







递归神经网络的基础知识参考:
https://www.zybuluo.com/hanbingtao/note/626300
自然语言和自然场景解析
- 在自然语言处理任务中,如果我们能够实现一个解析器,将自然语言解析为语法树,那么毫无疑问,这将大大提升我们对自然语言的处理能力。而递归神经网络就能够完成句子的语法分析,并产生一个语法解析树。
- 除了自然语言之外,自然场景也具有可组合的性质。因此,我们可以用类似的模型完成自然场景的解析
下面是代码实现:
代码中涉及的公式推导参考上面的连接。
activator.py
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import numpy as np
class ReluActivator(object):
def forward(self, weighted_input):
#return weighted_input
return max(0, weighted_input)
def backward(self, output):
return 1 if output > 0 else 0
class IdentityActivator(object):
def forward(self, weighted_input):
return weighted_input
def backward(self, output):
return 1
class SigmoidActivator(object):
def forward(self, weighted_input):
return 1.0 / (1.0 + np.exp(-weighted_input))
def backward(self, output):
return output * (1 - output)
class TanhActivator(object):
def forward(self, weighted_input):
return 2.0 / (1.0 + np.exp(-2 * weighted_input)) - 1.0
def backward(self, output):
return 1 - output * output递归神经网络部分组件实现部分:
# -*- coding: UTF-8 -*-
import numpy as np
from activators import IdentityActivator
# 用它保存递归神经网络生成的整棵树,用来构造父和子的关系
class TreeNode(object):
def __init__(self, data, children=[], children_data=[]):
self.parent = None
self.children = children
self.children_data = children_data
self.data = data
for child in children: # 设定子节点的父类
child.parent = self
#print 'here:',child.parent
# 递归神经网络实现
class RecursiveLayer(object):
def __init__(self, node_width, child_count, activator, learning_rate):
'''
递归神经网络构造函数
node_width: 表示每个节点的向量的维度
child_count: 每个父节点有几个子节点
activator: 激活函数对象
learning_rate: 梯度下降算法学习率
'''
self.node_width = node_width
self.child_count = child_count
self.activator = activator
self.learning_rate = learning_rate
# 权重数组W
self.W = np.random.uniform(-1e-4, 1e-4,
(node_width, node_width * child_count))
# 偏置项b
self.b = np.zeros((node_width, 1))
# 递归神经网络生成的树的根节点
self.root = None
def forward(self, *children): # 可变参数的用法参考https://blog.csdn.net/lilong117194/article/details/80091217
'''
前向计算
'''
children_data = self.concatenate(children)
#print 'children_data:', children_data
parent_data = self.activator.forward(np.dot(self.W, children_data) + self.b)
#print 'parent_data:',parent_data
print 'children:',children
self.root = TreeNode(parent_data, children, children_data)
print 'tt..',self.root
print 'self.root.children:',self.root.children
def backward(self, parent_delta):
'''
BPTS反向传播算法
'''
self.calc_delta(parent_delta, self.root)
self.W_grad, self.b_grad = self.calc_gradient(self.root)
def update(self):
'''
使用SGD算法更新权重
'''
self.W -= self.learning_rate * self.W_grad
self.b -= self.learning_rate * self.b_grad
def reset_state(self):
self.root = None
def concatenate(self, tree_nodes):
'''
将各个树节点中的数据拼接成一个长向量
'''
concat = np.zeros((0,1))
for node in tree_nodes:
concat = np.concatenate((concat, node.data))
#print 'concat:',concat
return concat
# 这里是难点
def calc_delta(self, parent_delta, parent):
'''
计算每个节点的delta
'''
parent.delta = parent_delta
if parent.children:
# 根据式2计算每个子节点的delta(只是下一层的)
children_delta = np.dot(self.W.T, parent_delta) * (
self.activator.backward(parent.children_data))
print 'children_delta——>',children_delta
# slices = [(子节点编号,子节点delta起始位置,子节点delta结束位置)]
slices = [(i, i * self.node_width,
(i + 1) * self.node_width)
for i in range(self.child_count)]
print 'slices:',slices
# 针对每个子节点,递归调用calc_delta函数
for s in slices:
print 'children_delta[s[1]:s[2]]:',children_delta[s[1]:s[2]]
print 'parent.children[s[0]]):',parent.children[s[0]]
self.calc_delta(children_delta[s[1]:s[2]], parent.children[s[0]])
def calc_gradient(self, parent):
'''
计算每个节点权重的梯度,并将它们求和,得到最终的梯度
'''
W_grad = np.zeros((self.node_width, self.node_width * self.child_count))
b_grad = np.zeros((self.node_width, 1))
if not parent.children:
return W_grad, b_grad
parent.W_grad = np.dot(parent.delta, parent.children_data.T)
parent.b_grad = parent.delta
W_grad += parent.W_grad
b_grad += parent.b_grad
for child in parent.children:
W, b = self.calc_gradient(child)
W_grad += W
b_grad += b
return W_grad, b_grad
# 打印输出
def dump(self, **kwArgs):
print 'root.data: %s' % self.root.data
print 'root.children_data: %s' % self.root.children_data
if kwArgs.has_key('dump_grad'):
print 'W_grad: %s' % self.W_grad
print 'b_grad: %s' % self.b_grad
def data_set():
children = [TreeNode(np.array([[1],[2]])),
TreeNode(np.array([[3],[4]])),
TreeNode(np.array([[5],[6]]))]
d = np.array([[0.5],[0.8]])
return children, d
def gradient_check():
'''
梯度检查
'''
# 设计一个误差函数,取所有节点输出项之和
error_function = lambda o: o.sum()
rnn = RecursiveLayer(2, 2, IdentityActivator(), 1e-3)
# 计算forward值
x, d = data_set()
rnn.forward(x[0], x[1])
rnn.forward(rnn.root, x[2])
# 求取sensitivity map
sensitivity_array = np.ones((rnn.node_width, 1),dtype=np.float64)
# 计算梯度
rnn.backward(sensitivity_array)
# 检查梯度
epsilon = 10e-4
for i in range(rnn.W.shape[0]):
for j in range(rnn.W.shape[1]):
rnn.W[i,j] += epsilon
rnn.reset_state()
rnn.forward(x[0], x[1])
rnn.forward(rnn.root, x[2])
err1 = error_function(rnn.root.data)
rnn.W[i,j] -= 2*epsilon
rnn.reset_state()
rnn.forward(x[0], x[1])
rnn.forward(rnn.root, x[2])
err2 = error_function(rnn.root.data)
expect_grad = (err1 - err2) / (2 * epsilon)
rnn.W[i,j] += epsilon
print 'weights(%d,%d): expected - actural %.4e - %.4e' % (
i, j, expect_grad, rnn.W_grad[i,j])
return rnn
def test():
children, d = data_set()
# node_width, child_count, activator, learning_rate
rnn = RecursiveLayer(2, 2, IdentityActivator(), 1e-3)
rnn.forward(children[0], children[1])
rnn.dump() # 打印输出父子节点的关系和data
rnn.forward(rnn.root, children[2])
rnn.dump()
rnn.backward(d)
rnn.dump(dump_grad='true')
return rnn
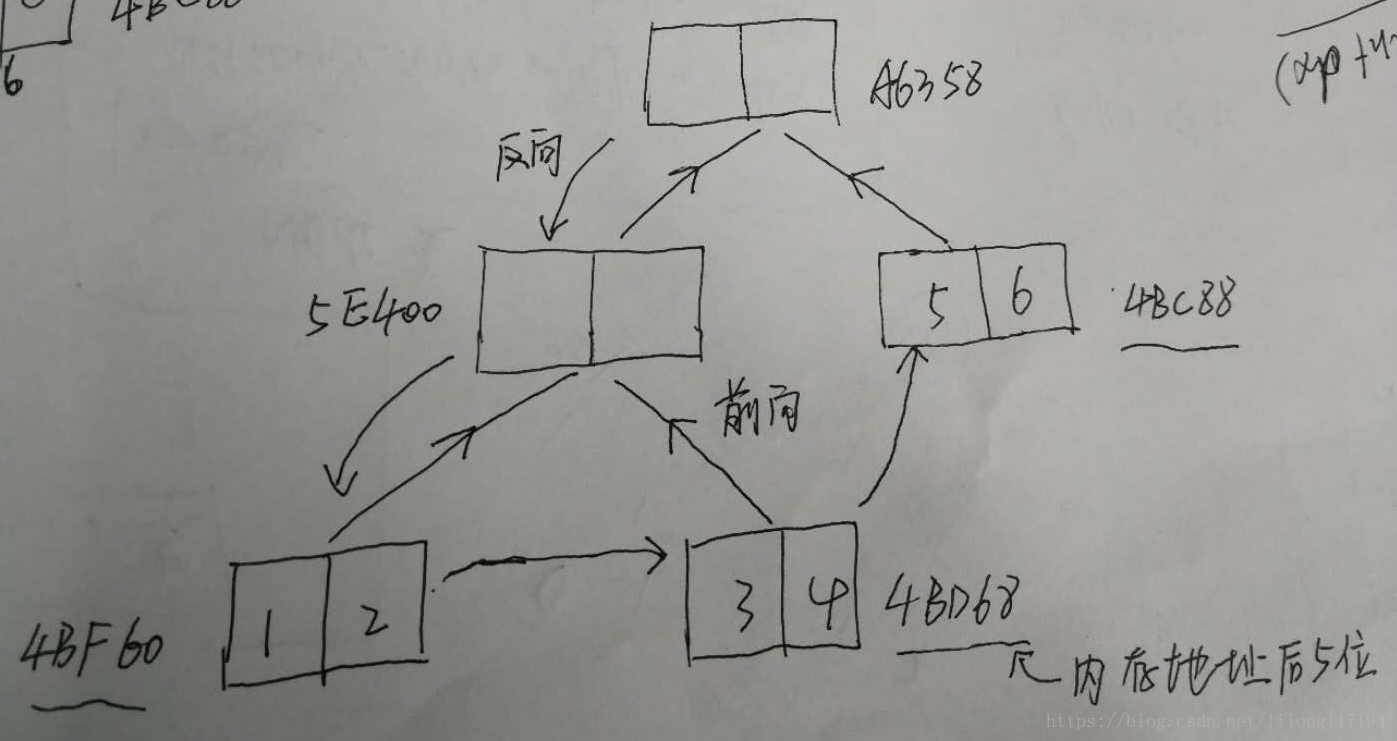
test()运行结果:
children: (<__main__.TreeNode object at 0x000000000BA4BF60>, <__main__.TreeNode object at 0x000000000BA4BD68>)
tt.. <__main__.TreeNode object at 0x000000000BA5E400>
self.root.children: (<__main__.TreeNode object at 0x000000000BA4BF60>, <__main__.TreeNode object at 0x000000000BA4BD68>)
root.data: [[ 8.10365462e-05]
[ -1.20068464e-06]]
root.children_data: [[ 1.]
[ 2.]
[ 3.]
[ 4.]]
children: (<__main__.TreeNode object at 0x000000000BA5E400>, <__main__.TreeNode object at 0x000000000BA4BC88>)
tt.. <__main__.TreeNode object at 0x000000000BAA6358>
self.root.children: (<__main__.TreeNode object at 0x000000000BA5E400>, <__main__.TreeNode object at 0x000000000BA4BC88>)
root.data: [[ 8.67226403e-05]
[ -2.18991385e-04]]
root.children_data: [[ 8.10365462e-05]
[ -1.20068464e-06]
[ 5.00000000e+00]
[ 6.00000000e+00]]
children_delta——> [[ -3.40659777e-05]
[ 7.72187116e-05]
[ -2.12167087e-05]
[ -4.29089851e-06]]
slices: [(0, 0, 2), (1, 2, 4)]
children_delta[s[1]:s[2]]: [[ -3.40659777e-05]
[ 7.72187116e-05]]
parent.children[s[0]]): <__main__.TreeNode object at 0x000000000BA5E400>
children_delta——> [[ -2.03214060e-09]
[ 4.49859993e-09]
[ -1.02736169e-08]
[ 5.25062172e-09]]
slices: [(0, 0, 2), (1, 2, 4)]
children_delta[s[1]:s[2]]: [[ -2.03214060e-09]
[ 4.49859993e-09]]
parent.children[s[0]]): <__main__.TreeNode object at 0x000000000BA4BF60>
children_delta[s[1]:s[2]]: [[ -1.02736169e-08]
[ 5.25062172e-09]]
parent.children[s[0]]): <__main__.TreeNode object at 0x000000000BA4BD68>
children_delta[s[1]:s[2]]: [[ -2.12167087e-05]
[ -4.29089851e-06]]
parent.children[s[0]]): <__main__.TreeNode object at 0x000000000BA4BC88>
root.data: [[ 8.67226403e-05]
[ -2.18991385e-04]]
root.children_data: [[ 8.10365462e-05]
[ -1.20068464e-06]
[ 5.00000000e+00]
[ 6.00000000e+00]]
W_grad: [[ 6.45229542e-06 -6.87322977e-05 2.49989780e+00 2.99986374e+00]
[ 1.42047949e-04 1.53476876e-04 4.00023166e+00 4.80030887e+00]]
b_grad: [[ 0.49996593]
[ 0.80007722]]代码中做了一些打印输出,以便于理解代码。
这里要注意几点:
- 由于权重是在所有层共享的,所以和循环神经网络一样,递归神经网络的最终的权重梯度是各个层权重梯度之和。
- 网络的树构建大概是这样的:
具体的实现流程还要看代码。 - 这里没有进行梯度检查,但在上一篇lstm中实现过,这里的原理都是一样的。
- 整个代码架构的搭建是难点
通过初步学习递归神经网络的实现和应用场景,感觉递归神经网络很神奇,期待进一步的深入学习。














 3854
3854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









