







学习网址:https://www.tensorflow.org/get_started/get_started
This guide gets you started programming in TensorFlow. Before using this guide, install TensorFlow. To get the most out of this guide, you should know the following:
- How to program in Python.
- At least a little bit about arrays.
- Ideally, something about machine learning. However, if you know little or nothing about machine learning, then this is still the first guide you should read.
- Python编程.
- 数组知识(线性代数相关知识).
- 机器学习相关知识
Tensors
The central unit of data in TensorFlow is the tensor. A tensor consists of a set of primitive values shaped into an array of any number of dimensions. A tensor's rank is its number of dimensions. Here are some examples of tensors:
3 # a rank 0 tensor; this is a scalar with shape []
[1. ,2., 3.] # a rank 1 tensor; this is a vector with shape [3]
[[1., 2., 3.], [4., 5., 6.]] # a rank 2 tensor; a matrix with shape [2, 3]
[[[1., 2., 3.]], [[7., 8., 9.]]] # a rank 3 tensor with shape [2, 1, 3]
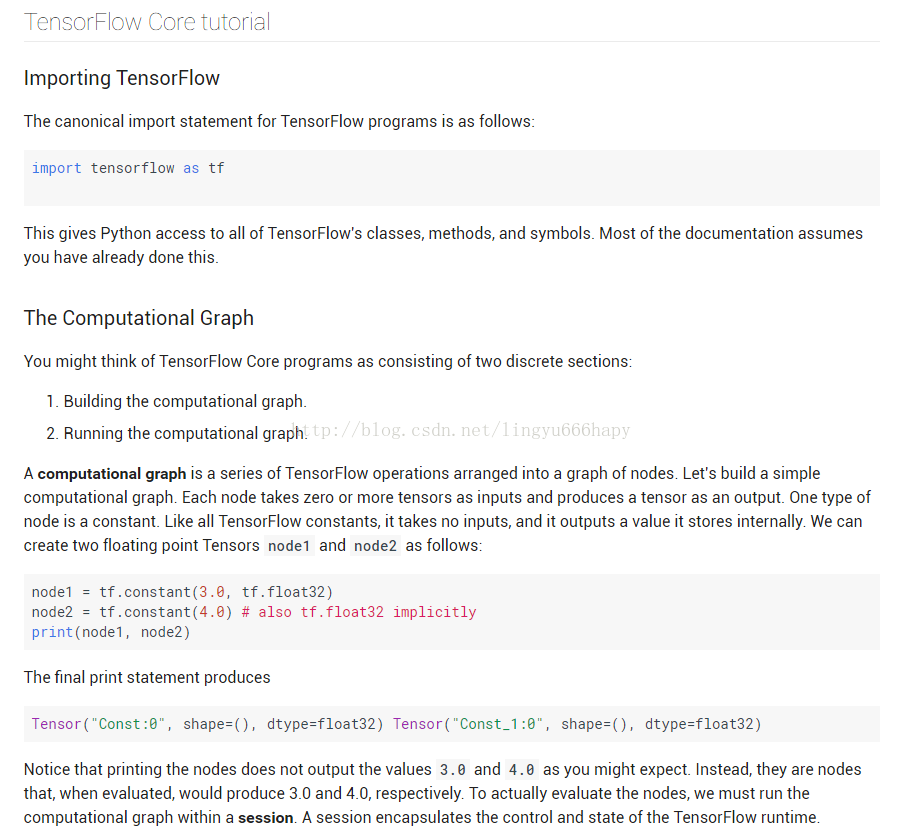

总体上看,这是一些常量的使用方法,应当没什么可以解释的,继续下面
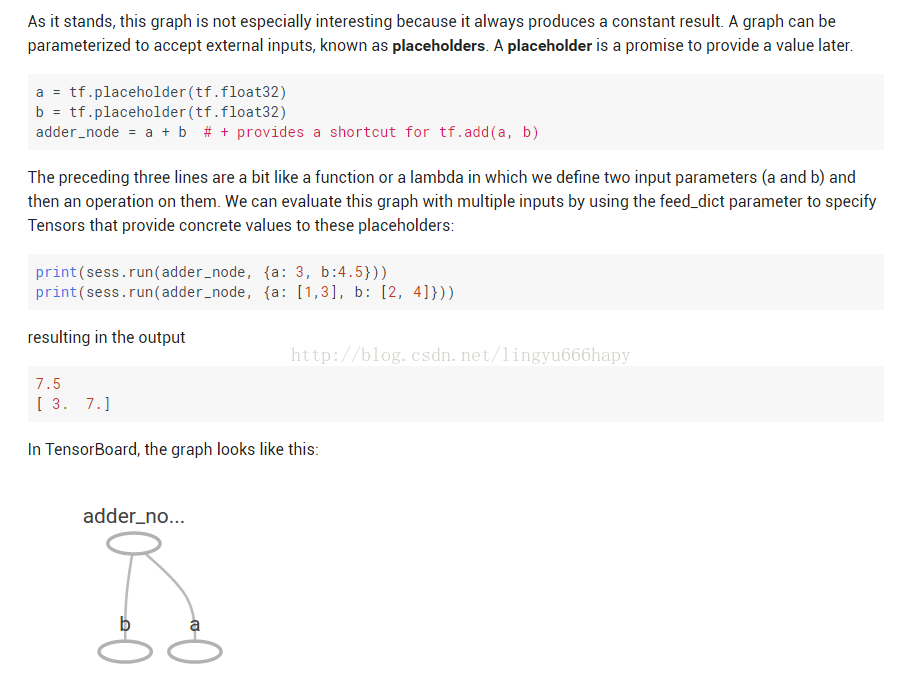
这里面来了一个placeholders,应该是属于变量输入的接口了(暂时如此理解),继续往下看
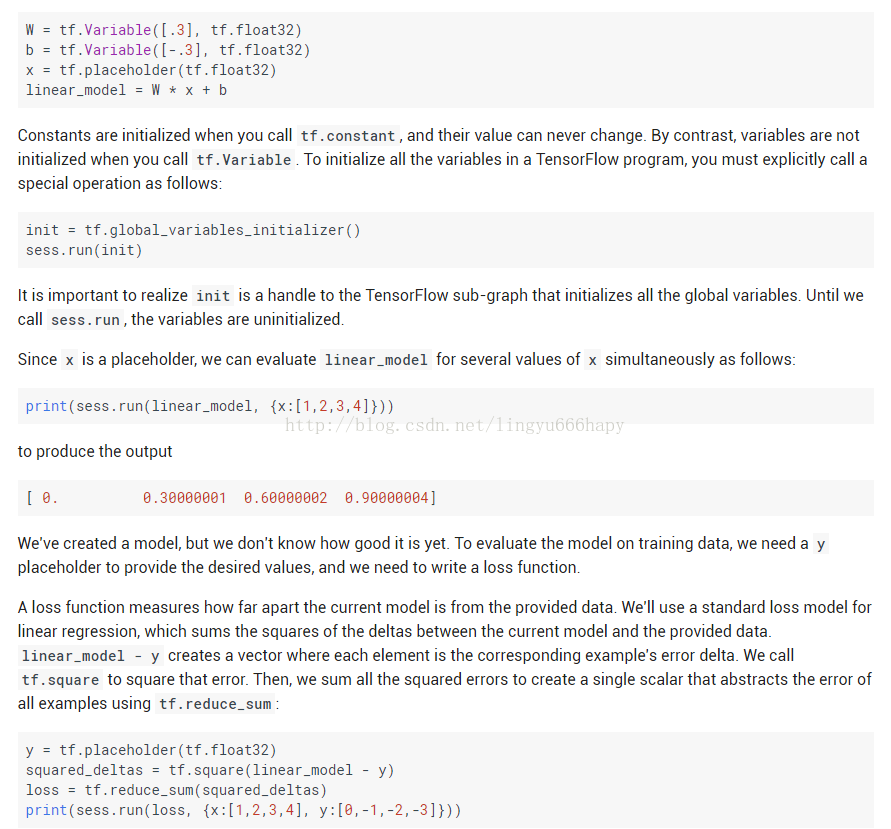
这里面就有了机器学习的影子了,里面包含了输入变量X,参数w和b,输出y,损失函数loss,基本元素基本上都包含了。那么y也是placeholder,所以placeholder应当包含了输入输出接口了,具体怎么翻译呢?有地方翻译为占位符,也挺好的。
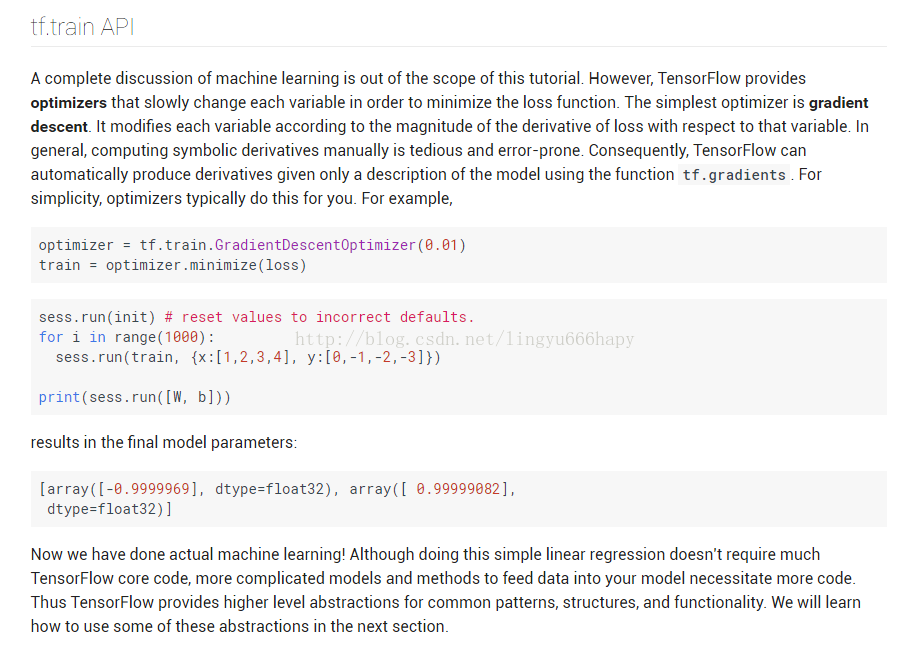
这是如何训练一个模型,这里是最小化损失函数,总共训练了1000次,最后得到了我们要的参数w和b。

最终的损失函数数值为e-11.效果很好,主要是该模型就是一个非常完美的线性模型,毫无疑问了。
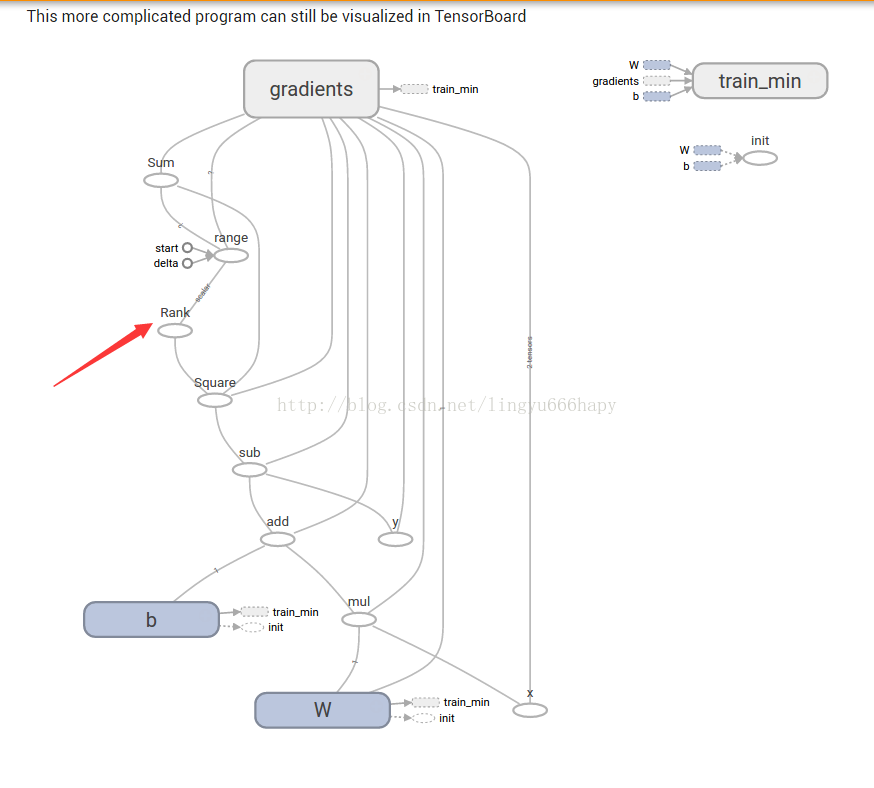
该训练网络为上图,rank之上我就看不懂了,还有就是每一个模块似乎都跟gradient模块相连,有点萌。但是计算梯度的时候,这些数值都是需要的,应该是这个原因了。

contrib属性学习,是属于高层的抽象,看一下如何应用
import tensorflow as tf
# NumPy is often used to load, manipulate and preprocess data.
import numpy as np
# Declare list of features. We only have one real-valued feature. There are many
# other types of columns that are more complicated and useful.
features = [tf.contrib.layers.real_valued_column("x", dimension=1)]
# An estimator is the front end to invoke training (fitting) and evaluation
# (inference). There are many predefined types like linear regression,
# logistic regression, linear classification, logistic classification, and
# many neural network classifiers and regressors. The following code
# provides an estimator that does linear regression.
estimator = tf.contrib.learn.LinearRegressor(feature_columns=features)
# TensorFlow provides many helper methods to read and set up data sets.
# Here we use `numpy_input_fn`. We have to tell the function how many batches
# of data (num_epochs) we want and how big each batch should be.
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x}, y, batch_size=4,
num_epochs=1000)
# We can invoke 1000 training steps by invoking the `fit` method and passing the
# training data set.
estimator.fit(input_fn=input_fn, steps=1000)
# Here we evaluate how well our model did. In a real example, we would want
# to use a separate validation and testing data set to avoid overfitting.
estimator.evaluate(input_fn=input_fn)features = [tf.contrib.layers.real_valued_column("x", dimension=1)]输入为一维xestimator = tf.contrib.learn.LinearRegressor(feature_columns=features)线性模型输入输出x = np.array([1., 2., 3., 4.]) y = np.array([0., -1., -2., -3.]) input_fn = tf.contrib.learn.io.numpy_input_fn({"x":x}, y, batch_size=4, num_epochs=1000)batch_size,机器学习中非常有用的概念,当样本数量非常大,有一些冗余的时候,采用minibatch训练,效果会非常好。当然这里就4个样本,就是full——batchnum_epochs是每个batch的大小,为什么是1000呢,有点晕estimator.fit(input_fn=input_fn, steps=1000)这里面有两个input_fn,当然了,第一个是默认变量,看一下其源码:
这样是不是就一目了然了,哈哈,1000次训练estimator.evaluate(input_fn=input_fn)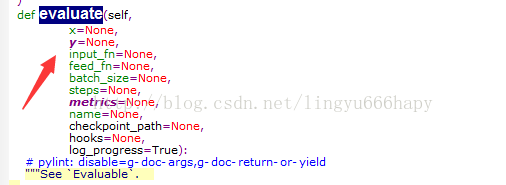
具体各个参数什么意思,慢慢学习了,先有个总体的印象,学习,就是要一遍一遍不断的看,不断的学习。这个例子到此先暂时放一下了。把这个例子写入文件,然后python一下就可以看到结果了,这里不多叙述。import numpy as np
import tensorflow as tf
# Declare list of features, we only have one real-valued feature
def model(features, labels, mode):
# Build a linear model and predict values
W = tf.get_variable("W", [1], dtype=tf.float64)
b = tf.get_variable("b", [1], dtype=tf.float64)
y = W*features['x'] + b
# Loss sub-graph
loss = tf.reduce_sum(tf.square(y - labels))
# Training sub-graph
global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = tf.group(optimizer.minimize(loss),
tf.assign_add(global_step, 1))
# ModelFnOps connects subgraphs we built to the
# appropriate functionality.
return tf.contrib.learn.ModelFnOps(
mode=mode, predictions=y,
loss=loss,
train_op=train)
estimator = tf.contrib.learn.Estimator(model_fn=model)
# define our data set
x = np.array([1., 2., 3., 4.])
y = np.array([0., -1., -2., -3.])
input_fn = tf.contrib.learn.io.numpy_input_fn({"x": x}, y, 4, num_epochs=1000)
# train
estimator.fit(input_fn=input_fn, steps=1000)
# evaluate our model
print(estimator.evaluate(input_fn=input_fn, steps=10))到此,第一个感觉已经建立了。














 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









