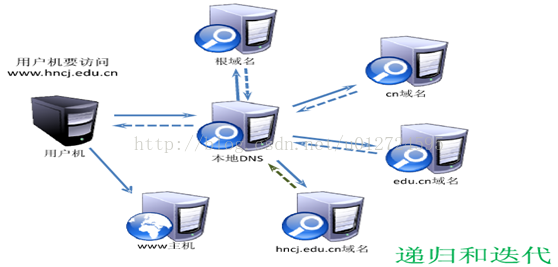
第一, 主机向本地域名服务器的查询一般都是采用递归查询。所谓递归查询就是:如果主机所查询的本地域名服务器不知道被查询域名的IP地址,那么本地域名服务器就以DNS客户的身份,向其他根域名服务器继续发出查询请求报文(即替该主机继续查询),而不是让该主机自己进行下一步的查询。因此,递归查询返回的查询结果或者是所要查询的IP地址,或者是报错,表示无法查询到所需的IP地址。
第二, 本地域名服务器向根域名服务器的查询通常是采用迭代查询。迭代查询的特点是这样的:当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的IP地址,要么告诉本地域名服务器:“你下一步应当向哪一个域名服务器进行查询”。根域名服务器通常是把自己知道的顶级域名服务器的IP地址告诉本地域名服务器,让本地域名服务器再向顶级域名服务器查询。顶级域名服务器在收到本地域名服务器的查询请求后,要么给出所要查询的IP地址,要么告诉本地域名服务器下一步应当向哪一个权限域名服务器进行查询。本地域名服务器就这样进行迭代查询。最后,知道了所要解析的域名的IP地址,然后把这个结果返回给发起查询的主机。当然,本地域名服务器也可以采用递归查询。这取决于最初的查询请求报文的设置是要求使用哪一种查询方式。
举例说明:
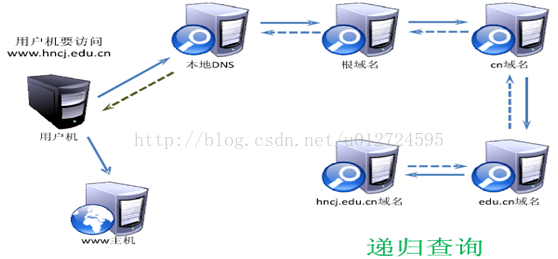
递归查询
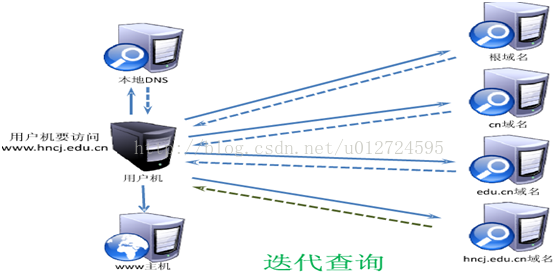
迭代查询
递归和迭代查询
我们注意到,整个查询过程经过了10个步骤,这10个步骤总共要使用10个数据报报文。为了提高DNS查询效率,并减轻根域名服务器的负荷和减少因特网上的DNS查询报文数量,在域名服务器中广泛地使用了高速缓存(有时也成为高速缓存域名服务器)。高速缓存用来存放最近查询过的域名以及从何处获得域名映射信息的记录。
例如,在上图迭代查询的过程中,如果在不久前已经有用户查询过域名为www.hncj.edu.cn的IP地址,那么本地域名服务器就不必向根域名服务器重新查询www.hncj.edu.cn的IP地址,而是直接把高速缓存中存放的上次查询结果告诉用户。假定本地域名服务器的缓存中并没有www.hncj.edu.cn的IP地址,而是存放着顶级域名服务器的IP地址,那么本地域名服务器也可以不向根域名服务器进行查询,而是直接向cn顶级域名服务器发送查询请求报文。这样不仅可以大大减轻根域名服务器的负荷,而且也能够使因特网上的DNS查询请求和回答报文的数量大大减少。
2、 请求
连接成功建立后,就会向web服务器发送请求,这个请求的方式一般是GET或者POST命令。(GET一般用于获取/查询资源信息,而POST一般用于更新资源信息。)GET命令的格式为:GET 路径/文件名 HTTP/1.1 ,其中文件名指出所访问的文件,而HTTP/1.1 指出web浏览器使用的http版本。
相关知识点三:关于http协议1.0与1.1版本的区别:
① http 1.0 ,称为短连接。浏览器的每次请求(也就是对每一个页面的访问)都要求建立一次单独的tcp连接,在处理完本次的请求后,就自动断开连接,而且服务器不跟踪每个用户也不记录过去的请求(即http协议是无状态的)。这就造成了一些性能缺陷,如:访问一个包含有多个图像的网页文件时,因为网页文件中并没有包含真正的图像数据内容,而只是指明了这些图像数据的url地址,当web浏览器访问这个网页文件时,浏览器首先要发出针对该网页文件的请求,当浏览器解析web服务器返回的该网页文档中的html内容时,发现其中的<img>图像标签后,浏览器将根据<img>标签中的src属性所指定的url地址再次向服务器发出下载图像数据的请求。显然,访问一个包含有许多图像的网页文件的整个过程包含了多次请求和响应,每次请求和响应都需要建立一个单独的连接,每次连接只是传输一个文档或者图像,上一次请求和下一次请求完全分离,这是一个相对比较费时的过程,并且会严重影响客户机和服务器的性能。

http 1.0请求模式
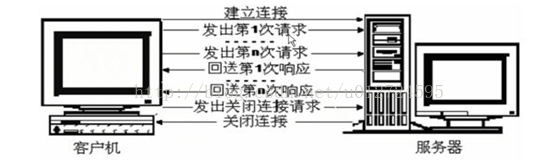
为了克服http 1.0的这个缺陷,http 1.1支持持久连接(当然也不是永久连接,而是有一个设置的连接持续时间)。
② http 1.1,称为长连接。在一个tcp连接上可以传送多个http请求和响应,减少了建立和关闭连接的消耗和延迟。一个包含有多个图像数据的网页文件的多个请求和应答可以在一个连接中传输,但每个单独的网页文件的请求和响应仍然需要使用各自的连接。http 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求,但服务器必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著减少了整个下载过程所需要的时间。
http 1.1请求模式
相关知识点四:HTTP的请求部分
首先介绍一款强大的网页数据分析工具:httpwatch。官网的介绍是:HttpWatch is an HTTPsniffer for IE, Firefox, iPhone & iPad that provides new insights into howyour website loads and performs. 官方下载地址是:http://www.httpwatch.com/download/。下载安装后,打开IE浏览器,就可以利用快捷键“Shift+F2”打开HttpWatch,然后便可以利用它分析网页数据了。但是一般基本版的功能有限,可下载破解版。
现在我们就利用httpwatch来分析http的请求部分。
以下是Httpwatch的界面:
当我们访问百度首页面时,点击“Record”后,在IE 打开需要访问的网址www.baidu.com,界面如下:
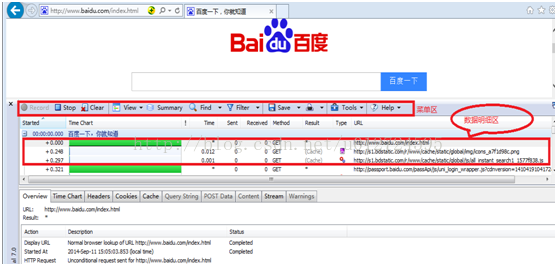
选定信息http://www.baidu.com/index.html,然后点击“headers”,就可以查看这个请求的报头信息,如下图红色区域所示,即为http请求信息:
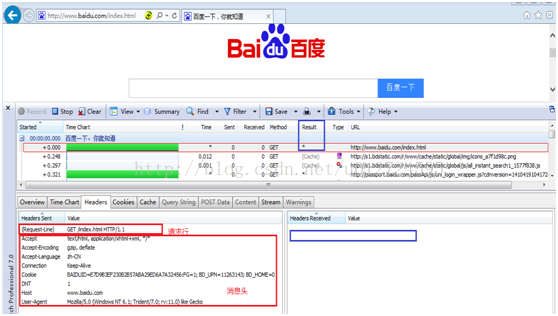
◆ http请求部分基本结构:
(Request-Line) GET /index.html HTTP/1.1 请 求 行
Accept text/html,application/xhtml+xml, */*
Accept-Encoding gzip, deflate
Accept-Language zh-CN
Connection Keep-Alive
Cookie BAIDUID=E7D9B3EF230B2B57ABA29ED6A7A32456:FG=1;BD_UPN=11263143;BD_HOME=0
DNT 1
Host www.baidu.com
User-Agent Mozilla/5.0 (Windows NT6.1; Trident/7.0; rv:11.0) like Gecko
◆特别说明:
①(Request-Line) GET /index.html HTTP/1.1【Thefirst line of the request message thatis used to specify the required method name, URL and HTTP version】
② Accept text/html, application/xhtml+xml, */*【Indicateswhich content types are acceptable to the browser】
③ Accept-Encoding gzip,deflate【The ‘gzip,deflate’ valuefor this header indicates that the browser can download content that has beencompressed with either of these methods】
④ Accept-Language zh-CN【Indicates which languagesare accepted by the browser】
⑤ Connection Keep-Alive【A value of ‘keep-Alive’indicates that the browser would prefer to use persistent connections that canbe re-used in other requests】
⑥ Cookie BAIDUID=E7D9B3EF230B2B57ABA29ED6A7A32456:FG=1;BD_UPN=11263143;BD_HOME=0【The list ofcookies that apply to the current request】
⑦ DNT 1【没写】
⑧ Host www.baidu.com【The domainname of the server to which this request is being sent】
⑨ User-Agent Mozilla/5.0(Windows NT 6.1; Trident/7.0;rv:11.0)like Gecko【Supplies information about the browser and client operating system】
◆ 对于上述特别说明的翻译:
① GET /index.html HTTP/1.1【详细说明请求的方式,URL,和http版本】
② Accept text/html,application/xhtml+xml,*/*【表明浏览器能够接受的内容的类型】
③ Accept-Encoding gzip,deflate【表明浏览器能够下载以“gzip,deflate”任一种方式进行压缩的内容】
④ Accept-Language zh-CN【表明浏览器能够接受哪种语言(中文)】
⑤ Connection Keep-Alive【表明浏览器选择持续连接以便在另一次请求中重新使用】
⑥ Cookie BAIDUID=E7D9B3EF230B2B57ABA29ED6A7A32456:FG=1;BD_UPN=11263143;BD_HOME=0【当前请求的cookie列表】
⑦ DNT 1【???】
⑧ Host www.baidu.com【表示此请求将要被发送到的主机的域名】
⑨ User-Agent Mozilla/5.0(Windows NT 6.1; Trident/7.0;rv:11.0)like Gecko【提供浏览器客户端内核的信息】
可见,一次完整的http请求消息包括:一个请求行、若干消息头以及实体内容,其中消息头和实体内容可以没有,消息头和实习内容之间有一个空行隔开。请求消息用来向服务器传达某种信息或指示。
3、应答
web服务器收到这个请求,进行处理,从它的文档空间搜索文件index.html,如果找到该文件,web服务器把该文件内容传送给相应的web浏览器。为了告知浏览器,web服务器首先传送一些HTTP头信息,然后传送具体内容(即,HTTP体信息),HTTP头信息和HTTP体信息之间也用一个空行来隔开。
相关知识点五:HTTP的应答部分
如上图蓝色标注区域所示,由于HttpWatch的版本或者破解问题,我下载的这款HttpWatch并没有给出服务器返回的应答信息。但是根据所查资料,我在下面将给出一些基本的HTTP响应信息,如下图所示:

◆特别说明:
①HTTP/1.1 200 OK【表示HTTP版本,服务器端返回的状态码,状态说明】
②Server Microsoft-IIS/5.0【表明web服务器软件及其版本号的头标】
③Date Thu, 13 Jul 2000 05:46:53 GMT【发送此应答消息的日期】
④Content-Length 2291【描述HTTP消息实体的传输长度】
⑤Content-Type text/html【表明发送或者接收的实体的MIME类型】
⑥Cache-Control private【用于指定缓存指令,private是默认值】
相关知识点六:状态码
可见,每一个请求报文发出后,都能收到一个响应报文。响应报文的第一行就是状态行。状态行包括三项内容,即HTTP的版本号,状态码,以及解释状态码的简单短语。状态码(Status-Code)都是三位数字的,分为5大类共33种。例如:
1XX表示通知信息的,如请求收到了或正在进行处理。
2XX表示成功,如接受或知道了。
3XX表示重定向,如要完成请求还必须采取进一步的行动。
4XX表示客户的差错,如请求中有错误的语法或不能完成。
5XX表示服务器的差错,如服务器失效无法完成请求。
下面的状态行在响应报文中是经常见到的:
HTTP/1.1200 OK 【成功】
HTTP/1.1202 Accepted 【接受】
HTTP/1.1400 Bad Request 【错误的请求】
HTTP/1.1404 Not Found 【找不到】

404请求的资源不存在
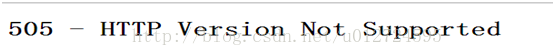
505 TP版本不支持
4、关闭连接
当应答结束后,web浏览器与web服务器必须断开,以保证其它web浏览器能够与web服务器建立连接。
本文转自:http://www.cnblogs.com/yuteng/articles/1904215.html














 3892
3892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









