







转自:http://blog.csdn.net/zhoufoxcn/article/details/5343254
在 .NET 中提供了对正则表达式的支持,并且提供了相关的类,分别有: Regex 、 Match 、 Group 、 Capture 、 RegexOptions 、 MatchCollection 、 GroupCollection 、 CaptureCollection 。它们之间的关联如下:

对它们描述如下:
Regex :正则表达式类,代表了一个不可变的正则表达式。
Match :代表了 Regex 类的实例的一次匹配结果,可以通过 Regex 的 Match() 实例方法返回一个 Match 的实例。
MatchCollection :代表了 Regex 类的实例的所有匹配结果,可以通过 Regex 的 Matches() 实例方法返回一个 MatchCollection 的实例。
Group :表示单个捕获组的结果。由于一次匹配可能包含 0 个、 1 个或多个分组,所以 Match 的实例中返回的是捕获组集合的结果,即 GroupCollection 。
GroupCollection :表示单个匹配中的多个捕获组的集合,可以通过 Match 的 Groups 实例属性返回 GroupCollection 的实例。
Capture :表示单个捕获中的一个子字符串。同 Group 一样,由于一个捕获中可能包含 0 个、 1 个或多个子字符串,所以 Group 的实例中返回的是子字符串集合的结果,即 CaptureCollection 。
CaptureCollection :默认表示按照从里到外、从左到右的顺序由捕获组匹配到的所有子字符串集合,可以通过 Group 或者 Match 的 Captures 实例属性返回 CaptureCollection 的实例。注意,可以使用 RegexOptions.RightToLeft 来改变这种匹配顺序。
RegexOptions :提供用于设置正则表达式选项的枚举值。 像上面提到的 RightToLeft 就是它的一个枚举值之一,除此之外还有 None 、 IgnoreCase 、 Multiline 、 ExplicitCapture 、 Compiled 、 Singleline 、 IgnorePatternWhitespace 、 RightToLeft 、 ECMAScript 及 CultureInvariant 。 RegexOptions 枚举值可以相加,比如我们想匹配不区分大小写的字符串“ abc ”并且还想提高一下执行速度,那么可以写如下代码:
RegexOptions options=RegexOptions.IgnoreCase|RegexOptions.Compiled;
Regex regex=new Regex("abc",options);
Regex 、 Match 、 Group 及 Capture 的关系及成员
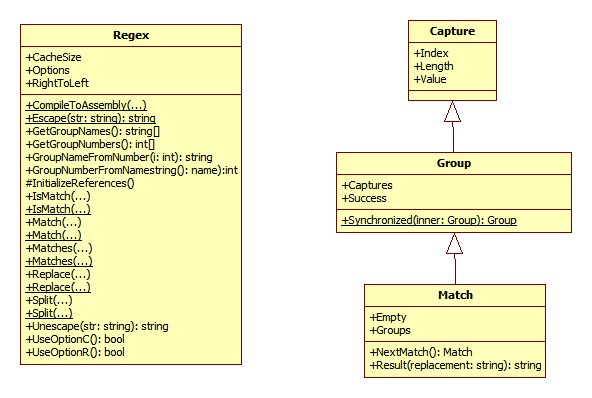
Group概念:
在((/d+)([a-z]))/s+这个正则表达式里总共包含了四个Group,即分组,按照默认的从左到右的匹配方式,其中Groups[0]代表了整个分组,其它的则是子分组,用示意图表示如下:
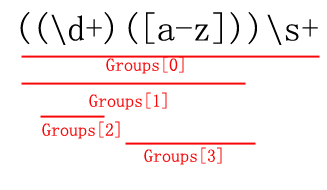
命名捕获组
采用命名捕获组。
就像我们使用 DataReader 访问数据库或者访问 DataTable 中的数据一样,可以使用索引的方式(索引同样也是从 0 开始),不过如果变化了 select 语句中的字段数或者字段顺序,按照这种方式获取数据就需要重新变动,为了适应这种变化,同样也允许使用字段名作为索引来访问数据,只要数据源中存在这个字段而不管顺序如何都会取到正确的值。在正则表达式中命名捕获组也可以起到同样的作用。
普通捕获组表示方式: ( 正则表达式 ) ,如 (/d{8,11}) ;
命名捕获组表示方式: (?< 捕获组命名 > 正则表达式),如 (?<phone>/d{8,11})
对于普通捕获组只能采用索引的方式获取它对应的值,但对于命名捕获组,还可以采用按名称的方式访问,例如 (?<phone>/d{8,11}) ,在代码中就可以按照 match.Groups["phone"] 的方式访问,这样代码更直观,编码也更灵活
非捕获组
如果经常看别人有关正则表达式的源代码,可能会看到形如 (?: 子表达式 ) 这样的表达式,这就是非捕获组,对于捕获组我们可以理解,就是在后面的代码中可以通过索引或者名称(如果是命名捕获组)的方式来访问匹配的值,因为在匹配过程中会将对应的值保存到内存中,如果我们在后面不需要访问匹配的值那么就可以告诉程序不用在内存中保存匹配的值,以便提高效率减少内存消耗,这种情况下就可以使用非捕获组,例如在刚刚分析 IIS 日志的时候我们对客户端提交请求的方式并不在乎,在这里就可以使用非捕获组,如下:
- Regex regex = new Regex(@"(?<time>(0[0-9]|1[0-9]|2[0-3])(:[0-5][0-9]){2})/s(?:GET)/s(?<url>[^/s]+)/s(?<ip>/d{1,3}(/./d{1,3}){3})/s(?<httpCode>/d{3})";
其实匹配概念:
注意上面的MatchCollection matchCollection = r.Matches(text,48)表示从text字符串的位置48处开始匹配,要注意位置0位于整个字符串的之前,位置1位于字符串中第一个字符之后第二个字符之前,示意图如下(注意是字符串“1A”与“2B”之间有空格):
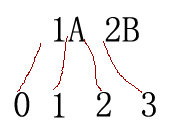
在text的位置48处正好是15M中的5处,因此返回的第一个Match是5M而不是15M。
正则表达式基础:
正则表达式元字符
正则表达式语言由两种基本字符类型组成:原义(正常)文本字符和元字符。元字符使正则表达式具有处理能力。元字符既可以是放在 [] 中的任意单个字符(如 [a] 表示匹配单个小写字符 a ),也可以是字符序列(如 [a-d] 表示匹配 a 、 b 、 c 、 d 之间的任意一个字符,而 /w 表示任意英文字母和数字及下划线),下面是一些常见的元字符:
| 元字符 | 说明 |
| . | 匹配除 /n 以外的任何字符(注意元字符是小数点)。 |
| [abcde] | 匹配 abcde 之中的任意一个字符 |
| [a-h] | 匹配 a 到 h 之间的任意一个字符 |
| [^fgh] | 不与 fgh 之中的任意一个字符匹配 |
| /w | 匹配大小写英文字符及数字 0 到 9 之间的任意一个及下划线,相当于 [a-zA-Z0-9_] |
| /W | 不匹配大小写英文字符及数字 0 到 9 之间的任意一个,相当于 [^a-zA-Z0-9_] |
| /s | 匹配任何空白字符,相当于 [ /f/n/r/t/v] |
| /S | 匹配任何非空白字符,相当于 [^/s] |
| /d | 匹配任何 0 到 9 之间的单个数字,相当于 [0-9] |
| /D | 不匹配任何 0 到 9 之间的单个数字,相当于 [^0-9] |
| [/u4e00-/u9fa5] | 匹配任意单个汉字(这里用的是 Unicode 编码表示汉字的 ) |
正则表达式限定符
上面的元字符都是针对单个字符匹配的,要想同时匹配多个字符的话,还需要借助限定符。下面是一些常见的限定符 ( 下表中 n 和 m 都是表示整数,并且 0<n<m) :
| 限定浮 | 说明 |
| * | 匹配 0 到多个元字符,相当于 {0,} |
| ? | 匹配 0 到 1 个元字符,相当于 {0,1} |
| {n} | 匹配 n 个元字符 |
| {n,} | 匹配至少 n 个元字符 |
| {n,m} | 匹配 n 到 m 个元字符 |
| + | 匹配至少 1 个元字符,相当于 {1,} |
| /b | 匹配单词边界 |
| ^ | 字符串必须以指定的字符开始 |
| $ | 字符串必须以指定的字符结束 |
说明:
( 1 )由于在正则表达式中“ / ”、“ ? ”、“ * ”、“ ^ ”、“ $ ”、“ + ”、“(”、“)”、“ | ”、“ { ”、“ [ ”等字符已经具有一定特殊意义,如果需要用它们的原始意义,则应该对它进行转义,例如希望在字符串中至少有一个“ / ”,那么正则表达式应该这么写: //+ 。
( 2 )可以将多个元字符或者原义文本字符用括号括起来形成一个分组,比如 ^(13)[4-9]/d{8}$ 表示任意以 13 开头的移动手机号码。
( 3 )另外对于中文字符的匹配是采用其对应的 Unicode 编码来匹配的,对于单个 Unicode 字符,如 /u4e00 表示汉字“一”, /u9fa5 表示汉字“龥”,在 Unicode 编码中这分别是所能表示的汉字的第一个和最后一个的 Unicode 编码,在 Unicode 编码中能表示 20901 个汉字。
( 4 )关于 /b 的用法,它代表单词的开始或者结尾,以字符串“ 123a 345b 456 789d ”作为示例字符串,如果正则表达式是“ /b/d{3}/b ”,则仅能匹配 456 。
( 5 )可以使用“ | ”来表示或的关系,例如 [z|j|q] 表示匹配 z 、 j 、 q 之中的任意一个字母。
零宽度断言
关于零宽度断言有多种叫法,也有叫环视、也有叫预搜索的,我这里采用的是 MSDN 中的叫法,关于零宽度断言有以下几种:
(?= 子表达式 ): 零宽度正预测先行断言。仅当子表达式在此位置的右侧匹配时才继续匹配。例如, 19(?=99) 与跟在 99 前面的 19 实例匹配。
(?! 子表达式 ): 零宽度负预测先行断言。仅当子表达式不在此位置的右侧匹配时才继续匹配。例如, (?!99) 与不以 99 结尾的单词匹配,所以不与 1999 匹配。
(?<= 子表达式 ): 零宽度正回顾后发断言。仅当子表达式在此位置的左侧匹配时才继续匹配。例如, (?<=19)99 与跟在 19 后面的 99 的实例匹配。此构造不会回溯。
(?<! 子表达式 ): 零宽度负回顾后发断言。仅当子表达式不在此位置的左侧匹配时才继续匹配。例如 (?<=19) 与不以 19 开头的单词匹配,所以不与 1999 匹配。
正则表达式选项
在使用正则表达式时除了使用 RegexOptions 这个枚举给正则表达式赋予一些额外的选项之外,还可以在在表达式中使用这些选项,如:
- Regex regex = new Regex("(?i)def");
它与下面一句是等效的:
- Regex regex = new Regex("def", RegexOptions.IgnoreCase);
采用 (?i) 这种形式的称之为内联模式,顾名思义就是在正则表达式中已经体现了正则表达式选项,这些内联字符与 RegexOptions 的对应如下:
IgnoreCase :内联字符为 i ,指定不区分大小写的匹配。
Multiline :内联字符为 m ,指定多行模式。更改 ^ 和 $ 的含义,以使它们分别与任何行的开头和结尾匹配,而不只是与整个字符串的开头和结尾匹配。
ExplicitCapture :内联字符为 n ,指定唯一有效的捕获是显式命名或编号的 (?<name> … ) 形式的组。这允许圆括号充当非捕获组,从而避免了由 (?: … ) 导致的语法上的笨拙。
Singleline :内联字符为 s ,指定单行模式。更改句点字符 (.) 的含义,以使它与每个字符(而不是除 /n 之外的所有字符)匹配。
IgnorePatternWhitespace :内联字符为 x ,指定从模式中排除非转义空白并启用数字符号 (#) 后面的注释。(有关转义空白字符的列表,请参见字符转义。) 请注意,空白永远不会从字符类中消除。
举例说明:
- RegexOptions option=RegexOptions.IgnoreCase|RegexOptions.Singleline;
- Regex regex = new Regex("def", option);
用内联的形式表示为:
- Regex regex = new Regex("(?is)def");















 4562
4562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









