







【第三周】网络爬虫之实战
一、Re(正则表达式)库入门
1.正则表达式的概念
1.1正则表达式是什么
正则表达式是用来简洁表达一组字符串的表达式。
使用正则表达式的优势就是:简洁、一行胜千言 一行就是特征(模式)
例1:代表一组字符串:

例2:代表一组(无穷个)字符串:

例3:代表一组具有某种特点但是枚举起来很繁琐的字符串:

简单来说:
正则表达式是用来简洁表达一组字符串的表达式
正则表达式是一种通用的字符串表达框架
正则表达式是一种针对字符串表达“简洁” 和“ 特征” 思想的工具
正则表达式可以用来判断某字符串的特征归属
1.2正则表达式可以干嘛
正则表达式在文本处理中十分常用:
可用来表达文本类型的特征(病毒、入侵等)
可用来同时查找或替换一组字符串
可用来匹配字符串的全部或部分
可用来……
最主要应用在字符串匹配中
1.3如何(在python)使用正则表达式
使用re模块:

2.正则表达式的语法
从下面一个经典例子讲起:

可以看出:正则表达式语法由字符和操作符构成
2.1正则表达式的常用操作符
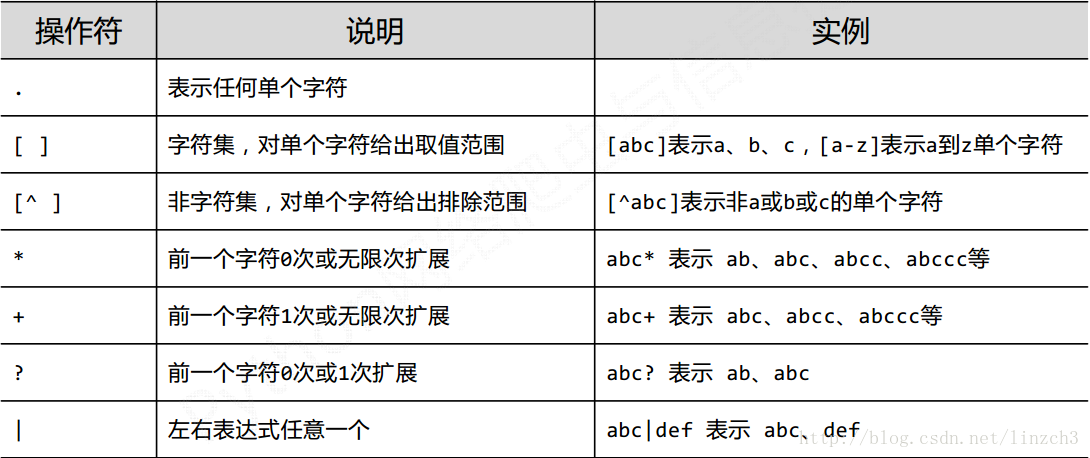
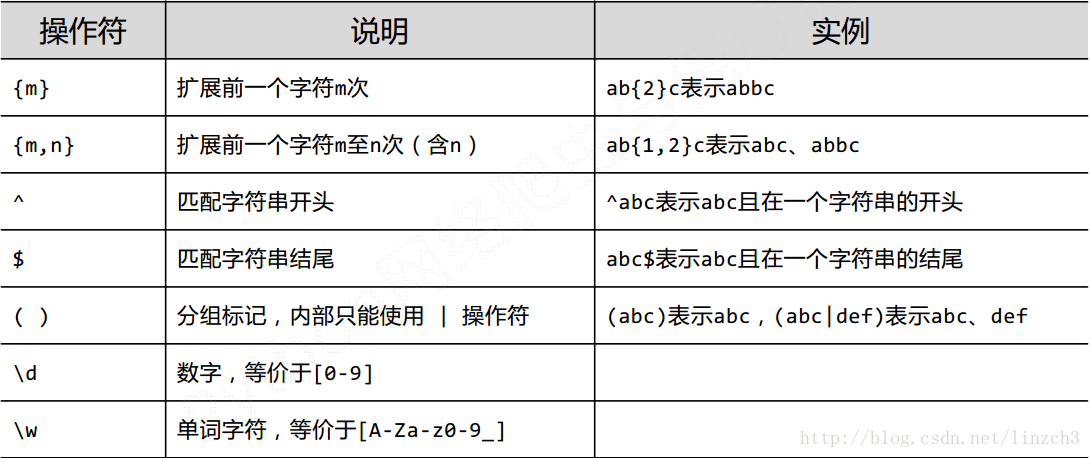
2.2正则表达式语法实例

2.3经典正则表达式实例

2.3.1匹配IP地址的正则表达式

3.Re库的基本使用
Re库是Python的标准库,主要用于字符串匹配
调用方式:import re
3.1正则表达式的表示类型
包含2种:raw string类型(原生字符串类型)和string类型
re库采用raw string类型表示正则表达式,表示为: r’text’
例如:
r'[1‐9]\d{5}'
r'\d{3}‐\d{8}|\d{4}‐\d{7}'简单来说:raw string是不包含对转义符再次转义的字符串。
re库也可以采用string类型表示正则表达式,但更繁琐
例如:
'[1‐9]\\d{5}'
'\\d{3}‐\\d{8}|\\d{4}‐\\d{7}'建议:当正则表达式包含转义符时,使用raw string。而为了使用的方便,笔者还是建议同一用raw string。
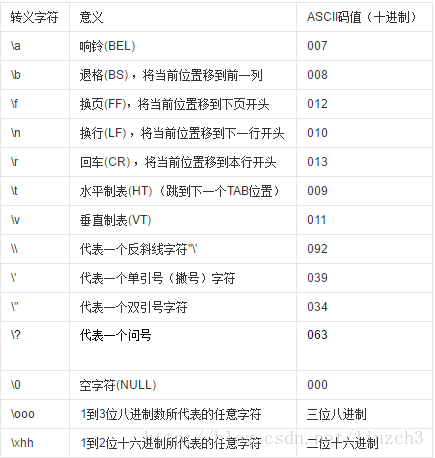
关于所有的转义字符和所对应的意义,可看这里:
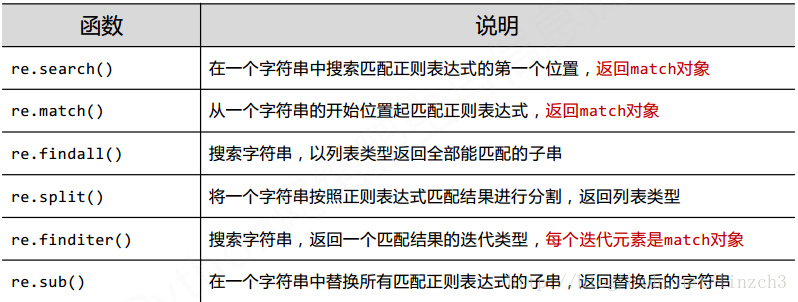
3.2Re库的主要功能函数
总体介绍:
3.2.1 re.search()
函数原型:re.search(pattern, string, flags=0)
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ string : 待匹配字符串
∙ flags : 正则表达式使用时的控制标记,常用标记如下:

功能:在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
举例:

3.2.2 re.match()
函数原型:re.match(pattern, string, flags=0),参数同上
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ string : 待匹配字符串
∙ flags : 正则表达式使用时的控制标记
功能:从一个字符串的开始位置起匹配正则表达式,返回match对象
举例:
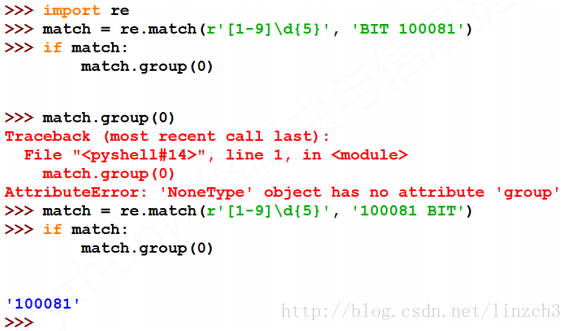
【重要】这里需要注意的是:当match为None时,直接输出match.group(0)就会报错。所以,为了程序的稳定性,通常需要使用:
if match:
match.group(0)来避免该错误。这种处理方法在爬虫程序中经常会见到。
3.2.3 re.findall()
函数原型:re.findall(pattern, string, flags=0),参数同上
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ string : 待匹配字符串
∙ flags : 正则表达式使用时的控制标记
功能:搜索字符串,以列表类型返回全部能匹配的子串
举例:

3.2.4 re.split()
函数原型:re.split(pattern, string, maxsplit=0, flags=0)
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ string : 待匹配字符串
∙ maxsplit: 最大分割数,剩余部分作为最后一个元素输出
∙ flags : 正则表达式使用时的控制标记
功能:将一个字符串按照正则表达式匹配结果进行分割,返回列表类型
举例:

3.2.5 re.finditer()
函数原型:re.finditer(pattern, string, flags=0)
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ string : 待匹配字符串
∙ flags : 正则表达式使用时的控制标记
功能:搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
举例:

3.2.6 re.sub()
函数原型:re.sub(pattern, repl, string, count=0, flags=0)
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ repl : 替换匹配字符串的字符串
∙ string : 待匹配字符串
∙ count : 匹配的最大替换次数
∙ flags : 正则表达式使用时的控制标记
功能:在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串
举例:

3.3Re库的另一种等价用法
举例:

re.compile函数原型:regex = re.compile(pattern, flags=0)
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ flags : 正则表达式使用时的控制标记
功能:将正则表达式的字符串形式编译成正则表达式对象
那么,Re库的函数用法等价为:

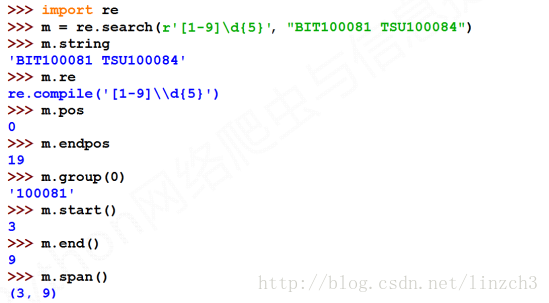
4.Re库的Match对象
Match对象是一次匹配的结果,包含匹配的很多信息
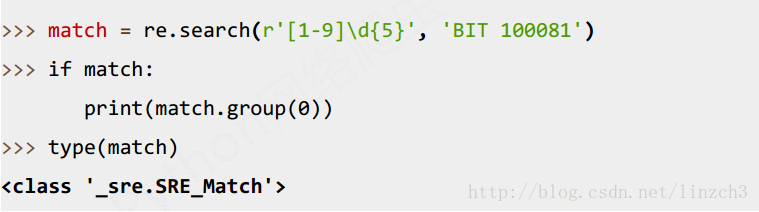
属性有:
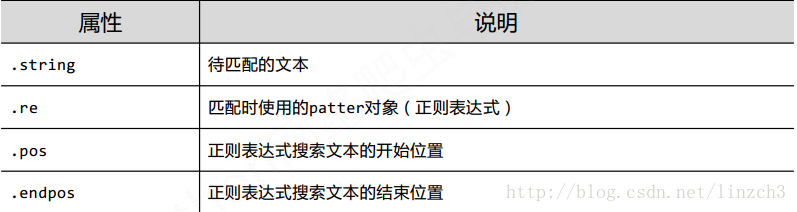
方法有:
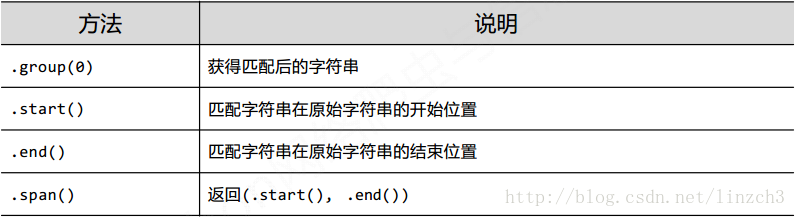
实例:
5.Re库的贪婪匹配和最小匹配
5.1贪婪匹配
首先看一个例子:
>>> match = re.search(r'PY.*N', 'PYANBNCNDN')
>>> match.group(0)可以发现代码中的正则表达式r’PY.*N’可同时匹配长短不同的多项,那么该返回哪一个呢?
实际输出结果为:
'PYANBNCNDN'原因是:Re库默认采用贪婪匹配,即输出匹配最长的子串
5.2最小匹配
那么该如何如何输出最短的子串呢?
解决方法:修改r'PY.*N'为r'PY.*?N'即可:
>>> match = re.search(r'PY.*?N', 'PYANBNCNDN')
>>> match.group(0)
'PYAN'5.2.1最小匹配操作符
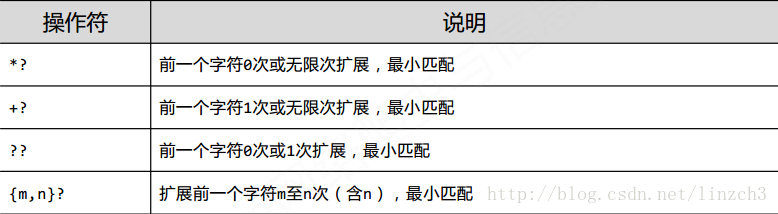
只要长度输出可能不同的,都可以通过在操作符后增加?变成最小匹配:
6.单元小结

二、实例1-淘宝商品比价定向爬虫
1.功能描述
目标:获取淘宝搜索页面的信息,提取其中的商品(书包)名称和价格
具体实现需要解决的问题:
1.淘宝的搜索接口:
https://s.taobao.com/search?q=keyword第一个页面的链接为:
https://s.taobao.com/search?q=书包&js=1&stats_click=search_radio_all%
3A1&initiative_id=staobaoz_20170105&ie=utf82.翻页的处理:
打开网页后,发现数据是分布在多个页面上的:

一般来说,这多个页面的链接是有一定的规律性的:
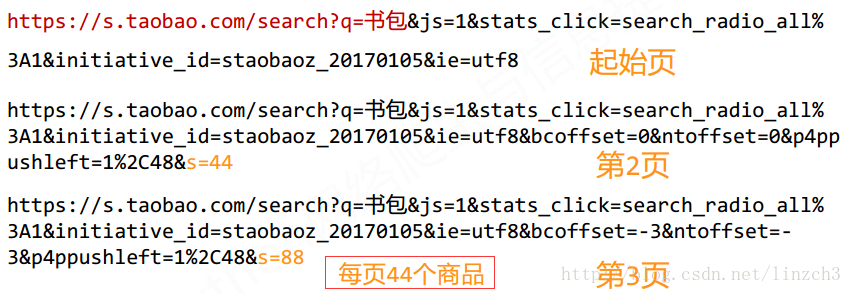
可以看到,修改s这个属性值就可以得到后面的页面的URL链接了。
3.技术路线:requests‐bs4‐re
4.观察网页源代码,找到要爬取的数据(书包的价格和名称)的所在位置:

2.程序结构设计
步骤1:提交商品搜索请求,循环获取页面
步骤2:对于每个页面,提取商品名称和价格信息
步骤3:将信息输出到屏幕上
首先,写出总体较抽象的代码:
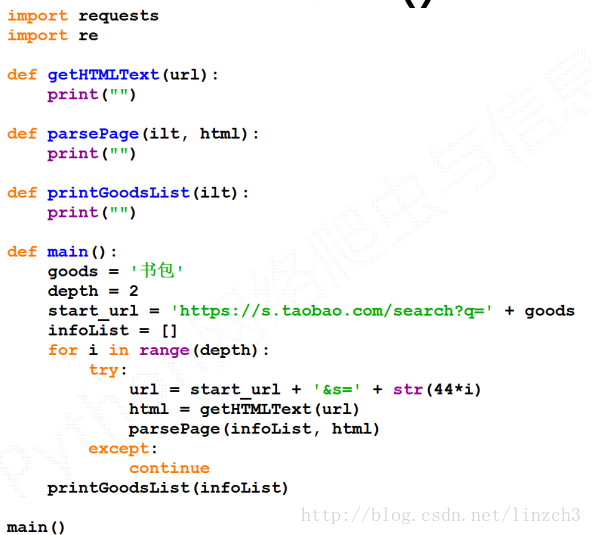
总体代码:
#CrowTaobaoPrice.py
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "failed\n"
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])#eval函数将字符串转为数字
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 3 #改段代码是演示用的,depth不能太大,淘宝本是不允许爬取搜索页面的
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
输出结果:
序号 价格 商品名称
1 129.00 瑞士军刀旅行双肩包男中学生书包电脑背包
2 69.00 迪士尼书包小学生男女1-3-4-6年级米奇减负背包儿童书包8-10-12岁
3 78.00 泰格奴防盗商务男女双肩包男士背包休闲学生书包电脑包韩版旅行包
4 143.00 七匹狼男士背包 书包中学生男商务双肩电脑包旅行包 背包双肩包男
5 79.00 日韩大容量帆布双肩包男潮双肩背包旅行包英伦风书包中学生女
6 167.00 越古帆布双肩包女士休闲复古文艺运动背包韩版中学生书包男包女包
7 37.44 日韩简约清新帆布双肩包女韩版潮学院风校园学生背包大小款书包女
8 69.00 2016新款韩版潮真皮背包时尚女士双肩包女百搭简约大容量学生书包
9 44.55 包包2017新款pu卡通小猫双肩包女韩版时尚百搭学院风学生书包背包
10 55.00 双肩包女士包包2017新款学生背包时尚韩版妈咪女包休闲书包旅行包
11 49.90 双肩包女士背包2017春季新款女包时尚百搭书包韩版休闲旅行包女潮
12 79.20 幼儿园布朗熊书包3-4-5岁 背包双肩包 手提包韩国热款 轻便容量大
13 59.00 2016新款个性创意磨砂皮海豚书包女双肩包男大容量旅行背包电脑包
14 198.00 SALONBUS沙隆巴斯 定制款复古英伦老花迷你小书包双肩背包斜挎包
15 145.00 双肩包男士背包旅游韩版学生书包时尚潮流休闲旅行潮包皮质电脑包
16 97.51 超值卡拉羊韩版学院风女双肩包大学生初中生中学生书包女旅行电脑
17 159.00 SHEVAN/希梵2016新款时尚女包双肩包女韩版百搭休闲背包简约书包
18 12.50 韩国版文艺2017简约帆布包男女单肩手提购物袋大女包学生书包森潮
19 99.36 米菲包包女小清新双肩包女学院风中学生书包帆布旅行背包大容量
20 98.00 2017女包上新款韩版潮双肩包女牛津布小怪兽背包时尚学院风书包
21 111.72 2017新款英伦时尚简约双肩包女包韩版潮流大背包学院风学生书包包
22 22.98 包邮秋冬文艺纯色布贴灯芯绒布包单肩斜跨两用拉链包女书包9色入
23 139.00 安踏配件双肩背包男女通用 春秋季笔记本电脑包学生书包背包
24 58.65 韩版多功能单肩双肩两用妈咪包大容量背包牛津布配真皮斜挎大书包
25 73.50 马塞洛双肩包男士韩版商务背包女中学生书包双肩休闲电脑包旅行包
26 59.00 乐天双肩包日系校园森女系撞色拼接大容量书包男女情侣背包电脑包
27 99.00 安踏男女双肩背包学生书包2016冬季新款时尚百搭旅游背包19648166
28 79.00 费莱德简约男包韩版学生书包女包潮PU皮男士双肩背包休闲旅行包
29 108.00 熊本熊包包学生包jk制服包女单肩书包可爱日系手提包通勤学院风萌
30 75.00 勇士库里30号 汤普森 大容量双肩包篮球背包 男 女包 学生书包nba
31 98.58 牛津布双肩包女日韩版时尚防水帆布背包韩国校园大学生休闲书包男
32 47.90 双肩包女韩版潮青少年休闲可爱背包百搭简约旅游灰粉色学生书包女
33 76.00 伊布雅双肩包女日韩版男背包纯色百搭中学生书包休闲电脑包旅行包
34 19.90 2016韩版亲子包儿童双肩背包胸包宝宝男童女童米奇皮包书包潮包
35 58.00 2016新款欧美双肩包女韩版可爱卡通创意个性喷绘背包中学生书包男
36 125.00 七匹狼新款双肩包韩版男女休闲背包学生书包商务电脑包旅行包正品
37 39.90 彩带流苏双肩包女2016新款铆钉徽章迷你小背包学院风休闲单肩书包
38 89.76 2017新款尼龙牛津布双肩包女包韩版潮轻休闲背包学生书包妈咪大包
39 77.52 2016新款春铆钉双肩包女韩版pu学院风2017小熊背包休闲百搭书包潮
40 49.90 2016新款韩版双肩包女复古PU背包潮百搭学院风旅行休闲中学生书包
41 59.00 秀洛我的世界Minecraft苦力怕书包游戏周边双肩背包男女学生夜光
42 79.00 森马双肩包女韩版 2016新款简约百搭学院风大学生书包男电脑包潮
43 59.00 2017新款牛津布双肩包女夏尼龙布防水书包女士休闲旅行背包韩版潮
44 38.00 瑞士军刀SWISSWIN儿童书包小孩双肩包卡通背包SWK1001A/B/C/D/E/F
45 59.90 包包女2017新款潮韩版百搭学院铆钉背包简约PU书包韩版双肩包小包
46 69.00 百搭明星新款双肩包软皮女包韩版学院风休闲时尚书包旅行背包潮女
47 146.51 JanSport杰斯伯超级叛逆儿童款迷你双肩包书包TDH6系列
48 59.00 背包双肩包男韩版大学生高中学生开学书包时尚潮流旅行旅游包简约
49 69.00 双肩包女韩版潮书包2017新款时尚百搭软羊皮女士包包旅行真皮背包
50 258.00 NIKE双肩包KYRIE 欧文男子篮球运动装备背包书包BA5133 BA5259
51 179.00 匡威包双肩包男包女包2017图案学生书包运动帆布背包10004349-A01
52 119.00 【买一送一】森马双肩包女韩版 百搭学院风大学生书包男旅行包潮
53 248.00 anello双肩包日本代购正品乐天男女书包包两用背包简约书包防水包
54 39.90 2016秋冬新款尼龙双肩包女背包牛津布包女士韩版潮书包女包方扣
55 158.00 开学季包邮订制图案炫彩硬壳电脑包18寸中学生高中生书包
56 28.50 韩国软妹灯芯绒双肩包原宿复古百搭学院风帆布日系男女学生书包潮
57 116.82 韩国复古个性书包女双肩包防泼水大学韩版学院风bf布料女小清新男
58 109.00 日本代购乐天双肩包磨砂手提包大容量电脑背包妈咪学生书包旅游包
59 30.24 新款时尚休闲防泼水书包女中学生旅行双肩包 学院风潮流印花背包
60 218.00 GOLF新品男士双肩包时尚多色旅行背包大学生书包电脑包悠闲包包
61 47.36 双肩包女韩版2017新款潮百搭休闲皮质大学生书包简约气质女生背包
62 277.00 正品匡威休闲双肩包男女学生书包旅行包 10002205102 10002205001
63 99.00 2017新款鲨鱼大小背包牛津布双肩包女学生男女书包旅行包
64 165.00 2016正品阿迪达斯男女包学生书包双肩背包AY4200 4183 4184 4199
65 79.00 冰雪奇缘儿童书包可爱双肩包女童8-10-12岁小学生书包3-4-6年级
66 37.00 猫猫包袋2017女包上新多用双肩包休闲拼色单肩斜挎包包女日韩书包
67 58.00 书包男女学生阴阳师动漫游戏周边神乐安培晴明莹草大天狗双肩背包
68 29.90 韩国ulzzang日本原宿软妹美少女战士露娜猫咪卖萌小号双肩背书包
69 49.90 小学生书包1-2-3年级4男孩双肩背包女儿童 6-7-8-9岁休闲旅行防水
70 22.90 韩国经典百搭黑色刺绣双肩包月亮十字架学生背包大容量情侣书包女
71 45.22 2017新款磨砂流苏双肩包女韩版大容量学院风背包百搭休闲学生书包
72 69.00 小恶魔小怪兽潮牌双肩包韩版男女初高中学生情侣书包夜光帆布包
73 49.90 户外登山包大容量书包潮女韩版多功能旅行背包运动双肩包男行李包
74 88.00 女双肩包复古欧美学生书包休闲背包电脑包碎花
75 39.90 双肩包女韩版pu背包时尚百搭女包学院风抽绳包包2016新款潮书包女
76 118.00 韩国kk树书包小学生男6-12周岁儿童书包女童1-3-5年级护脊双肩包
77 79.00 卡拉羊儿童小背包宝宝幼儿园书包男女小双肩包可爱卡通小包C6005
78 139.00 轻便防水中号背包双肩包多袋多功能多花色 书包
79 59.40 双肩包男个性学生书包时尚潮流简约旅行背包皮商务休闲防水电脑包
80 59.00 休闲双肩包女士背包学院风韩版学生书包时尚潮复古旅行电脑包潮包
81 65.00 牛津布全防水包包女生书包韩版学院风背包简约百搭学生双肩包帆布
82 45.00 李小璐同款双肩包女旅行包2016春夏款亮片背包女包韩版潮亮片书包
83 68.16 双肩包女包韩版PU皮全防水大容量高中学生书包流苏背包校园学院风
84 179.00 瑞戈瑞士军刀男女背包双肩包旅行包中学生书包休闲商务时尚包
85 59.00 休闲双肩包男士背包青年PU皮韩版潮流学生书包时尚大旅行包电脑包
86 19.80 韩版背包折叠轻便防水女旅行男旅游户外双肩包简约百搭学院风书包
87 99.00 奥王双肩包背包男初中生学生书包休闲男士商务旅行大容量电脑包
88 23.00 2016新款双肩包背包韩版时尚女包大容量女士包包简约双肩学生书包
89 79.00 黛妃洛 秋冬新品编织双肩包女士包时尚潮背包旅行大容量女包书包
90 41.80 韩版简约时尚休闲镭射pu双肩背包女中学生校园书包大容量百搭纯色
91 168.00 左岸潇明星同款潮牌双肩包菱格子品牌书包学生超轻便尼龙旅行背包
92 59.00 阪元宿宿大容量印花防水双肩包女韩版潮休闲背包中学生书包旅行包
93 99.00 瑞士军刀正品双肩包男商务15.6寸电脑包17寸中学生书包大容量背包
94 369.00 艾力夫|NEW BALANCE GC721032 GC641013 男女包运动包书包双肩包
95 49.90 新款双肩包女韩版pu皮森女系学院风学生书包小清新休闲百搭背包潮
96 49.00 双肩包女韩版学院风定型猫耳朵防水双肩大高中学生男书包百搭背包
97 49.00 【天天特价】户外登山包大容量旅行旅游背包双肩包男女运动包书包
98 137.70 JTXS正版镶钻亮片双肩背包女韩版明星同款亮片双肩背潮流旅游书包
99 136.08 ONLY双肩包女包2017新款韩版个性铆钉背包时尚书包潮流包包108
100 74.75 2017新款休闲旅行软皮配牛皮背包双肩包韩版潮女包学院风学生书包
101 1568.00 美国正品新款MK双肩包RHEA ZIP铆钉书包旅行背包真皮中号小号男女
102 872.00 美国代购蔻驰COACH新款迷你双肩小书包女背包F38395 38302 38263
103 35.00 单肩斜挎包加厚休闲布包大书包旅行包防水尼龙女包袋
104 27.90 儿童背包韩版中大童布小学生书包男孩时尚休闲旅行男童双肩包潮包
105 13.90 韩版冬季新款背包女包学生双肩包旅行包中小学书包大容量学生双背
106 48.00 女包双肩包pu复古子母包多功能背包日韩风旅行潮包学院风学生书包
107 79.00 双肩包男帆布旅行背包韩版百搭高中大学生书包女时尚潮流个性街头
108 88.00 双肩包男定制 电脑包背包 学生书包旅行背包定做logo
109 59.00 特价软皮双肩包女韩版背包简约包包学院风皮质女生书包休闲旅行包
110 88.00 Carney Road卡尼路军双肩包电脑包韩版潮运动旅行包高中学生书包
111 69.99 13寸手提电脑包男女军迷战术双肩包防水迷彩背包旅行单肩斜挎书包
112 45.00 死神 书包 双肩包 周边 背包 包包 动漫 黑崎一护 BLEACH 冬狮郎
113 39.00 黑白条纹双肩包背包女撞色学生书包帆布旅行包回家包日韩版情侣包
114 45.00 2016新款潮时尚小香风女包尼龙牛津布包双肩书包单肩斜挎旅行背包
115 55.00 牛津布双肩包男生韩版帆布背包时尚书包学院风旅行包新款潮书包包
116 35.00 Aape 猿人头 韩版英伦拼色学院风帆布双肩包男人书包背包时尚潮流
117 39.60 双肩包女包韩版皮料书包时尚百搭单肩包女士包包2017新款潮后背包
118 99.00 欧美复古双肩包女生学院风背包PU皮大容量书包潮高中 大学生书包
119 39.48 韩版双肩包男女简约休闲初中小学生书包帆布潮学院风旅行电脑背包
120 39.90 韩国代购水桶双肩包女韩版潮纯色防水背包学生书包大容量旅行包
121 449.00 代购直邮16新款欧美休闲百搭guess柳钉双肩包女包书包包邮
122 69.00 安踏书包背包春季皮革双肩背包休闲日韩学院双肩包19618158
123 99.00 安踏双肩背包学生书包2016夏季新款户外运动旅行电脑包|19628159
124 48.00 邮暴走大事件书包王尼玛暴走漫画个性搞笑男女背包双肩包原宿星空三、实例2-股票数据定向爬虫
1.功能描述
目标:获取上交所和深交所所有股票的名称和交易信息
输出:保存到文件中
技术路线:requests‐bs4‐re
2.数据网站的选择
候选数据网站:
新浪股票:http://finance.sina.com.cn/stock/
百度股票:https://gupiao.baidu.com/stock/
东方财富网:http://quote.eastmoney.com/stocklist.html
选择方法:
选取原则:股票信息静态存在于HTML页面中,非js代码生成,没有Robots协议限制
选取方法:浏览器 F12,源代码查看等
选取心态:不要纠结于某个网站,多找信息源尝试
测试结果:
由于东方财富网有所有股票的列表,所有股票的名称和代号都可以在一个页面上找到:
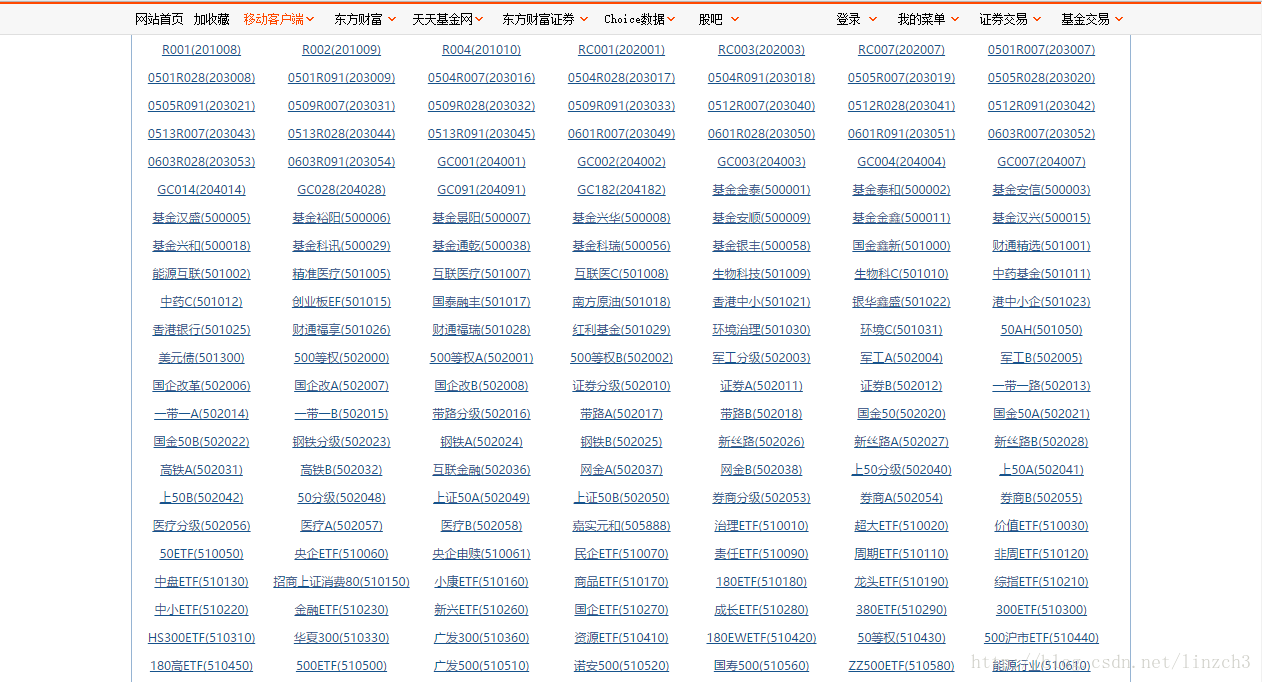
查看源代码后,可以看到股票名称和代号是有规律的。

然而点进去某个具体页面后发现数据采取不方便,页面比较繁杂。
测试百度股票后,发现可以直接通过股票代号来直接查询得到股票具体信息:
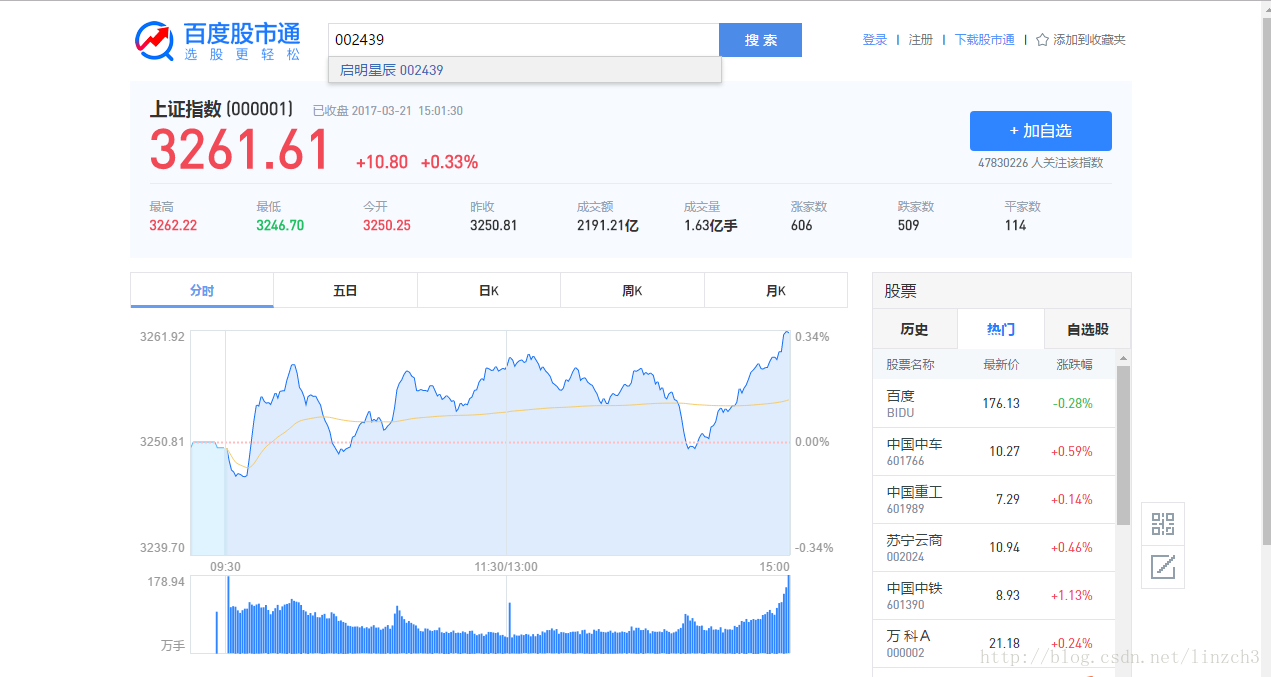
例如查询启明星辰这支股票:
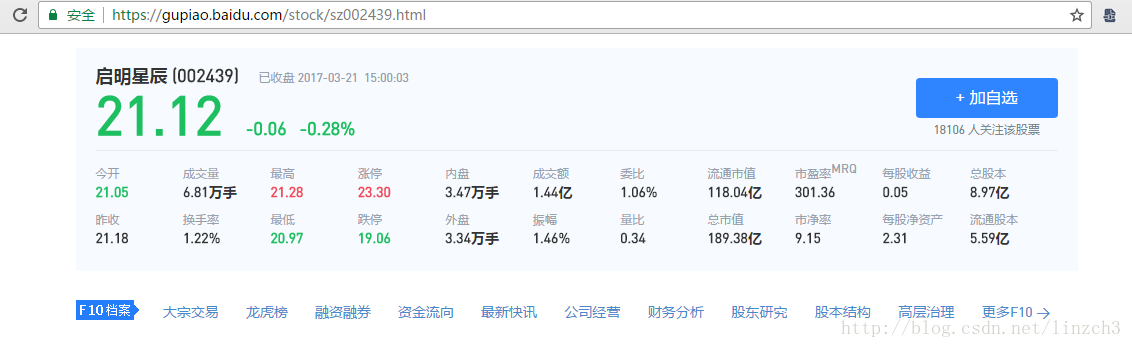
我们需要抓取的数据就是上面这些。查看源代码后可以发现数据是静态存在于HTML页面中的。
确定结果:
获取股票列表:
东方财富网:http://quote.eastmoney.com/stocklist.html
获取个股信息:
百度股票:https://gupiao.baidu.com/stock/
(例子:单个股票:https://gupiao.baidu.com/stock/sz002439.html)
3.程序的结构设计
步骤1:从东方财富网获取股票列表
步骤2:根据股票列表逐个到百度股票获取个股信息
步骤3:将结果存储到文件
首先,编写较为抽象的代码:
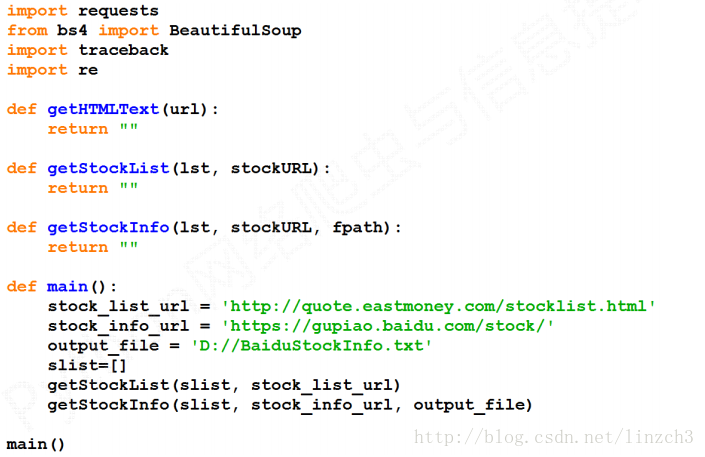
getStockList函数的实现:
上面提到,股票的代号信息是在网页源代码的a标签的href属性值上的,因此可通过正则表达式来提取。这里选择正则表达式为:r"[s][hz]\d{6}"(之所以不是r"[s][h]\d{6}"的原因见下面第二周图片)。
将网页向下滑动一段时间后,发现href属性值的代码起那么的两个字母sh改成了sz了。(实际上两者分别是上海和深圳的简写)。

代码:
def getStockList(stockList, stockURL):
html = getHTMLText(stockURL)
soup = BeautifulSoup(html, 'html.parser')
#股票名称和代号在网页源代码的a标签的href属性上
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
stockList.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
getStockInfot函数的实现:
由下面看到的源代码中:

可见数据是在<div class="bets-content">...</div>这个div标签内。
而下面这张图片的数据则是保存在上面的源代码的dt和dd标签上。
代码:
def getStockInfo(stockList, stockURL, fpath):
for stock in stockList:
url = stockURL + stock + ".html" #个股的详细查询页面
html = getHTMLText(url)
try:
if html == "":#异常判断
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
#找到第一个class属性值为stock-bets的div标签
stockInfo = soup.find('div', attrs={'class': 'stock-bets'})
if stockInfo==None:#异常判断
continue
#找到第一个class属性值为bets-name的a标签
name = stockInfo.find('a',attrs={'class': 'bets-name'})
#得到股票名称
infoDict.update({'股票名称': name.text.split()[0]})
#通过阅读网页源代码,发现数据可用键值对的形式存储
#找到所有dt标签(数据键值对的键)
keyList = stockInfo.find_all('dt')
#找到所有dd标签(数据键值对的值)
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
#将新增数据添加到文件
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict))
except:
#打印异常信息,这样的做法是 即是出现了异常,异常信息可以显示出来,但是程序仍会接着进行
traceback.print_exc()
continue总体代码:
# CrawBaiduStocksA.py
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL)
# 股票名称和代号在网页源代码的a标签的href属性上
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
def getStockInfo(stockList, stockURL, fpath):
for stock in stockList:
url = stockURL + stock + ".html" #个股的详细查询页面
html = getHTMLText(url)
try:
if html == "":#异常判断
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
#找到第一个class属性值为stock-bets的div标签
stockInfo = soup.find('div', attrs={'class': 'stock-bets'})
if stockInfo==None:#异常判断
continue
#找到第一个class属性值为bets-name的a标签
name = stockInfo.find('a',attrs={'class': 'bets-name'})
#得到股票名称
infoDict.update({'股票名称': name.text.split()[0]})
#通过阅读网页源代码,发现数据可用键值对的形式存储
#找到所有dt标签(数据键值对的键)
keyList = stockInfo.find_all('dt')
#找到所有dd标签(数据键值对的值)
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
#将新增数据添加到文件
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict))
except:
#打印异常信息,这样的做法是 即是出现了异常,异常信息可以显示出来,但是程序仍会接着进行
traceback.print_exc()
continue
def main():
# 股票列表页面(可得到所有股票代号和名称)
stock_list_url = 'http://quote.eastmoney.com/stocklist.html'
# 个股详细查询页面(根据股票代号可查询)
stock_info_url = 'https://gupiao.baidu.com/stock/'
# 保存爬取数据的文件
output_file = 'BaiduStockInfo.txt'
# 股票列表
stockList = []
# 得到股票列表
getStockList(stockList, stock_list_url)
# 得到所有个股的详细信息,并保存在输出文件
getStockInfo(stockList, stock_info_url, output_file)
main()4.实例优化
优化目的:提高用户体验
4.1getHTMLText函数的编码识别的优化
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""getHTMLText函数中的r.apparent_encoding需要分析文本,运行较慢,可辅助人工分析。
修改为:
def getHTMLText(url, code="utf-8"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except:
return ""并修改getStockList中调用getHTMLText的部分代码,修改后如下:
def getStockList(lst, stockURL):
html = getHTMLText(stockURL, "GB2312")
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue4.2提高用户体验:增加动态进度条的显示
在getStockInfo函数添加如下代码:
```python
def getStockList(lst, stockURL):
count=0
#.....
with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
count = count + 1
print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="")
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="")
continue
4.3优化后的总体代码:
# CrawBaiduStocksB.py
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url, code="utf-8"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL, "GB2312")
# 股票名称和代号在网页源代码的a标签的href属性上
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
def getStockInfo(stockList, stockURL, fpath):
count=0 #用于进度条的计数器
for stock in stockList:
url = stockURL + stock + ".html" #个股的详细查询页面
html = getHTMLText(url)
try:
if html == "":#异常判断
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
#找到第一个class属性值为stock-bets的div标签
stockInfo = soup.find('div', attrs={'class': 'stock-bets'})
if stockInfo==None:#异常判断
continue
#找到第一个class属性值为bets-name的a标签
name = stockInfo.find('a',attrs={'class': 'bets-name'})
#得到股票名称
infoDict.update({'股票名称': name.text.split()[0]})
#通过阅读网页源代码,发现数据可用键值对的形式存储
#找到所有dt标签(数据键值对的键)
keyList = stockInfo.find_all('dt')
#找到所有dd标签(数据键值对的值)
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
#将新增数据添加到文件
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict)+'\n')
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(stockList)), end="")
except:
#打印异常信息,这样的做法是 即使出现了异常,异常信息可以显示出来,但是程序仍会接着进行
#traceback.print_exc()
count = count + 1
print("\r当前进度: {:.2f}%".format(count * 100 / len(stockList)), end="")
continue
def main():
# 股票列表页面(可得到所有股票代号和名称)
stock_list_url = 'http://quote.eastmoney.com/stocklist.html'
# 个股详细查询页面(根据股票代号可查询)
stock_info_url = 'https://gupiao.baidu.com/stock/'
# 保存爬取数据的文件
output_file = 'BaiduStockInfo.txt'
# 股票列表
stockList = []
# 得到股票列表
getStockList(stockList, stock_list_url)
# 得到所有个股的详细信息,并保存在输出文件
getStockInfo(stockList, stock_info_url, output_file)
main()注意代码中\r的使用技巧:其将输出跳至当前输出的开头,因此可实现“动态进度条”的效果。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









