






在线调试 Lua 代码
一直有人问,如果调试 skynet 构件的服务。
我的简单答案是,仔细 review 代码,加 log 输出。长一点的答案是,尽量熟悉 skynet 的构造,充分利用预留的监控接口,自己编写工具辅助调试。
之前的好多年,我也写过很多 lua 的调试器,这里就不一一翻旧帖了。今天要说的是,我最终还是计划加入 1.0 正式版的调试控制台。
也就是单步跟踪调试单个 lua coroutine 的能力。这对许多新手来说是个学走路的拐杖,虽然有人一辈子都扔不掉。

一直有人问,如果调试 skynet 构件的服务。
我的简单答案是,仔细 review 代码,加 log 输出。长一点的答案是,尽量熟悉 skynet 的构造,充分利用预留的监控接口,自己编写工具辅助调试。
之前的好多年,我也写过很多 lua 的调试器,这里就不一一翻旧帖了。今天要说的是,我最终还是计划加入 1.0 正式版的调试控制台。
也就是单步跟踪调试单个 lua coroutine 的能力。这对许多新手来说是个学走路的拐杖,虽然有人一辈子都扔不掉。
最近想给 skynet 加一个在线调试器,方便调试 Lua 编写的服务。
Lua 本身没有提供现成的调试器,但有功能完备的 debug api 。通常、我们可以在代码中插入 debug.debug() 就可以进入一个交互环境,输入任何 Lua 指令。当然,你也可以在 debug hook 里调用它。
但这种交互方式有一个缺点:lua 直接用 load 翻译输入的文本,转译为一个 lua 函数并运行。这注定了这个输入的代码中不能直接访问到上下文的局部变量和 upvalue 。
如果想读写上下文中的局部变量或 upvalue ,还得使用 debug.getlocal 等函数。这无疑是相当麻烦的。
最近在慢慢把公司的几个项目从 Lua 5.2 迁移到 Lua 5.3 ,为发布 skynet 1.0 alpha 版做准备。
在更新代码时发现了一些注意点,罗列一下:
Lua 5.3 去掉了关于 unsigned 等的 api ,现在全部用 lua_Integer 类型了。这些只需要换掉 api ,加上强制转换即可。通常不会有什么问题。
最需要细致 review 代码升级的是和序列化相关的库。在 skynet 里是序列化库、sproto、bson 等。我们还用到了 protobuffer ,也和序列化有关。
这是因为,Lua 5.3 提供了整型支持,而序列化工作通常需要区分浮点和整数分开处理。json 这种文本方式则不需要,同样还有 redis 的通讯协议也是如此。
过去判断一个 number 是浮点还是整数,需要用 lua_tonumber 与 lua_tointeger 各取一份做比较。虽然到了 Lua 5.3 这种代码理论上可以不用改动,但正确的方法应该是使用 lua_isinteger 。
skynet 提供了一个 lua 库 netpack ,用来把 tcp 流中的数据解析成 长度 + 内容的包。虽然使用 skynet 的同学可以不使用它,而自己另外实现一套解析协议来解析外部 TCP 数据流(比如 skynet 中的 redis driver 解析 redis server 的数据流就是用的换行符分割包),但依然有很多同学询问,能不能自定义包头长度。
这里的这个库定义的协议中,包长度是用 big-endian 的 2 个字节表示的,也就是说一个包的长度不得超过 64K 。这让很多人很为难。已经几次有同学建议,把长度放宽成 4 个字节,因为他们的应用环境中大部分包不会超过 64K ,但总有少量超过这个限制的。
在 2015 年的新年里,Lua 5.3 发布了 rc3 版。
如果回顾 Lua 5.2 的发布历史,Lua 5.2 的 final 版是在 rc8 之后的 2011 年 12 月 17 日发布的,距离 rc1 的发布日 2011 年 11 月 24 日过去不到 1 个月。我们有理由相信正式版不远了。( 5.3 的 rc1 是 2014 年 12 月 17 日发布的)
这次升级对 Lua 语言层面的影响非常的小,但新增加的 int64 支持,以及 string pack 、utf8 库对开发帮助很大。所以我强烈建议正在使用 Lua 5.2 的项目尽快升级到 5.3 。相对而言,当初 5.1 向 5.2 升级的时候就痛苦的多(去掉了 setfenv ,增加了 _ENV)。
我计划在 Lua 5.3 正式发布后,将 skynet 内置的 Lua 版本升级到 5.3 ,然后着手进行 skynet 1.0 的发布工作。
昨天(2014 年 12 月 13 日),忙了一天,终于把说道半年的心事了了。skynet 社区的第一次线下聚会。
一直在 qq 群里说想搞一次线下聚会,让使用 skynet 的同学有机会当面交流一下,忙这忙那的拖到年底。直到又人有重提,择日不如撞日,就选在了本周六。
原来计划搞此 30 人的小聚会就好了,可以就在办公室会议室里。结果没料到公司最近扩张太快,新办公地又暂时没有搞定,会议室都被塞满了。那么转移到楼下餐厅吧,大概可以装下 40 人。
故意没有宣传,想着不会有太多人报名。可到了最后几天,邮件列表上的报名人数超过了 60 人,赶紧去找新场地。最终昨天来了 80 多人。btw. 南京远道来的同学辛苦了。
最近晓靖给 skynet 提了一个 pr 。
提之前我们讨论了好久,据说是因为查另外一个问题时改写了 skynet 的消息调度部分发现在某些情况下可以提高 CPU 的使用率。
之前 skynet 的消息调度采用的是基于 cas 的无锁结构。但本质上,并发队列这种数据结构,无论是采用 spin-lock 还是 cas 无锁结构,为了保证时序,进队列或出队列的部分都必须是依次进行的,也就是说,多核心无助于提高队列的性能。
使用无锁结构,无非是对发生冲突保有乐观态度,觉得大多数情况下冲突不会发生,一旦发生就采取重来一次的策略。
而使用 spin lock ,则是对冲突采取悲观策略,认为冲突经常发生,所以在操作共享字段时,锁住资源独享操作。
最终,都必须等前一件事情做完,才能接着做下一件事。
考虑了很久, 最终还是给 skynet 加上了基本的 UDP 支持. 虽然大多数情况下, 我不赞成使用 UDP 协议. 尤其是在网络游戏领域. 但考虑到 skynet 已经不仅仅应用于游戏领域, 我想, 加入有限的 UDP 支持是有意义的.
btw, 根据最近的反馈看,有人把 skynet 用于交换机(由于使用的是 powerpc 的 CPU ,帮助解决了一些大小端 bug );有应用于证券领域;还有做视频广播的。另外,把 skynet 用于 web 开发的应该也有人在,就简单的测试来看,性能方面不比把 lua 集成到 nginx 差。
目前,UDP 这部分代码已经完成,放在 github 里一个叫 udp 的分支上,不久以后会合并到主干上。由于我自己没有什么这方面的需求,所以还需要有 udp 需求的同学读一下代码,实际使用,这样才可能发现潜在的问题。
关于这部分的设计以及 api 文档,我补充在 wiki 上了 。
最近我们的新游戏《天天来战》上了腾讯平台,由于瞬间用户量过大,发现了几个 bug。
这几个 bug 都是在最后一周赶进度时编写业务的同学写的太仓促,在一些处理请求的流水线上使用了时间复杂度 O(n) 以上的算法导致的问题。这些时间开销大的操作,虽然并不常见,但操作误放在了和用户登录相关的服务中,导致一旦阻塞,使得用户登录受到影响。
具体 bug 没什么好谈的,把业务拆分开,以及用 O(Log N) 或 O(1) 的算法重新实现后就好了。但发生 bug 后,skynet 的整体表现值得一提。
按原有的设计,skynet 可以视为一个简单的操作系统。每个服务都是这个系统中的进程。不相关的业务应该互不干扰(使用多核的硬件,核心越多,就可以表现的越好)。在这次事件中,的确也做到了受影响的部分(登录)处理能力不足,用户无法正常操作时;另一些做无关操作(副本游戏)的用户没有收到影响。但在服务过载后的恢复环节却做的不够。
由于 bug 的影响,有类消息的处理能力只有 20 次/s 左右。当需要处理的消息频率超过 20 次后(在线玩家超过 8000 人以后出现),该服务过载,导致整个系统处于半瘫痪状态。新用户无法正常进入,直到在线人数下降到 4000 人都没有好转。但已在玩游戏的用户没有受到影响,所以没有做任何处理。大约在 2 个多小时后,系统自己维护正常。这比预期时间要长得多。
这是上周遇到的问题。昨天又在新一轮导量中出现了类似的问题。由于配置问题把大量玩家(十万数量级)引到同一组服务器,导致该服务器几乎无法创建新角色,同时老玩家登录也无法获取自己的角色(因为和创建角色在同一服务内)。如果玩家有足够耐心,等待 10 分钟,还是可以正常进入游戏。这个状态在分流新用户后,得到了缓解。但服务器依然用了小时级的时间才自我恢复。经事后排查,同样是一处 bug 导致的性能问题,但自我恢复时间过长也值得关注。
sproto 基本算完成了, 等 lua 5.3 正式发布后, 还需要把 64bit 整数支持一下。我给 sproto 加了 lua 封装,以方便更好的支持 rpc 。
子熏同学完成了 sproto 的 jit 版本。但似乎性能提升不是很明显。
我希望可以在 skynet 的下个大版本,把 sproto 作为推荐 C/S 通讯协议加进去。
目前正在开发的 skynet 新特性是可以把单个服务的外来消息全部 log 在一个文件中。目前支持了 skynet 的普通消息以及 socket 消息。如果有必要,还可以把组播消息加上。
目前这个特性主要用来调试。其实可以为之开发配套的工具,比如另外做一个调试工具,能够把所以记录的消息重放给一个特定的服务脚本,便可重现一个服务的工作历史。目前 log 文件中记录的消息时间和消息内容足以重现。只要消息中不包含内存地址,这种录像重播的测试方法应该是有效的。
不过暂时还没碰到需要这种调试(比如一个服务出现异常,可以利用录像回溯之前发生的事情,以及当时的现场),等需要时再根据需要制作这样的工具。
等 lua 5.3 正式发布后,打算把 pbc 跟进一下。skynet 里的 int64 支持也可以用 lua 5.3 官方特性取代。我相信到那个时候就可以发布 skynet 的 1.0 版了。
ejoy2d 这个项目,公司有许多同事有兴趣做进一步贡献。所以我把主仓库迁移到 ejoy 名下。
由于正在用 ejoy2d 开发的两个新项目比较紧,最近 ejoy2d 里增加了不少临时项目用的接口。暂时还没有精力去规整。许多新特性(比如粒子绑定,对资源异步加载的支持)都没能及时加上文档。
目前实测在 iphone4 上 ejoy2d 可能会有性能问题。为此,增加了一个 renderbuffer 的特性,可以把一批渲染的定点输出到固定的顶点 buffer 中,这对用复杂图素拼装起来的静态背景会有一些效果。不过关键还在于 iphone4 的 GPU 性能太差,稍微复杂一点的 fragment shader 就会很勉强,为次可能需要给 ejoy2d 加入更灵活的 shader 定制特性。
经过几天的努力,终于把我们新项目在 iphone4 上的 fps 从 12 提升到了 18 ,勉强可以接受了吧。离目标 30fps 还有一些距离,如果进一步的细调还是可以达到的,但会增加很多制作上的难度。不知道到明年,还是否需要考虑 iphone4 这个档次的硬件。
btw, 乘 steam 打折,周末玩了一天文明 V 的第二扩展,还是很不错的。非常期待年底的 beyond earth 。
STM 全称 Software transactional memory 。
在前年的项目里,我制作了一个类似的东西。随着 skynet 的日趋完善,我希望找到一个更为简单易用的方法实现类似的需求。
对于不常更新的数据,我在 skynet 里增加了 sharedata 模块,用于配置数据的共享。每次更新数据,就将全部数据打包成一个只读的树结构,允许多个 lua vm 共享读。改写的时候,重新生成一份,并将老数据设置脏标记,指示读取者去获取新版本。
这个方案有两个缺点,不适合实时的数据更新。其一,更新成本过大;其二,新版本的通告有较长时间的延迟。
我希望再设计一套方案解决这个实时性问题,可以用于频繁的数据交换。(注:在 mmorpg 中,很可能被用于同一地图上的多个对象间的数据交换)
一开始的想法是做一个支持事务的树结构。对于写方,每次对树的修改都同时修改本地的 lua table 以及被修改 patch 累计到一个尽量紧凑的序列化串中。一个事务结束时,调用 commit 将快速 merge patch 。并将整个序列化串共享出去。相当于快速做一个快照。
读取者,每次读取时则对最新版的快照增加一次引用,并要需反序列化它的一部分,变成本地的 lua table 。
我花了一整天实现这个想法,在写了几百行代码后,意识到设计过于复杂了。因为,对于最终在 lua 中操作的数据,实现一个复杂的数据结构,并提供复杂的 C 接口去操作它性能上不会太划算。更好的方法是把数据分成小片断(树的一个分支),按需通过序列化和反序列化做数据交换。
既然序列化过程是必须的,我们就不需要关注数据结构的问题。STM 需要管理的只是序列化后的消息的版本而已。这一部分(尤其是每个版本的生命期管理)虽然也不太容易做对,但结构简单的多。
skynet 中可以独立的业务都是以独立服务形式存在的。昨天和同事讨论如何实现一个邮件通知服务。
目前大概是这样的:有一个独立的邮件中心服务,它可以处理三条协议:
用户读了多少邮件没有放在邮件中心,而是记在玩家数据里的。
用户的界面上需要显示是否有几封未读邮件,如果有新邮件达到,这个数字会自动变更。你可以想像成 iOS 上的那种带数字的小红点。
当然,在 skynet 的设计惯例中,每个用户在服务器上有一个 agent 代理,所以我们不单独考虑和客户端数据交互的问题,而只用考虑 agent 如何和邮件中心的交互。
现在的做法是,在用户上线的时候,就去邮件中心查一次,比较邮件数量后知道是否有新邮件,然后推送给玩家。
在玩家特定的操作后,比如进出副本等,都会重新查询一次。如果玩家在一个场景停留太久,客户端也会定期发起查询请求。
如果邮件必须在新邮件达到时,立刻通知给玩家怎么办呢?那么系统中另外有个用户中心的服务。邮件服务可以把消息推送到那里;用户中心发现玩家不在线,就扔掉消息;如果在线就做消息推送。
我觉得这个方案有那么一点点不好,所以提出了我的想法。
一直没给 skynet 加 http 协议解析模块是因为这个领域我不熟悉,而懂这块(web 开发)的人很多,随便找个人做都应该比我做的好。世界上的 web 服务器实在是太多了,足见做一个的门槛也不高,我也没什么需求,所以就这样等着有需要的人来补上这一块。
但这两天实在等不了了。我们即将上线的一款游戏,运营方要求我们提供一组 web api 供运营使用。固然我们可以单独写一个进程挂在 nginx 的后面,并和 skynet 通讯,但游戏开发组的同学觉得不必把简单的事情做的这么绕。监听一个端口提供 http 协议的服务又不是什么特别麻烦的事情,结果就打算直接在 skynet 里提供。
周末终于把上周提到的 短连接服务 实现了。由于本质上是一个消息请求回应模式的服务器,并没有局限于长连接还是短连接,所以不打算用短连接服务来命名。
用户的登陆状态不再依赖于是否有连接保持,所以登陆服务也顺理成章的分离出来了。
用户先去统一的登陆服务器登陆,获得令牌,然后去游戏服务器连接握手。如果用户和游戏服务器的连接断开,只需要重新用令牌握手即可,不必重新回登陆服务器登陆。
当然用户也可以重新登陆,清除登陆状态,完成一个传统意义上的下线再上线的过程。
不基于一个稳定 TCP 连接的做法,在 web game 中很常见。这种做法多基于 http 协议、以适合在浏览器中应用。
运行在移动网络上的游戏,网络条件比传统网络游戏差的多。玩家更可能在游戏进行中突然连接断开而导致非自愿的登出游戏。前段时间,我实现了一个库来帮助缓解这个问题 。
如果业务逻辑基于短连接来实现,那么也就不必这么麻烦。但是缺点也是很明显的:
每对请求回应都是独立的,所以请求的次序是不保证的。
服务器向客户端推送变得很麻烦,往往需要客户端定期提起请求。
安全更难保证,往往需要用一个 session 串来鉴别身份,如果信道不加密,很容易被窃取。
即使有这些缺点,这种模式也被广泛使用。我打算在下个版本的 skynet 中提供一些支持。
所谓支持、想解决的核心问题其实是上述的第三点:身份验证问题;同时希望把复杂的登陆认证,以及在线状态管理模块可以更干净的实现出来。
我不打算基于 HTTP 协议来做,因为有专有客户端时,不必再使用浏览器协议。出于性能考虑,建立了一个 TCP 连接后,也可以在上面发送多个请求。仅在连接状态不健康时,才建议新建一个 TCP 连接。
skynet 是可以启动多个节点,不同节点内的服务地址是相互唯一的。服务地址是一个 32bit 整数,同一进程内的地址的高 8bit 相同。这 8bit 区分了一个服务处于那个节点。
每个节点中有一个特殊的服务叫做 harbor (港口) ,当一个消息的目的地址的高 8 位和本节点不同时,消息被投递到 harbor 服务中,它再通过 tcp 连接传输到目的节点的 harbor 服务中。
不同的 skynet 节点的 harbor 间是如何建立起网络的呢?这依赖一个叫做 master 的服务。这个 master 服务可以单独为一个进程,也可以附属在某一个 skynet 节点内部(默认配置)。
master 会监听一个端口(在 config 里配置为 standalone 项),每个 skynet 节点都会根据 config 中的 master 项去连接 master 。master 再安排不同的 harbor 服务间相互建立连接。
最终一个有 5 个节点的 skynet 网络大致是这样的:
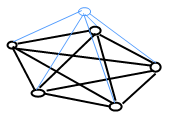
上面蓝色的是 master 服务,下面 5 个 harbor 服务间是互连的。master 又和所有的 harbor 相连。
这就是早期的 skynet 分布式集群方案。有一篇 2 年前的 blog 记录了当时的想法,可以一窥历史。
由于历史变迁,从早期的手脚架不全,到如今的 skynet 的基础设置日臻完善。这部分代码也改写过很多次,每每想做大的改动,都不敢过于激进。
最近,我们的一个新项目要上线,由于运营方只能提供虚拟机,且网络状态不是很好,暴露了 skynet 在启动组网阶段的一些时序漏洞。所以这个周末我咬牙把这块东西全部重新设计实现了。
目前联系了广州一家制衣厂做一些 skynet 的主题 T 恤。由于定的量很少,所以价格不算便宜(但材料选用的那家厂最好的)。
有同学帮忙开了家 taobao 店用于收款(不是我开的),想要的人自己下单。凑够 100 件就开工。如果做不成就退款。
上周 release 了 skynet 的 0.3 版,其最重要的新特性就是给出了一套新的集群方案。
在过去,skynet 的集群限制在 255 个节点,为每个服务的地址留出了 8bit 做节点号。消息传递根据节点号,通过节点间互联的 tcp 连接,被推送到那个 skynet 节点的 harbor 服务上,再进一步投递。
这个方案可以隐藏两个 skynet 服务的位置,无论是在同一进程内还是分属不同机器上,都可以用唯一地址投递消息。但其实现比较简单,没有去考虑节点间的连接不稳定的情况。通常仅用于单台物理机承载能力不够,希望用多台硬件扩展处理能力的情况。这些机器也最好部署在同一台交换机下。
之前这个方案弹性不够。如果一台机器挂掉,使用相同的节点 id 重新接入 skynet 的后果的不可预知的。因为之前在线的服务很难知道一个节点下的旧地址全部失效,新启动的进程的内部状态已经不可能和之前相同。
所以,我用更上层的 skynet api 重新实现了一套更具弹性的集群方案。


折腾了几天,终于把 skynet 的 logo 设计好了。
按原计划, 我今天给 skynet 的 github 仓库 打上了 v0.2.0 的 tag 。
这个版本增加的主要特性是组播 。其它都是对已有代码的整理。
虽然 skynet 只有不到三年的历史,但已经有不少历史包袱了。最早的 skynet 是用 erlang 实现的,在 erlang 中编写了一个 C driver 然后在里面嵌入 lua 虚拟机。设计 skynet 的 C 接口时,也没有经过实际项目的使用,有许多设计不当的地方。
有一些后来觉得不应该放在核心层的东西被实现在了核心内,一些本应该在底层提供的设施被放在了很高层实现。
还有一些小特性几乎没有被使用过,但却增加了整体实现的复杂度。
调整这些历史造成的设计需要一点点来,v0.2.0 向前迈了一步。
最近接连有几位同学询问 skynet 的消息队列算法中为什么引入了一个独立的 flags bool 数组的问题。时间久远,我自己差点都忘记设计初衷了。今天在代码里加了点注释,防止以后忘记。
其实当时我就写过一篇 blog 记录过,这篇 blog 下面的评论中也有许多讨论。今天把里面一些细节再展开说一次:
我用了一个循环队列来保存 skynet 的二级消息队列,代码是这样的:
#define GP(p) ((p) % MAX_GLOBAL_MQ)
static void
skynet_globalmq_push(struct message_queue * queue) {
struct global_queue *q= Q;
uint32_t tail = GP(__sync_fetch_and_add(&q->tail,1));
q->queue[tail] = queue;
__sync_synchronize();
q->flag[tail] = true;
}
struct message_queue *
skynet_globalmq_pop() {
struct global_queue *q = Q;
uint32_t head = q->head;
uint32_t head_ptr = GP(head);
if (head_ptr == GP(q->tail)) {
return NULL;
}
if(!q->flag[head_ptr]) {
return NULL;
}
__sync_synchronize();
struct message_queue * mq = q->queue[head_ptr];
if (!__sync_bool_compare_and_swap(&q->head, head, head+1)) {
return NULL;
}
q->flag[head_ptr] = false;
return mq;
}
最近在做 skynet 的 0.2 版。主要增加的新特性是重新设计的组播模块。
组播模块在 skynet 的开发过程中,以不同形式存在过。最终在 0.1 版发布前删除了。原因是我不希望把这个模块放在核心层中。
随着 skynet 的基础设施逐步完善,在上层提供一个组播方案变得容易的多。所以我计划在 0.2 版中重新提供这个模块。注:在 github 的仓库中,0.2 版的开发在 dev 分支中,只到 0.2 版发布才会合并到 master 分支。这部分开发中的特性的实现和 api 随时都可能改变。
距离 skynet 开源项目的公布 已经有 20 月+ 了,如果从闭源阶段算起,已经超过了 30 个月。在我们公司内部有五个项目使用 skynet 开发,据有限的了解,在我们公司之外,至少有两个正式项目使用了相当长的时间。是时候发布一个正式版了。
今天 skynet 的第一个正式版本 v0.1.0 发布了。
在发布之前,我花了几天时间帮助公司内部的项目合并代码。最后全部统一使用这个版本。而在此之前,每个项目都是由一个负责人 fork 出一份,根据项目需要自己修改。merge 工作总是做的痛苦不堪。
通过这次发布,希望未来可以统一维护基础框架部分。
skynet 目前的 api 提供的偏底层,由于一些历史原因,某些 api 的设计也比较奇怪。(比如 skynet.ret 是不对返回数据打包的)
我想针对一些最常见的应用环境重新给出一套更简单的 api ,如果按固定模式来编写 skynet 的内部服务会简单的多。
这就是这两天实现的 snax 模块。今天我已经将其提交到 github 的 snax 分支上,如果没有明显的问题,将合并入主干。
snax 仅解决一个简单的需求:编写一个 skynet 内部服务,处理发送给它的消息。snax 并不会取代 skynet 原有的 api ,只是方便实现这类简单需求而已。
由于历史原因,skynet 中的 gate 服务最早是用 C 写的独立服务。后来 skynet 将 socket 的管理模块加入核心后又经历过一次重构,用后来增加的 socket api 重新编写了一遍。
目前,skynet 的各个基础设施逐步完善,并确定了以 lua 开发为主的基调,所以是时候用 lua 重写这个服务了。
如果是少量的连接且不关心性能的话,直接用 skynet 的 lua socket 库即可。这里有一个例子 。
gate 定位于高效管理大量的外部 tcp 长连接。它不是 skynet 的核心组件,但对于网络游戏业务,必不可少。
在 skynet 这种应用中,同一个系统进程里很轻易的就会创建数千个 lua 虚拟机。lua 虚拟机本身的开销很小,在不加载任何库(包括基础库)时,仅几百字节。但是,实际应用时,还需要加载各种库。
在 lua 虚拟机中加载 C 语言编写的库,同一进程中只会存在一份 C 函数原型。但 lua 编写的库则需要在每个虚拟机中创建一份拷贝。当有几千个虚拟机运行着同一份脚本时,这个浪费是巨大的。
我们知道,lua 里的 function 是 first-class 类型的。lua 把函数称为 closure ,它其实是函数原型 proto 和绑定在上面的 upvalue 的复合体。对于 Lua 实现的函数,即使没有绑定 upvalue ,我们在语言层面看到的 function 依然是一个 closure ,只不过其 upvalue 数量为 0 罢了。
btw, 用 C 编写的 function 不同:不绑定 upvalue 的 C function 被称为 light C function ,可视为只有原型的函数。
如果函数的实现是一致的,那么函数原型就也是一致的。无论你的进程中开启了多少个 lua 虚拟机,它们只要跑着一样的代码,那么用到的函数原型也应该是一样的。只不过用 C 编写的函数原型可以在进程的代码段只存在一份,而 Lua 编写的函数原型由于种种原因必须逐个复制到独立的虚拟机数据空间中。
大部分外部网络服务都是请求回应模式的,skynet 和外部数据库对接的时候,直接用 socket api 编写 driver 往往很繁琐。需要解决读取异步回应的问题,还需要正确处理连接断开后重连的问题。
这个周末,我试着给 skynet 的 socket 模块加了一个叫做 channel 的模式,用来简化这类问题的处理。
可以用 socket.channel { host = hostname, port = port_number } 创建出一个对象。这个对象用来和外部服务器通讯。
注:陌陌争霸的数据库部分我没有参与具体设计,只是参与了一些讨论和提出一些意见。在出现问题的时候,也都是由肥龙、晓靖、Aply 同学判断研究解决的。所以我对 Redis 的判断大多也从他们的讨论中听来,加上自己的一些猜测,并没有去仔细阅读 Redis 文档和阅读 Redis 代码。虽然我们最终都解决了问题,但本文中说描述的技术细节还是很有可能与事实相悖,请阅读的同学自行甄别。
在陌陌争霸之前,我们并没有大规模使用过 Redis 。只是直觉上感觉 Redis 很适合我们的架构:我们这个游戏不依赖数据库帮我们处理任何数据,总的数据量虽然较大,但增长速度有限。由于单台服务机处理能力有限,而游戏又不能分服,玩家在任何时间地点登陆,都只会看到一个世界。所以我们需要有一个数据中心独立于游戏系统。而这个数据中心只负责数据中转和数据落地就可以了。Redis 看起来就是最佳选择,游戏系统对它只有按玩家 ID 索引出玩家的数据这一个需求。
我们将数据中心分为 32 个库,按玩家 ID 分开。不同的玩家之间数据是完全独立的。在设计时,我坚决反对了从一个单点访问数据中心的做法,坚持每个游戏服务器节点都要多每个数据仓库直接连接。因为在这里制造一个单点毫无必要。
根据我们事前对游戏数据量的估算,前期我们只需要把 32 个数据仓库部署到 4 台物理机上即可,每台机器上启动 8 个 Redis 进程。一开始我们使用 64G 内存的机器,后来增加到了 96G 内存。实测每个 Redis 服务会占到 4~5 G 内存,看起来是绰绰有余的。
由于我们仅仅是从文档上了解的 Redis 数据落地机制,不清楚会踏上什么坑,为了保险起见,还配备了 4 台物理机做为从机,对主机进行数据同步备份。
Redis 支持两种 BGSAVE 的策略,一种是快照方式,在发起落地指令时,fork 出一个进程把整个内存 dump 到硬盘上;另一种唤作 AOF 方式,把所有对数据库的写操作记录下来。我们的游戏不适合用 AOF 方式,因为我们的写入操作实在的太频繁了,且数据量巨大。
前两天一直困扰我的问题是并发启动 lua state 比串行启动它们要慢的多。而启动 lua state 的操作相互是完全无关的,没有任何应用层的锁。原本我以为多核同时做这些事情,即使不比单核快,也不至于慢一倍吧?
昨天有同学在 google talk 上和我讨论这个问题,说要不要考虑下是内存资源方面的问题。比如,在大量线程同时申请并读写大量内存时,有可能引起操作系统在映射物理内存到虚拟地址空间这个操作上出现性能问题。
虽然最后确认不是这个原因,但这启发我可能内存分配器在多核上工作并不顺畅。
我们使用 skynet 的项目利用 jemalloc 替换了默认 glibc 的分配器。tcmalloc 也应该是一个好的选择。但无论是哪个,都有多线程锁的问题。而 lua 可以自定义内存管理器,我们在 lua 服务启动时,若预分配 1M 内存,那么在这 1M 内存内的内存管理就完全没有线程安全的顾虑了,理论上这种定制的内存管理器会比一切通用管理器表现更好。
昨天我花了 3 个小时实现了一个简单的 lua 内存管理器,提交到 github 上。默认是关闭的,有兴趣使用的同学可以在 service_lua.c 里把
#define PREALLOCMEM (1024 * 1024)
的注释去掉。这样就可以启用为 skynet 专配的 lua 内存分配器了。
我们开发 6 个月的手游即将上线,渠道要求我们首日可以承受 20 万同时在线,100 万活跃用户的规模。这是一个不小的挑战,我们最近在对服务器做压力测试。
我们的服务器基于 skynet 构架,之前并没有实际跑过这么大用户量的应用,在压力测试时许多之前理论预测的问题都出现了,也发现了一些此前没有推测到的现象。
首先,第一个性能瓶颈出现在数以万计的机器人同时登陆系统的时候。这是我们预测到的,之前有为此写过一篇 blog 。
为了解决这个拥塞问题,我的建议是用这样一个系列的方案:
用户认证不要接入 agent 服务。即,不要因为每个新连接接入都启动一个新的 agent 为它做认证过程。而应该统一在 watchdog 分发认证请求。当然这样就不可以用 skynet 默认提供的 watchdog 了。skynet 的源代码库中之所以实现了一份简单的 watchdog ,更多的是一个简单的示范。我们自己开发的两个项目都自己定制了它。
认证的具体业务逻辑(例如需要接入数据库等),实现在一个独立的服务中,做成无状态服务,可以任意启动多份。由 watchdog 用简单的均匀负载的方式来使用。如有需要,再实现一套排队流程(参考 1, 参考 2 ),也由 watchdog 调度。
我们目前这个项目的设计是唯一大服,所有用户在一个服务器中,要求承担百万级用户同时在线。所以我们在每台物理机上都配备了一个 watchdog ,通过内部消息在中心服务器统一协调。如果不这样设计,watchdog 会实现的更简单。watchdog 只负责维护用户在线状态,没有具体的计算压力,所以很难成为性能热点。
当用户认证成功后,watchdog 启动一份 agent ,通知 gate (连接网关) 把用户连接重定向到 agent 上。后续用户的业务逻辑,都有一对一的 agent 为它服务。
基于 Actor 模式的框架,比较难解决的问题是当一个 actor 异常退出后如何善后的问题。
Erlang 的做法简单粗暴,它提供了 spawn_link 方法 , 当一个 process (Erlang 的 Actor) 退出后,可以把和它关联的 process 也同时退出。
在 skynet 中,一开始我并不想在底层解决这个问题。我希望所有的 service 都是稳定的。如果一个 service 可能中途退出,那么在上层协调好这个关系。
而且 skynet 借助 lua 的 coroutine 机制,事实上在同一个 lua service 里跑着多个 actor 。一个 lua coroutine 才是一个 actor 。粗暴的将几个 service 在底层绑定生命期不太合适。
但是,如果有 service 有中途退出的可能,那么利用 skynet.call 调用上面的远程方法就变得不可靠。简单的用 timeout 来解决我认为只是回避了问题,而且会带来更多的复杂性。这是我在设计 skynet 时就想避免的。所以我在处理 service 生命期监控的问题上,做的比较谨慎。
最近为 skynet 修复了一个 bug ,Issue #51 。经查,是由于 redis driver 中的 batch 模式加锁不当造成的。
有同学建议把 batch 模式取消,由于历史原因暂时还保留。在很多其它 redis driver 的实现中也不提供类似机制。也就是依次提交多个数据库操作请求,不用等回应,最后再集中处理数据库返回的信息。
我的个人建议是在目前的 redis driver 基础上再实现一个独立服务,里面做一个连接池,让系统不同服务对数据库的读写工作在不同连接上,这样可能更好些。如果简单的实现一个数据库代理服务而不采用连接池的话,可能会面对一些意想不到的情况。
这是由 skynet 的 lua 模块工作方式决定的,下面解释一下。
有同学向我反应,自从 skynet 的 IO 库重写后,Mac OSX 上便无法启动了。
我检查了一下,直接原因是 kqueue 部分写的不对。kqueue 和 epoll 的 api 设计还是有些区别的,epoll 的 api 可以合并读写消息,但 kqueue 读是读,写是写。当时随手写好后一直没有在真实环境下测试,所以一直是有问题的,只是这次另外一个问题将它暴露了。
我新写的 IO 库是异步操作的。异步处理针对任何 IO 请求,其中也包括了建立连接以及监听连接。skynet 启动的时候需要启动一个 master 服务,然后再各个分布节点上启动 harbor 服务通过 master 互联。这些连接是通过 IO 模块的 socket connect 建立的。
我希望在 skynet 启动完成前把这些连接(至少是主节点的)都正确建立起来。
Skynet (关于 skynet 的更多 blog 见右侧导航条上的 skynet tag) 的设计受我在 2006 年做过的一个卡牌游戏服务器影响很重,后来又受到 2008~2011 年期间 Erlang 的影响。多年的经验也让我背上许多思想包袱,以前觉得理所当然的东西,后来没来得及细想就加入了 skynet 里面。
最近项目稳定下来,并且开始了第一个手游项目,虽然带点试验性质,毕竟也是第 2 个我们自己正式使用 skynet 的项目了。做第 2 个服务器项目的晓靖同学对 skynet 提出了不少想法和疑问,让我重新考虑了以前的设计。最近花了一个月时间重写了大量的代码,为下一步重构底层设计做好准备。
在一个稍有历史的活着的项目上做改造是不容易的,时刻需要考虑向前兼容的问题,又不想因为历史包袱而放弃改良的机会,我只能尽力而为了。
最初我认为 skynet 是为分布式运算设计的,没有用 erlang 的主要原因是因为我们有大量的业务逻辑需要(习惯)用命令式语言编写。所以最早的 skynet 版本是基于 erlang 的,并把 lua 嵌入了 erlang 。或许只是我们的实现不太好,总之结果性能表现很糟糕。放弃直接用 erlang 编写业务逻辑,而是透过 C driver 到 lua 中去解析消息请求回应加大了中间层的负担。慢慢的我发现,erlang 带给我们的好处远不如坏处多。
除了性能,我们的代码充满了不同语言不同风格:有用 erlang 实现的,有用 lua 的,还有用 C 的。为了跨语言,又不得不定义了统一的消息格式(使用 google protobuffer)。这些加起来变得厚重很难维护。
最终我决定用 C 重写底层的代码,并重新考虑 skynet 底层模块的设计定位。
Skynet 在最开始设计的时候是没有仔细考虑系统退出的问题的,后来为了检测内存泄露的问题,加入了一个 ABORT 指令可以杀掉全部活着的服务。
安全的退出整个系统,尤其是一个分布式系统,总是一个复杂的问题。我们的内部版为这些做了大量的工作。但我觉得做的不太干净,所以一直没有把代码合并到开源版。
今天晓靖又重提这个退出系统的方案,就又把这个问题拿出来讨论了一下。我的个人观点是,如何安全的退出和业务逻辑相关性很强,在框架中加入大量的通知机制让每个服务自己协调解决即增加了框架的复杂度,又不降低系统的设计难度。我们目前内部版本中增加的服务退出消息以及服务优先级等等这些机构过于复杂,且没有很好的解决问题。
曾经我想过按操作系统的做法,杀掉一个服务先发送一个消息给这个服务,让服务有一小段时间可以做最好的事务处理。等超时后,就强行把服务杀掉。这样显得不够安全,但若等服务自行干净退出又有可能发生死锁。我觉得,对于整个系统都是自己设计构建的话,其实设计人员是能够理解如何安全的关闭系统的。只有小部分服务需要做善后工作,比如数据库读写层需要把尚未写完的数据写入数据库后才能退出;大部分服务是无状态的,它们可以直接清理;还有一部分服务的关闭过程比较复杂,比如网关,就需要先关闭监听端口,再逐个关闭客户链接,最后才能退出自己。
让每个服务自己收到退出消息后想办法处理好退出流程,不如有一个专门掌管系统关闭的服务来统一协调系统关闭退出的流程。目前的 launcher 服务掌管了大部分服务的启动流程,可以稍加改进来管理退出过程。也可以把这一部分业务独立实现。无论怎样,都不要在框架底层来做太多事情。每个有复杂退出流程的服务,应在启动时把自己上报,退出管理器了解所有系统中活跃的服务,按系统的整体设计来决定退出的时候按怎样的次序做好哪些事情。
框架可以做一点点事情,能让这件事情做起来简洁一点。那就是可以指定一个服务可以监听到其它服务的关闭事件,而不需要服务在退出的时候自行汇报。
前段时间 实现了 mongo 的 lua driver ,做了一些基础工作后,由于工作比较忙就放下了。
这几天有同学告诉我他们在用这个了,并找到了一处 bug 。我还真是受宠若惊啊。一咬牙决定把这个东东整合到 skynet 中去。
本来觉得挺简单,做起来后发现必须把 lua-mongo 里的 socket 部分剥离开,才能替换成 skynet 的 socket 库 。
这个分离工作花了我一天的时间,结果虽然会损失一点性能,但是 mongo 的底层协议解析模块就可以独立出来。
和 skynet 的整合工作在做完这个步骤后,要轻松的多了。只需要把 socket 模块替换成 skynet 提供的即可。
注意:我们的项目暂时还没有使用 MongoDB ,所以我只实现了最基本的 mongo driver 的特性。需要有兴趣的同学帮我完善,或者,等我们的项目开始用 mongo 的话,总有一天我会自己把这些工作做完的。
有兴趣的同学可以直接 pull request 到 lua-mongo ,我会整合新功能,并合并到 skynet 中。
目前最希望完成的是短线自动重连, replica set ,以及 write concern 这三项特性。它们应该都可以在 lua 层完成。
这几天在 lua 和 luajit 的邮件列表上有人讨论 coroutine 的再利用问题。
前几天有个用 skynet 的同学给我写了封邮件,说他的 skynet 服务在产生了 6 万次 timeout 后,内存上升到了 50M 直到 gc 才下降。
这些让我重新考虑 skynet 的消息处理模块。skynet 对每条消息的相应都产生了一个新的 coroutine ,这样才能在消息处理流程中,可以方便的切换出去让调度器调度。诸如 RPC/ socket 读写这些 api 才能在用起来看成是同步调用,却在实现上不阻塞线程。
读源码可知,lua 的 coroutine 非常轻量(luajit 的略重)。但依旧有一些代价。频繁的动态生成 coroutine 对象也会对 gc 造成一定的负担。所以我今天花了一点时间优化了这个问题。
简单说,就是用自己写的 co_create 函数替换掉 coroutine.create 来构建 coroutine 。在原来的主函数上包裹一层。主函数运行完后,抛出一个 EXIT 消息表示主函数运行完毕。并把自己放到池中。如果池中有可利用的旧 coroutine ,则可以传入新的主函数重新利用之。
为了简化设计,如果 coroutine 中抛出异常,就废弃掉这个 coroutine 不再重复利用。为了防止 coroutine 池引用了死对象,需要在主函数运行完后,把主函数引用清空,等待替换。
具体实现参见这个 patch 。
ps. coroutine poll 故意没实现成弱表,而是在相应 debug GC 消息时再主动清空。
今天想在 skynet 下访问外部的 http 接口, 所以试了一下前几天新写的非阻塞 socket 库。
由于测试的时候用的 URL 被墙了,所以发现了问题:connect 目前是阻塞模式的。连接一个有问题的服务器可能被阻塞很久。所以花了点时间把 connect 接口改成非阻塞的了。
我以前没处理过这种情况,所以也就按书上的写法写写,异步 connect 做起来挺麻烦的。如果有用 skynet 的同学这方面经验丰富,烦请用之前帮忙 review 一下新打的 patch 。
另外,为了处理 http 的需求,给 socket 库增加了新接口 readall ,可以读 socket 上的所有数据(直到对方 close 再返回)。
socket.read 和 socket.readline 也改进了,如果对方关闭了连接,那么最后一次调用除了返回 nil 外,也把最后发送过来的数据返回。这样,readline 就可以处理最后一行没有分割符的情况了。
按计划给 Hive 增加了非阻塞的 socket 库。这样,它就可以用 lua 完成 skynet 中的 gate 以及其它 tcp 连接相关的功能了。
我比较纠结的是 listen 这个 api 的设计。传统的 bind/listen/accept 模型不太适合这样的 actor 模式。一个尝试过的方案是 skynet 中的 gate 。也就是在 listen 的端口上每收到一个新连接,就转发到新的 cell 中去。
为了灵活起见,我把转发控制交给了回调函数。这也是用 lua 的灵活之处。
用户可以选择启动新的 cell ,然后把新连接 forward 到新 cell 去,也可以 fork 一个 coroutine ,forward 回自己处理。整套 socket api 是非阻塞的,如果 IO 上没有数据,coroutine 都会被挂起。
这次 Hive 这个项目算是业余的尝试,skynet 在我们的项目中已经积累了太多相关代码,不太容易迁移到新的框架下来。而且用 lua 实现大部分以前用 C 实现的代码,性能损失未知。不过这几天写下来觉得,C 没有很好的 coroutine 支持,在做异步消息处理时非常麻烦,以至于用 C 写的模块都不能很好的提供服务的同时保持代码简洁。用 Lua 重新实现它们要简单的多。
今天收到一个朋友的邮件,他们使用 skynet 框架的游戏上线后遇到一些问题。
引用如下:
我有一个线上的 server 用了skynet框架,用了gate watchdog agent这样的结构,当人数到达1000左右的时候发现很多新 socket 连接都阻塞在了 gate 或 watchdog 这里,导致用户登录不了,后面发现是客户端那边在登录的时候做了超时判断,如果超时了就断开连接,重新连 server 执行登录过程,因为 watchdog 是在收到客户端发来的第一个消息的时候创建agent,这就导致很多 cpu 消耗在创建销毁 agent 上,而 agent 服务创建的代价比较高,这就导致watchdog效率下降。后来取消掉了客户端的那个登录超时判断,情况有所好转,但在人多的时候延迟还是存在,接着又优化了server 这边的一些逻辑代码,现在还在观察中。
中午吃饭的时候,我和我们的开发人员讨论了这个问题。为什么我们在 1000 人级别时没有出现类似状况呢?我总结的原因如下:
上个周末我一直在想,经过一年多在 skynet 上的开发,我已经有许多相关经验了。如果没有早期 erlang 版本的历史包袱以及刚开始设计 skynet 时的经验不足,去掉那些不必要的特性后的 skynet 应该是怎样的。
一个精简过代码的 skynet 不需要支持 Lua 之外的语言和通讯协议。如果某个服务的性能很关键,那么可以用 C 编写一个 Lua 库,只让 Lua 做消息分发。如果需要发送自定义协议的消息,可以把这个消息打包为一个 C 结构,然后把 C 结构指针编码在发送的消息中。
skynet 的内部控制指令全部可以移到一个系统服务中,用 Lua 编写。
跨机支持不是必要的。如果需要在多个进程/机器上运行多份协同工作,可以通过编写一个跨机通讯的服务来完成。虽然会增加一个间接层使跨进程通讯代价更大,但是可以简化许多代码。
广播也不是基础设施,直接用循环发送复制的消息即可。为了必要过大的消息在广播过程中反复拷贝,可以把需要广播的消息先打包为 C 对象,然后仅广播这个 C 对象的指针即可。
前几天在做 skynet 的 mongodb driver ,感觉以前为 skynet 做的 socket 库不太好用。
以前 skynet 对外的网络连接是通过 connection 服务实现的,这个服务会自动推送绑定的 socket 的上行数据到指定的位置。接下来,需要自己用 coroutine 去分析这个数据流。这样做比设计一个询问应答接口来获取 socket 上的数据流要高效一些,但用起来很不方便。
我希望能有一个看起来和传统的 socket api 类似的接口,直接 read/write 即可,但又不想失去性能。而且 read 不能阻塞住系统线程。
skynet 有一个叫做 gate 的模块,用来解决外部连接数据读取的问题。它最初是用我随手为 ringbuffer 示例 而写的一段代码改造成的。
最初我认为,用 epoll 去处理读事件足够了。至于写数据,完全可以用阻塞写的方式进行。因为 skynet 可以将事务分到多线程中,所以特定几个 socket 发生阻塞,也并不会把系统阻塞住。也可以简单的理解为,单线程读,多线程写。
随着我们的游戏的开发,这样做的弊端逐渐显露出来。大量玩家聚集的场景里,广播数据会突然同时塞满多条连接。skynet 的工作线程数据固定,这样就有可能因为同时写数据而阻塞住所有的工作线程。
今天解决了一个遗留多时的 bug , 想明白以前出现过的许多诡异的问题的本质原因。心情非常好。
简单来说,今天的一个新需求导致了我重读过去的代码,发现了一个设计缺陷。这个设计缺陷会在特定条件下给系统的一个模块带来极大的压力。不经意间给它做了一次高强度的压力测试。通过这个压力测试,我完善了之前并发代码中写的不太合理的部分。
一两句话说不清楚,所以写篇 blog 记录一下。
最开始是在上周,阿楠同学发现:在用机器人对我们的服务器做压力测试时的一个异常状况:机器人都在线的时候,CPU 占用率不算特别高。但是一旦所以机器人都被关闭,系统空跑时,CPU 占用率反而飚升上去。但是,经过我们一整天的调试分析,却没有发现有任何线程死锁的情况。换句话说,不太像 bug 导致的。
但是,一旦出现这种情况,新的玩家反而登陆不进去。所以这个问题是不可以放任不管的。
后来,我们发现,只要把 skynet 的工作线程数降低到 CPU 的总数左右,问题就似乎被解决了。不会有 CPU 飚升的情况,后续用户也可以登陆系统。
虽然问题得到了解决,但我一直没想明白原因何在,心里一直有点不爽。
经过一个月, 我基本完成了 skynet 的 C 版本的编写。中间又反复重构了几个模块,精简下来的代码并不多:只有六千余行 C 代码,以及一千多 Lua 代码。虽然部分代码写的比较匆促,但我觉得还是基本符合我的质量要求的。Bug 虽不可避免,但这样小篇幅的项目,应该足够清晰方便修正了吧。
花在 Github 上的这个开源项目上的实际开发实现远小于一个月。我的大部分时间花了和过去大半年的 Erlang 框架的兼容,以及移植那些不兼容代码和重写曾经用 Erlang 写的服务模块上面了。这些和我们的实际游戏相关,所以就没有开源了。况且,把多出这个几倍的相关代码堆砌出来,未必能增加这个开源项目的正面意义。感兴趣的同学会迷失在那些并不重要,且有许多接口受限于历史的糟糕设计中。
在整合完我们自己项目的老代码后,确定移植无误,我又动手修改了 skynet 的部分底层设计。在保证安全迁移的基础上,做出了最大限度的改进,避免背上过多历史包袱。这些修改并不容易,但我觉得很有价值。是我最近一段时间仔细思考的结果。今天这一篇 blog ,我将最终定稿的版本设计思路记录下来,备日后查阅。
今天发现 Skynet 消息处理的一个 bug ,是由多线程并发引起的。又一次觉得完全把多线程程序写对是件很不容易的事。我这方面经验还是不太够,特记录一下,备日后回顾。
Skynet 的消息分发是这样做的:
所有的服务对象叫做 ctx ,是一个 C 结构。每个 ctx 拥有一个唯一的 handle 是一个整数。
每个 ctx 有一个私有的消息队列 mq ,当一个本地消息产生时,消息内记录的是接收者的 handle ,skynet 利用 handle 查到 ctx ,并把消息压入 ctx 的 mq 。
ctx 可以被 skynet 清除。为了可以安全的清除,这里对 ctx 做了线程安全的引用计数。每次从 handle 获取对应的 ctx 时,都会对其计数加一,保证不会在操作 ctx 时,没有人释放 ctx 对象。
skynet 维护了一个全局队列,globalmq ,里面保存了若干 ctx 的 mq 。
这里为了效率起见(因为有大量的 ctx 大多数时间是没有消息要处理的),mq 为空时,尽量不放在 globalmq 里,防止 cpu 空转。
Skynet 开启了若干工作线程,不断的从 globalmq 里取出二级 mq 。我们需要保证,一个 ctx 的消息处理不被并发。所以,当一个工作线程从 globalmq 取出一个 mq ,在处理完成前,不会将它压回 globalmq 。
处理过程就是从 mq 中弹出一个消息,调用 ctx 的回调函数,然后再将 mq 压回 globalmq 。这里不把 mq 中所有消息处理完,是为了公平,不让一个 ctx 占用所有的 cpu 时间。当发现 mq 为空时,则放弃压回操作,节约 cpu 时间。
所以,产生消息的时刻,就需要执行一个逻辑:如果对应的 mq 不在 globalmq 中,把它置入 globalmq 。
需要考虑的另一个问题是 ctx 的初始化过程:
ctx 的初始化流程是可以发送消息出去的(同时也可以接收到消息),但在初始化流程完成前,接收到的消息都必须缓存在 mq 中,不能处理。我用了个小技巧解决这个问题。就是在初始化流程开始前,假装 mq 在 globalmq 中(这是由 mq 中一个标记位决定的)。这样,向它发送消息,并不会把它的 mq 压入 globalmq ,自然也不会被工作线程取到。等初始化流程结束,在强制把 mq 压入 globalmq (无论是否为空)。即使初始化失败也要进行这个操作。
最近我的工作都围绕 skynet 的开发展开。
因为这个项目是继承的 Erlang 老版本的设计来重新用 C 编写的。 再一些接口定义上也存在一些历史遗留问题. 我需要尽量兼容老版本, 这样才能把上层代码较容易的迁移过来。
最近的开发已经涉及具体业务流程了, 搬迁了不少老代码过来。 我不想污染放在外面的开源版本。 所以在开发机上同时维护了两个分支, 同时对应到 github 的公开仓库, 以及我们项目的开发仓库。
btw, 我想把自己的开发机上一个分支版本对应到办公室仓库的 master 分支, 遇到了许多麻烦。 应该是我对 git 的工作流不熟悉导致的。
这几天老在开会,断断续续的拖慢了开发进度。直到今天才把 Skynet 的集群部分,以及 RPC 协议设计实现完。
先谈谈集群的设计。
最终,我们希望整个 skynet 系统可以部署到多台物理机上。这样,单进程的 skynet 节点是不够满足需求的。我希望 skynet 单节点是围绕单进程运作的,这样服务间才可以以接近零成本的交换数据。这样,进程和进程间(通常部署到不同的物理机上)通讯就做成一个比较外围的设置就好了。
为了定位方便,我希望整个系统里,所有服务节点都有唯一 id 。那么最简单的方案就是限制有限的机器数量、同时设置中心服务器来协调。我用 32bit 的 id 来标识 skynet 上的服务节点。其中高 8 位是机器标识,低 24 位是同一台机器上的服务节点 id 。我们用简单的判断算法就可以知道一个 id 是远程 id 还是本地 id (只需要比较高 8 位就可以了)。
我设计了一台 master 中心服务器用来同步机器信息。把每个 skynet 进程上用于和其他机器通讯的部件称为 Harbor 。每个 skynet 进程有一个 harbor id 为 1 到 255 (保留 0 给系统内部用)。在每个 skynet 进程启动时,向 master 机器汇报自己的 harbor id 。一旦冲突,则禁止连入。
master 服务其实就是一个简单的内存 key-value 数据库。数字 key 对应的 value 正是 harbor 的通讯地址。另外,支持了拥有全局名字的服务,也依靠 master 机器同步。比如,你可以从某台 skynet 节点注册一个叫 DATABASE 的服务节点,它只要将 DATABASE 和节点 id 的对应关系通知 master 机器,就可以依靠 master 机器同步给所有注册入网络的 skynet 节点。
master 做的事情很简单,其实就是回应名字的查询,以及在更新名字后,同步给网络中所有的机器。
skynet 节点,通过 master ,认识网络中所有其它 skynet 节点。它们相互一一建立单向通讯通道。也就是说,如果一共有 100 个 skynet 节点,在它们启动完毕后,会建立起 1 万条通讯通道。
为了缩短开发时间,我利用了 zeromq 来做 harbor 间通讯,以及 master 的开发。蜗牛同学觉得更高效的做法是自己用 C 来写,并和原有的 gate 的 epoll 循环合并起来。我觉得有一定道理,但是还是先给出一个快速的实现更好。
最近两天是我们项目第二个里程碑的第一个检查点。我们的服务器在压力测试下有一些性能问题。很多方面都有一个数量级的优化余地,我们打算先实现完功能,然后安排时间重构那些值得提升性能的独立模块。
我最近两周没有项目进度线上的开发任务。所以个人得以脱身出来看看性能问题。前几天已经重新写了许多觉得可能有问题的模块。在前几天的 blog 里都有记录。
虽然没有明显的证据,但是感觉上,我们的服务器底层框架 skynet 有比较大的开销。这个东西用 Erlang 开发的,性能剖析我自己没有什么经验。总觉得 Erlang 本身代码基有点庞大,不太能清晰的理解各个性能点。
其实底层框架需要解决的基本问题是,把消息有序的,从一个点传递到另一个点。每个点是一个概念上的服务进程。这个进程可以有名字,也可以由系统分配出唯一名字。本质上,它提供了一个消息队列,所以最早我个人是希望用 zeromq 来开发的。
现在回想起来,无论是利用 erlang 还是 zeromq ,感觉都过于重量了。作为这个核心功能的实现,其实在 2000 行 C 代码内就可以很好的实现。事实上,我最近花了两个整天还不错的重新完成了这个任务,不过千余行 C 代码。当然离现在已有的框架功能,细节上还远远不够,但能够清晰的看到性能都消耗到哪些位置了。其实以后不用这个 C 版本的底层框架,作为一个对比测试工具,这半周时间也是花得很值得的。
我将这两天的工作开源到了 github 上,希望对更多人有帮助。从私心上讲,如果有同学想利用这个做开发,也可以帮助我更快发现 bug 。有兴趣的同学可以在这里跟踪我的开发进度 。
关于接口,我在上面提到的 blog 中已经列过了。这次重新实现,发现一些细节上不合理的地方,但是不太好修改,姑且认为是历史造成的吧。
在目前的版本里,我还没有实现跨机器通讯,我也不打算讲跨机通讯做到核心层中。而希望用附加服务的方式在将来实现出来。
这个系统是单进程多线程模型。
 2423
2423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























