







java学习脚印:xml中空白文本结点(whitespace TextNode)处理及验证方法
1.空白结点在解析过程中引起的麻烦
首先来看下一个非常简单的xml文件,如下:
清单1-1 books-no.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <books>
- <book>
- <title>Harry Potter</title>
- <author>J K. Rowling</author>
- </book>
- </books>
我们在1-1中看到的DOM树结点关系图如下图所示:
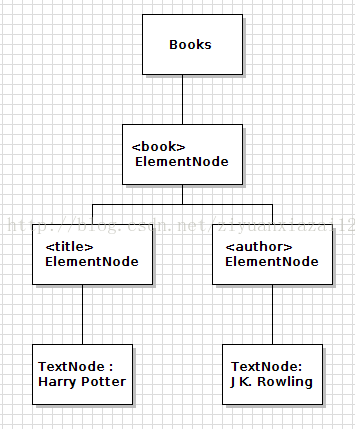
由于xml规范允许空白字符的文本结点,因此实际上就会包含一些空白字符的文本结点(我们的本意也许并不想包含空白字符结点,但是在编辑时可能无意引入了空白字符)。
利用vim的搜索空白字符功能,我们看下图:
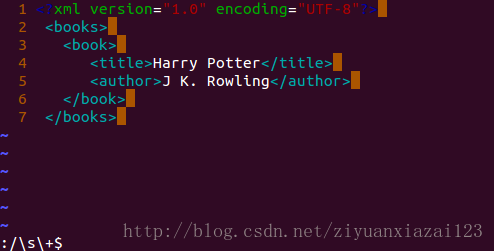
其中黄色高亮显式的部分为空白字符,其中2-6行的空白字符生成了空白结点,这样实际的DOM树结点关系图如下:
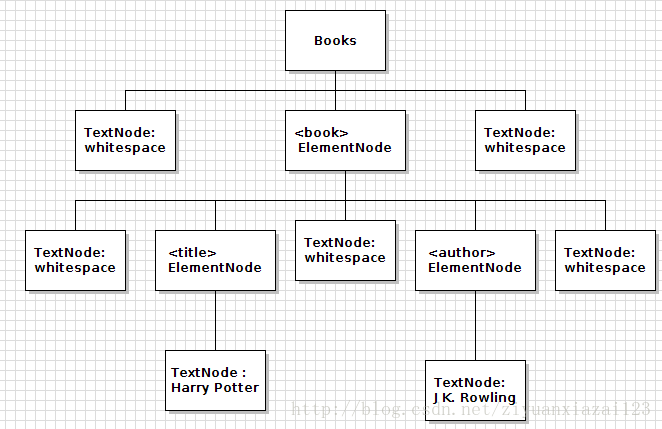
空白字符文本结点的出现,导致在没有使用验证方式时,遍历DOM树要做过多的结点类型检测,可以参看清单2-6 DOMParserDemo.java ,观察代码以加强理解。
2.提供验证,避免空白结点引起的麻烦
xml文件使用dtd或者xsd Schema模式来验证xml文件。
首先,我们来看配合dtd验证文件的xml。
清单 2-1 books.dtd
- <!ELEMENT books (book)*>
- <!ELEMENT book (title,author)>
- <!ELEMENT title (#PCDATA)>
- <!ELEMENT author (#PCDATA)>
清单2-2 books-dtd.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE books SYSTEM "books.dtd">
- <books>
- <book>
- <title>Harry Potter</title>
- <author>J K. Rowling</author>
- </book>
- </books>
另一种方式是采用xsd文件验证。
清单2-3 books.xsd
- <?xml version="1.0" encoding="UTF-8"?>
- <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
- <xs:element name="books">
- <xs:complexType>
- <xs:sequence>
- <xs:element name="book" maxOccurs="unbounded">
- <xs:complexType>
- <xs:sequence>
- <xs:element name="title" type="xs:string"/>
- <xs:element name="author" type="xs:string"/>
- </xs:sequence>
- </xs:complexType>
- </xs:element>
- </xs:sequence>
- </xs:complexType>
- </xs:element>
- </xs:schema>
清单2-4 books-xsd.xml
- <?xml version="1.0" encoding="UTF-8"?>
- <books xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:noNamespaceSchemaLocation="books.xsd">
- <book>
- <title>Harry Potter</title>
- <author>J K. Rowling</author>
- </book>
- </books>
为了提高代码的重用性,我们可以根据验证文件类型,对解析器进行配置,可参考如下代码。
清单2-5 ParserUtil.java
- package com.learningjava;
- import java.io.File;
- import java.io.IOException;
- import javax.xml.parsers.DocumentBuilder;
- import javax.xml.parsers.DocumentBuilderFactory;
- import javax.xml.parsers.ParserConfigurationException;
- import org.w3c.dom.Document;
- import org.w3c.dom.Node;
- import org.w3c.dom.NodeList;
- import org.w3c.dom.Text;
- import org.xml.sax.SAXException;
- /**
- * This class is a util class to help parse xml file
- * @author wangdq
- * 2011-11-10
- */
- public class ParserUtil {
- /**
- * build and configure dom parser according to the filepath
- * we test the filepath,if contain 'dtd' or 'xsd'
- *
- * @param filePath the path of xml file
- * @return the DOM Document Obeject
- */
- public static Document getDocument(String filePath) {
- Document document = null;
- try {
- //step1: get DocumentBuilderFactory
- DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
- //configure the factory to set validate mode
- boolean dtdValidate = false;
- boolean xsdValidate = false;
- if(filePath.contains("dtd")) {
- dtdValidate = true;
- } else if(filePath.contains("xsd")) {
- xsdValidate = true;
- dbFactory.setNamespaceAware(true);
- final String JAXP_SCHEMA_LANGUAGE =
- "http://java.sun.com/xml/jaxp/properties/schemaLanguage";
- final String W3C_XML_SCHEMA =
- "http://www.w3.org/2001/XMLSchema";
- dbFactory.setAttribute(JAXP_SCHEMA_LANGUAGE, W3C_XML_SCHEMA);
- }
- dbFactory.setValidating(dtdValidate || xsdValidate);
- dbFactory.setIgnoringElementContentWhitespace(dtdValidate || xsdValidate);
- //parse an XML file into a DOM tree
- DocumentBuilder builder = dbFactory.newDocumentBuilder();
- document = builder.parse(new File(filePath));
- }catch (ParserConfigurationException | SAXException | IOException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- return document;
- }
- /**
- * print element and text node of the given node
- * @param level the dom tree level ,the root is at level 1
- * @param node the node to print
- */
- public static void printElementAndTextNode(int level,Node node) {
- final int INDENT = 4;
- if(node.getNodeType() == Node.ELEMENT_NODE)
- {
- System.out.printf("%" + INDENT*level + "s+%d", " ",level);
- System.out.format(" ELEMENT: <%s> %n",node.getNodeName());
- int newLevel = level+1;
- NodeList childList = node.getChildNodes();
- for(int ix = 0;ix<childList.getLength();ix++) {
- printElementAndTextNode(newLevel,childList.item(ix));
- }
- } else if(node.getNodeType() == Node.TEXT_NODE) {
- Text textNode = (Text)node;
- System.out.printf("%" + INDENT*level + "s+%d", " ",level);
- String data = textNode.getData().trim();
- System.out.format(" TEXT: \"%s\" %n",data);
- }
- }
- /**
- * remove whitespace textnode
- * note,here we only consider the ELEMENT_NODE and TEXT_NODE
- * @param node the node needed to purify by removing whitespace textnode
- * @return the nums of whitespace textnode that had been removed
- */
- public static int removeWhiteSpaceTextElement(Node node) {
- int count = 0;
- if(node == null)
- return 0;
- //System.out.println("visting :"+node.getNodeName());
- if(node.getNodeType() == Node.ELEMENT_NODE)
- {
- //iterate child node
- for(Node childNode = node.getFirstChild(); childNode!=null;){
- Node nextChild = childNode.getNextSibling();
- // Do something with childNode, including move or delete...
- count += removeWhiteSpaceTextElement(childNode);
- childNode = nextChild;
- }
- } else if(node.getNodeType() == Node.TEXT_NODE) {
- Text textNode = (Text)node;
- String data = textNode.getData().trim();
- if(data.isEmpty()) {
- //remove whitespace textNode
- //System.out.println("remove "+textNode.getNodeName());
- textNode.getParentNode().removeChild(textNode);
- count++;
- }
- }
- return count;
- }
- }
下面给出不使用验证方式,以及使用dtd和xsd文件对xml进行验证的三种方式解析books xml文件的代码,可通过对比增强理解。
清单2-6 DOMParserDemo.java
- package com.learningjava;
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- import org.w3c.dom.Node;
- import org.w3c.dom.NodeList;
- import org.w3c.dom.Text;
- /**
- * This program illustrate ways to validate xml
- * @author wangdq
- * 2013-11-10
- */
- public class DOMParserDemo {
- public static void main(String[] args) {
- //use dtd to validate books-dtd.xml
- TimeCounter.start();
- parseWithValidate("books-dtd.xml");
- System.out.format("dtd validate,consumed: %d ns%n%n",TimeCounter.end());
- //use schema to validate books-xsd.xml
- TimeCounter.start();
- parseWithValidate("books-xsd.xml");
- System.out.format("xsd validate,consumed: %d ns%n%n",TimeCounter.end());
- //not using validation
- TimeCounter.start();
- parseWithNoValidate("books-no.xml");
- System.out.format("not validate,consumed: %d ns%n%n",TimeCounter.end());
- }
- public static void parseWithValidate(String filepath) {
- Document doc = ParserUtil.getDocument(filepath);
- //traverse nodelist
- // get root element (Level1)
- Element rootElement = doc.getDocumentElement();
- //get Level2 element
- Element book = (Element)rootElement.getFirstChild();
- //get Level3 element
- NodeList children = book.getChildNodes();
- for(int iy = 0;iy<children.getLength();iy++) {
- Node child = children.item(iy);
- //get Level4 element
- Text textNode = (Text)child.getFirstChild();
- System.out.format("%s%n",textNode.getData().trim());
- }
- }
- public static void parseWithNoValidate(String filepath) {
- Document doc = ParserUtil.getDocument(filepath);
- //traverse nodelist
- //get root element (Level1)
- Element rootElement = doc.getDocumentElement();
- //get Level2 element
- NodeList nodeList = rootElement.getChildNodes();
- for(int ix = 0;ix<nodeList.getLength();ix++) {
- Node node = nodeList.item(ix);
- if(node.getNodeType() == Node.ELEMENT_NODE) {
- //get Level3 element
- NodeList children = node.getChildNodes();
- for(int iy = 0;iy<children.getLength();iy++) {
- Node child = children.item(iy);
- if(child.getNodeType() == Node.ELEMENT_NODE) {
- //get Level4 element
- Text textNode = (Text)child.getFirstChild();
- System.out.format("%s%n",textNode.getData().trim());
- }
- }
- }
- }
- }
- }
- /**
- * calculate time consumed
- */
- class TimeCounter {
- public static void start() {
- startTime = System.nanoTime();
- }
- public static long end() {
- return System.nanoTime() - startTime;
- }
- private static long startTime;
- }
运行输出
Harry Potter
J K. Rowling
dtd validate,consumed: 98839944 ns
Harry Potter
J K. Rowling
xsd validate,consumed: 68073601 ns
Harry Potter
J K. Rowling
not validate,consumed: 4853899 ns
可见,虽然验证方式简化了代码,但是也增了处理的时间。
3.去除空白结点
如果在处理xml文件之前就把空白字符结点去掉,那样也是提高解析速度的一种方法。
上面的辅助类ParserUtil类中给出了打印树结点和删除空白字符结点的方法,下面的代码给出了空白结点删除前后,1-1 books-no.xml文件的结点结构。
清单 3-1 PrintNodeDemo.java
- package com.learningjava;
- import org.w3c.dom.Document;
- import org.w3c.dom.Element;
- /**
- * This program print simple DOM tree node
- * @author wangdq
- * 2011-11-10
- */
- public class PrintNodeDemo {
- public static void main(String[] args) {
- Document doc = ParserUtil.getDocument("books-no.xml");
- Element rootElement = doc.getDocumentElement();
- //before whitespace node removed
- System.out.format("Node Architecture of %s as follow:%n%n","books-no.xml");
- ParserUtil.printElementAndTextNode(1,rootElement);
- //remove whitespace node
- System.out.format("%nremoved %d whitespace node.%n",
- ParserUtil.removeWhiteSpaceTextElement(rootElement));
- System.out.format("after removed: %n%n");
- ParserUtil.printElementAndTextNode(1,rootElement);
- }
- }
运行输出
Node Architecture of books-no.xml as follow:
+1 ELEMENT: <books>
+2 TEXT: ""
+2 ELEMENT: <book>
+3 TEXT: ""
+3 ELEMENT: <title>
+4 TEXT: "Harry Potter"
+3 TEXT: ""
+3 ELEMENT: <author>
+4 TEXT: "J K. Rowling"
+3 TEXT: ""
+2 TEXT: ""
removed 5 whitespace node.
after removed:
+1 ELEMENT: <books>
+2 ELEMENT: <book>
+3 ELEMENT: <title>
+4 TEXT: "Harry Potter"
+3 ELEMENT: <author>
+4 TEXT: "J K. Rowling"
这里注意一点,就是删除空白字符结点的时候,避免使用这一版的代码:
- /**
- * This code will not work to remove whitespace text node
- */
- public static int removeWhiteSpaceTextElement_failed(Node node) {
- int count = 0;
- if(node == null)
- return 0;
- System.out.println("visting :"+node.getNodeName());
- if(node.getNodeType() == Node.ELEMENT_NODE)
- {
- NodeList childList = node.getChildNodes();
- //iterate childList
- //here we can not guarantee the node order after remove element
- //so this incur errors
- for(int ix = 0;ix<childList.getLength();ix++) {
- count += removeWhiteSpaceTextElement_failed(childList.item(ix));
- }
- } else if(node.getNodeType() == Node.TEXT_NODE) {
- Text textNode = (Text)node;
- String data = textNode.getData().trim();
- if(data.isEmpty()) {
- //remove whitespace textNode
- //System.out.println("remove "+textNode.getNodeName());
- textNode.getParentNode().removeChild(textNode);
- count++;
- }
- }
- return count;
- }
因为NodeList对象会动态更新,当删除了子节点之后,再按照原先的索引就得不到相应的子节点,因而引发了与迭代相关的错误,这一点值得引起注意。
通过对比移除空白字符结点,前后的树形结构图,相信你对空白字符结点以及xml验证有了一个很好的理解。














 1957
1957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









