






背景介绍
Apache CarbonData是由华为开发并贡献至Apache基金会的开源项目,目前处于孵化阶段。据其官网称,CarbonData是基于一系列先进的列式存储、索引、压缩及编码技术而设计的大数据文件存储格式,它的出现能够使得PB级别的大数据量查询速度提升一个档次。
测试说明
本次测试将基于Apache CarbonData 0.2.0 发行版,就数据的加载、压缩和查询效率进行测试评估,并与现有其它存储格式(Parquet)进行相应对比。
测试环境
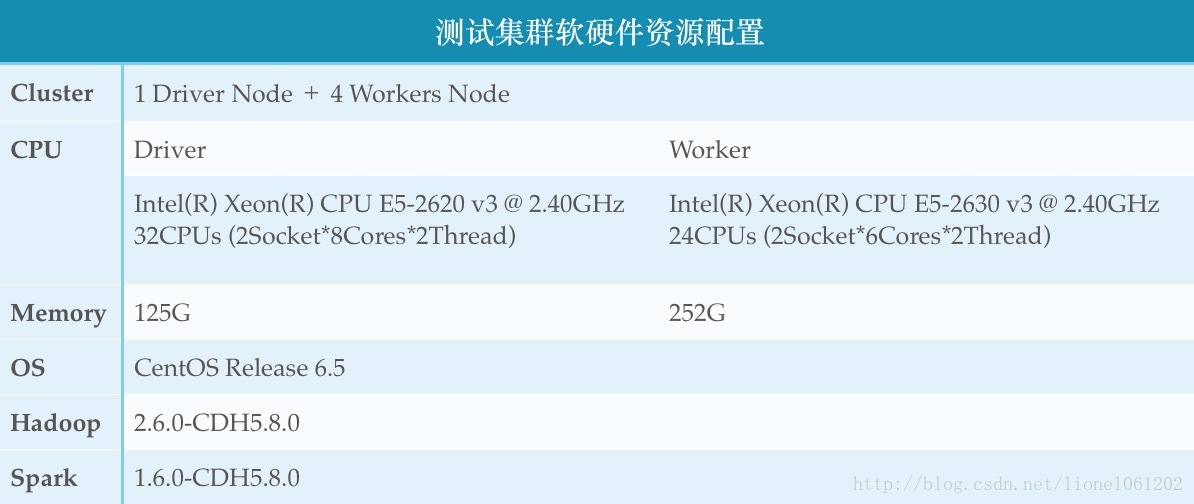
测试集群软硬件资源配置
测试数据样本
本次测试选择了某型号车辆实时数据的16个字段,其中11个维度,5个度量。

测试步骤
首先下载CarbonData源代码并编译jar包
git clone git@github.com:apache/incubator-carbondata.git
由于使用的测试集群是CDH-5.8.0, 因此编译assembly包的时候将Hadoop,Spark,Scala相关依赖设置为provided。如果不这么做的话一开始遇到过关于Akka版本不一致的报错。
cd incubator-carbondata/
mvn -DskipTests -Pspark-1.6 -Dspark.version=1.6.0 clean install
cd assembly/
mvn -DskipTests -Pspark-1.6 -Dspark.version=1.6.0 -Dspark.deps.scope=provided -Dhadoop.deps.scope=provided -Dscala.deps.scope=provided clean package将assembly/target/scala-2.10/下面生成的jar包scp到集群spark home目录下的carbonlib目录(需要手动创建,集群相关配置请参考官方文档,这里不做重复)。需要注意的是,虽然理论上提交spark job到yarn的时候,yarn会自动上传classpath中的jar包到hdfs并分发至所有data node,但实际测试过程中仍有可能报找不到类的错误,因此稳妥的做法是将assembly jar包copy至所有data node下面的carbonlib目录。
另外carbondata.properties, spark-default.conf以及插件目录的配置请参考官方wiki: Cluster deployment guide
部署完成以后我们就可以在spark-shell中玩一玩CarbonData了。
启动spark-shell, import CarbonContext类,构造一个cc:
scala>import org.apache.spark.sql.CarbonContext
scala>val storeLocation = "hdfs://nameservice2/opt/data/"
scala>val metaLocation = "hdfs://nameservice2/opt/carbonstore/"
scala>val cc = new CarbonContext(sc, storeLocation, metaLocation)这里如果你是使用官方repo bin目录下的carbon-spark-shell的话,他会默认给你初始化一个cc,但貌似是使用自带的标准版spark而不是你集群上的spark,因此我更倾向于自己import。
CarbonContext继承自HiveContext并且同样实现了sql功能。初始化的时候遇到过一个问题是如果storeLocation和metaLocation不显式声明hdfs前缀的话CarbonData会认为你是local linux文件系统目录,而如果恰好没有该目录存在的话就会报出No Such File or Directory的Exception。
下面我们可以开始建表,考虑到CarbonData dictionary创建的规则及原理,String类型字段默认会被看作维度而加入字典,另外官方建议将字段按照使用频率先后排列,需单独声明加入字典的字段尽量放在前面,而distinct值较多的列则不建议加入dictionary。
create table if not exists carbontest_001
(A String, B String, C String, D Double, E Double)
tblproperties('dictionary_include'='D', 'dictionary_exclude'='C')所有的sql语句与spark sql一样都可以使用cc.sql(“******”)来执行。
由于DataFrame API尚在开发中有些不稳定,本次测试仍采用0.1.0中的方式,即先将原始数据存为csv格式,再load进carbon table。Spark2.0中自带了csv导入导出接口,而Spark1.6及更早的版本可以使用databricks提供的spark-csv包:
<dependency>
<groupId>com.databricks</groupId>
<artifactId>spark-csv_2.10</artifactId>
<version>1.4.0</version>
</dependency>由于我使用的数据源是parquet格式存储的hive表,因此首先使用cc读取parquet文件,然后生成DataFrame并导出成csv文件:
val parquetFile = cc.read.parquet(config.getString("sourcePath"))
parquetFile.registerTempTable("parquetFile")
val df = cc.sql(config.getString("selectTable"))
val csvPath = config.getString("csvTargetPath")
df.write
.format("com.databricks.spark.csv")
.option("header", "true")
.save(csvPath)
logger.info(">>>>>> Saved temp csv file at:" + csvPath)然后load进入carbon table
cc.sql("load table inpath '******.csv' into table carbontest_001")Load完成之后可以在storeLocation中找到carbondata的数据文件,同时我们也可以开始查询carbondata table了。
在查询的时候一开始遇到一个巨坑,当查询结果中包含String类型字段的时候,总是会莫名其妙的报一个NPE错误,后来经过与Dev team沟通确认这是0.2.0的一个bug,master分支已经修复了这个问题只不过当时没有给0.2.0版本打上补丁,现在大家可以从branch-0.2直接下载并编译(注意不是tag: carbondata-0.2.0-incubating),这个问题已经得到修复。
最后测试结果如下:
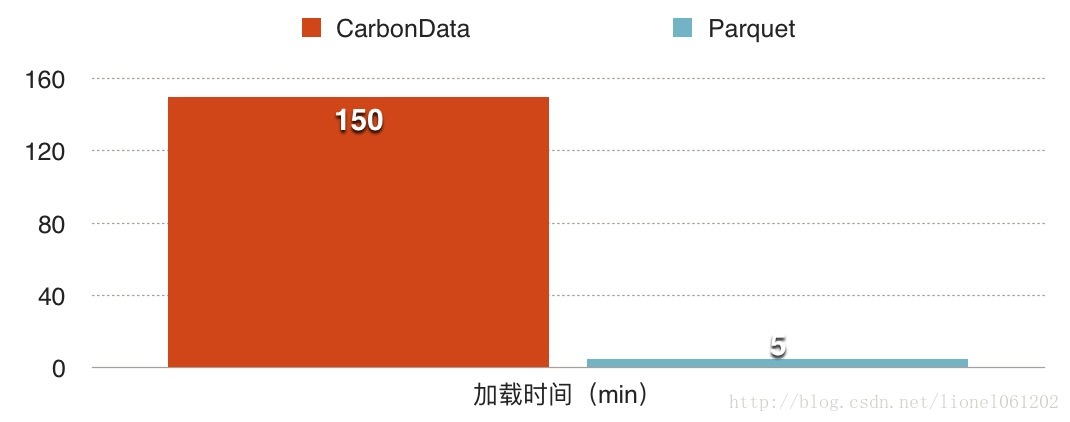
数据加载效率(Load)
Settings
–driver-memory 10g –num-executors 3 –executor-memory 50g –executor-cores 10
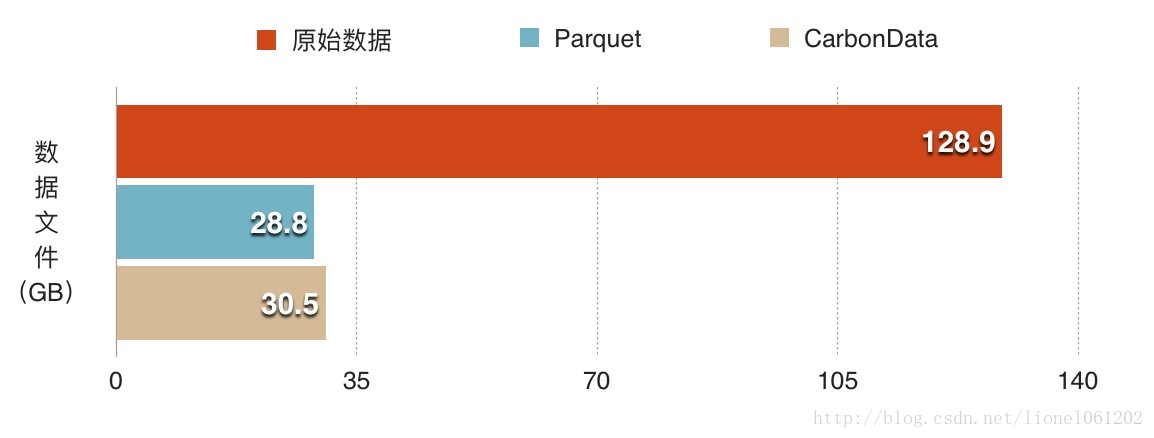
数据压缩效率(Compress)
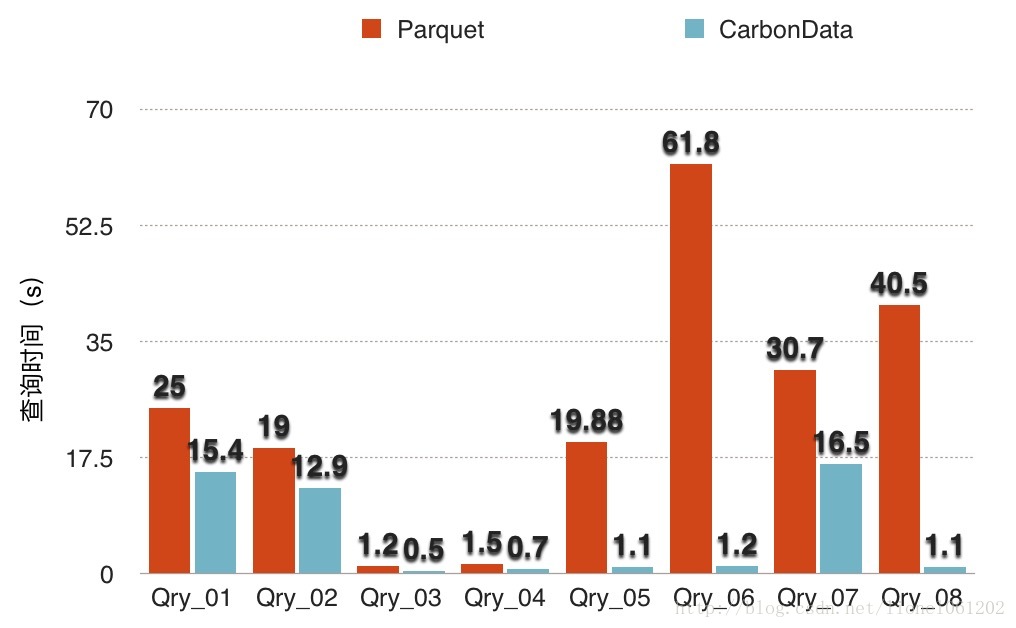
数据查询效率(Query)
Settings
–driver-memory 10g –num-executors 20 –executor-memory 20g –executor-cores 2
在官方的benchmark report当中只提供了load时候的spark资源配置并没有看到查询时候的配置,而在我的测试过程当中发现在查询的时候使用更多的executor个数+相对较少的executor-memory要比少量的executor+很大的executor-memory来的快,其原因也不难理解,在有大量数据文件的情况下,增加并发度自然可以提高查询效率,当然如果说是最优配置则需要结合自身的集群环境来进行调节。

测试结论
数据加载:CarbonData需要比Parquet更长的时间来创建字典和索引,官方放出的v0.1.0测试中1.9T数据Carbon 6.14小时,Parquet5.3小时,似乎差距并不大。而本次测试中Parquet5分钟加载时间则远低于CarbonData的2.5小时,原因还需进一步测试。
数据压缩:除去字典和索引文件以外,CarbonData与Parquet的压缩比率几乎完全一样。之所以得出这一结论是因为在某一次测试过程中,程序在最后一步由于丢失executor而长时间卡死的情况下被kill掉,最后在数据文件路径下面丢失了所有的索引文件,而剩下的数据文件和同样数据集另存的parquet文件大小一模一样,让人不禁联想华为的童鞋们是不是仅仅偷偷改了一个文件后缀- -!
数据查询:几乎所有查询CarbonData都要比Parquet来的更快,而在这两种场景下CarbonData表现尤其突出:带有过滤条件的查询和Group By查询。
原理解释(翻译自官方wiki,如有不恰当之处请自动忽略~):
CarbonData使用全局字典编码来加速计算过程,它可以先使用编码压缩过的数据进行计算/查询,然后再将结果集解码呈现给用户,这样做可以大量减少磁盘I/O。
CarbonData基于全局多维键(Global Multi Dimension Keys)给所有非度量字段创建B+树索引,同时配合最小/最大值索引可以快速命中包含符合筛选条件的数据的数据块。
CarbonData在数据块层级建立全字段反向索引,从而可以快速查询该数据块中符合筛选条件的数据行。最后感谢陈亮总,蔡强,威廉和其他朋友耐心的答疑解惑,让我少走了很多弯路,也希望本文的小小总结可以帮助刚刚接触CarbonData的同学们少踩一些坑。
参考资料:
官方wiki
祝威廉:CarbonData集群模式体验
作者: 曹鲁,目前供职于上汽集团数据业务部。














 1039
1039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









