







起因
小伙伴做行人检测,对文中中生成的定位数据需要重新调整,方便程序循环的读写。他是用MATLAB实现的,我看了一下,好多关于文本操作的函数,我都没看过,还得X度,长了不少见识。。。。从网上摘抄了一部分(MATLAB文件操作小结,分享+备份)。。。。同时,我觉得根据前面两篇博文,实现他的要求应该是不难的,尝试写了一下,发现是可行的嘛~~~~
要求
原始行人定位数据存放在 seq01.txt、seq02.txt 和 seq03.txt三个TXT文件中。点击下载。
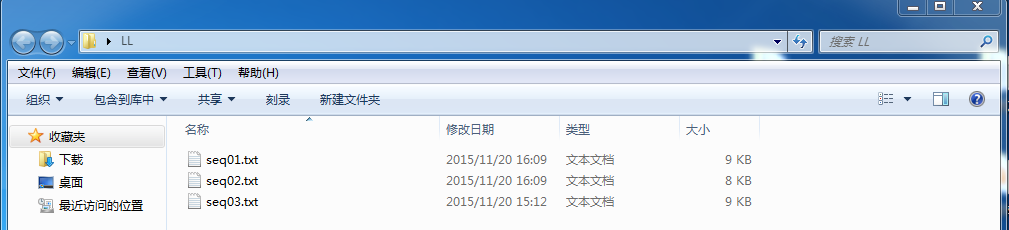
原始数据存储格式如下图所示,以 seq01.txt 中数据为例吧。
图片名+坐标
"left/image_00000001_0.png": (212, 204, 232, 261), (223, 181, 259, 285), (293, 151, 354, 325), (452, 208, 479, 276), (255, 219, 268, 249), (280, 219, 291, 249);
"left/image_00000002_0.png": (212, 204, 232, 261), (223, 179, 261, 287), (293, 151, 357, 331), (452, 210, 477, 276), (257, 221, 268, 249), (282, 217, 293, 249);
"left/image_00000003_0.png": (221, 179, 259, 287), (210, 206, 234, 263), (257, 219, 270, 251), (282, 221, 293, 249), (295, 149, 361, 331), (450, 212, 477, 278);
"left/image_00000004_0.png": (221, 183, 261, 289), (217, 210, 234, 263), (257, 223, 268, 249), (282, 223, 293, 251), (299, 147, 365, 335), (448, 212, 477, 278);
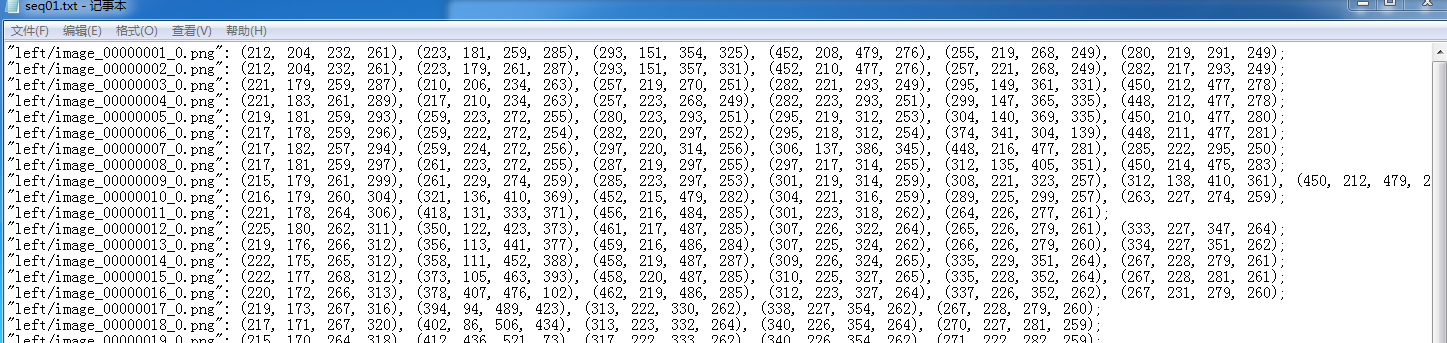
小伙伴要求把里面每一行(代表一张图)里面的数据重新操作并导出到一个新的txt中,如下图
文件类(seq01.txt=1、seq02.txt=2 、seq03.txt=3)+ 每一行图片名 + .txt
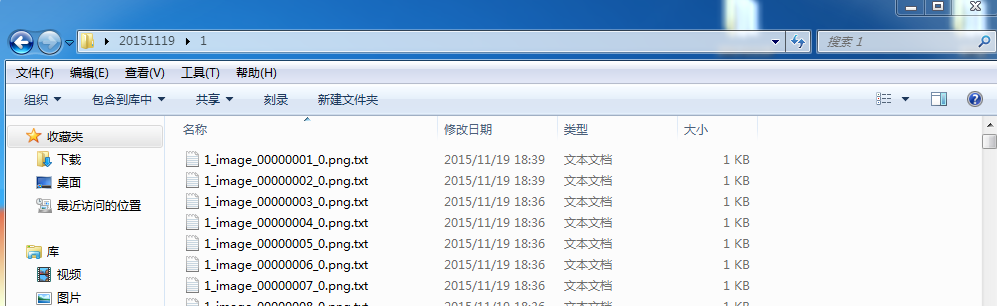
每个新的txt的内容就是纯粹的坐标

最后的数字是10他自己加上去的,什么作用不清楚,反正每个新的txt最后都要加上数字10,对于编程来说没什么影响。
坐标(把原始每行括号去掉,逗号去掉,空格为一个,分号去掉)+ 数字10实现
下载:链接
#python
#!/usr/bin/env python
# -*- coding:utf-8 -*-
__author__ = 'li'
import glob
import os
"""
功能:实现读取txt文件中每行内容,并按照规定格式重新存储到指定文件。
"""
def get_txt_list(file,output):
print file
filename = os.path.basename(file) #获取文件夹名
z1 = filename.find('0') #查找0所在位置
z2 = filename.find('.') #查找.所在位置
s1 = filename[z1+1:z2] #获取更改格式的部分文件夹名
fid = open(file).readlines() #读取文件内所有行
for i in range(len(fid)): #遍历行
str1 = fid[i]
z3 = str1.find('/')
z4 = str1.find(':')
s2 = str1[z3+1:z4-1] #获取更改格式的部分文件名
out_name = str(s1) + '_'+ str(s2) + '.txt' #定义输出文件名
outdir = os.path.join(output,out_name) #定义输出路径
str2 = str1[z4+1:]
#替换:逗号,单个空格,多个空格,括号;然后去掉两端的空格;然后分割存放进列表ss
ss = str(str2).replace(',',' ').replace(';',' ').replace('(',' ').replace(')',' ').replace(' ',' ').replace(' ',' ').strip().split(' ')
print ss
#按照要求交换位置
i = 0
while i < len(ss):
if i % 2 != 0:
(ss[i-1],ss[i]) = (ss[i],ss[i-1])
else:
pass
i += 1
#将列表内容写入文件
f = open(outdir,'wb+')
for j in ss:
f.write(j)
f.write(' ')
f.write('10')
f.close()
print ss
print u'文档','%s'%(filename),u'转换完毕!'
input = r'C:\Users\li\Desktop\LL\*.txt' #输入文件路径
output = r'C:\Users\li\Desktop\2015.11.20' #输出文件路径
for file in glob.glob(input): #遍历输入文件夹内的所有文件
get_txt_list(file,output)
python自动给数字前面补0的方法
python中有一个zfill方法用来给字符串前面补0,非常有用
n = "123"
s = n.zfill(5)
assert s == "00123"zfill()也可以给负数补0
n = "-123"
s = n.zfill(5)
assert s == "-0123"对于纯数字,我们也可以通过格式化的方式来补0
n = 123
s = "%05d" % n
assert s == "00123"http://www.newsmth.net/bbstcon.php?board=Python&gid=59801
对列表使用sort()排序,如何得到对应元素的索引
比如对a = [3,4,1,7,2]用a.sort()排序得到a = [1,2,3,4,7],请问如何得到排序后的
数组元素的索引系列,是说,在原来数组中的索引。
在这个例子里应该是[2,4,0,1,3].
方案1
b = zip(a, range(len(a)))
b.sort(key = lambda x : x[0])
c = [x[1] for x in b]方案2
也可以这样
>>> a = [3,4,1,7,2]
>>> sorted(enumerate(a), key=lambda x:x[1])
[(2, 1), (4, 2), (0, 3), (1, 4), (3, 7)]方案3
In [1]: a = [3,4,1,7,2]
In [2]: enumerate(a)
Out[2]: <enumerate object at 0x8591f0c>
In [3]: list(enumerate(a))
Out[3]: [(0, 3), (1, 4), (2, 1), (3, 7), (4, 2)]
In [4]: from operator import itemgetter
In [5]: sorted(enumerate(a), key=itemgetter(1))
Out[5]: [(2, 1), (4, 2), (0, 3), (1, 4), (3, 7)]
In [6]: [index for index, value in sorted(enumerate(a), key=itemgetter(1))]
Out[6]: [2, 4, 0, 1, 3]
大杀器:
In [7]: import numpy as np
In [8]: np.argsort([3,4,1,7,2])
Out[8]: array([2, 4, 0, 1, 3])方案4
>>> a = [3, 4, 1, 7, 2]
>>> sorted(xrange(len(a)), key=a.__getitem__)
[2, 4, 0, 1, 3]















 5927
5927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











