







一、简介
HDFS在数据传输过程中,针对数据块Block,不是整个block进行传输的,而是将block切分成一个个的数据包进行传输。而DFSPacket就是HDFS数据传输过程中对数据包的抽象。
二、实现
HDFS客户端在往DataNodes节点写数据时,会以数据包packet的形式写入,且每个数据包包含一个包头,n个连续的校验和数据块checksum chunks和n个连续的实际数据块 actual data chunks,每个校验和数据块对应一个实际数据块,被用来做数据校验,防止数据传输过程中因网络原因等发生的数据丢包。
DFSPacket内数据的逻辑组织形式如下:

DFSPacket的物理实现如下:
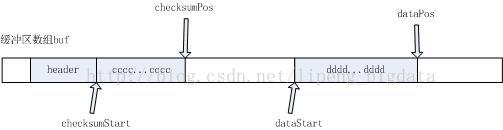
FSPacket在内部持有一个数据缓冲区buf,类型为byte[]
buf用来按顺序存储三类数据,header、checksum chunks、data chunks,分别对应上面的header区域、cccc…cccc区域和dddd…dddd区域
header、checksum chunks和data chunks都是提前分配好的,灰色代表已经写入数据区域,白色代表可以写入数据区域
Header是数据包的头部,它是在后续数据写完后才添加到数据包的头部。因为Header中包含了数据长度等信息,需要在数据写完后进行计算,故头部信息最后生成。Header内部封装了一个Protobuf对象,持有数据在Block中的位置offsetInBlock、数据包序列号seqno、是否为Block的最后一个数据包lastPacketInBlock、数据长度dataLen等信息,Header在写入DFSPacket中时,会在序列化Protobuf对象的前面追加一个数据长度大小和protobuf序列化大小,方便DataNode等进行解析。
DFSPacket内部有四个指针,分别为
1、checksumStart:标记数据校验和区域起始位置
2、checksumPos:标记数据校验和区域当前写入位置
3、dataStart:标记真实数据区域起始位置
4、dataPos:标记真实数据区域当前写入位置
数据包是按照一组组数据块写入的,先写校验和数据块,再写真实数据块,然后再写下一组校验和数据块和真实数据块,最后再写上header头部信息,至此整个数据包写完。
每个DFSPacket都对应一个序列号seqno,还存储了数据在数据块中的位置offsetInBlock、数据包中的数据块(chunks)数量numChunks、数据包中的最大数据块数maxChunks、是否为block中最后一个数据包lastPacketInBlock等信息。
三、源码分析
(一)初始化
DFSPacket的初始化分为以下几步:
1、首先计算缓冲区数据大小
1.1、首先,计算writePacketSize,即写包大小
这个是系统配置参数决定的。该大小默认是认为包含头部信息的,意即客户端自己指定的数据包大小,但是实际大小还需要后续计算得到。writePacketSize取自参数dfs.client-write-packet-size,表示客户端写入数据时数据包大小,默认为64*1024,即64KB
1.2、其次,计算bytesPerChecksum,即每多少数据计算校验和
这个是通过DataChecksum实例checksum的getBytesPerChecksum()方法得到的,如下:
public int getBytesPerChecksum() {
return bytesPerChecksum;
} DataChecksum dataChecksum = DataChecksum.newDataChecksum(
myOpt.getChecksumType(),
myOpt.getBytesPerChecksum());1.3、计算数据包body大小
bodySize = writePacketSize- PacketHeader.PKT_MAX_HEADER_LEN
最大头部PacketHeader.PKT_MAX_HEADER_LEN大小是一个合理的预估值,它是通过模拟构造一个protobuf对象,然后序列化成byte[]数组后,再加上一个固定的大小(Ints.BYTES + Shorts.BYTES);
Int所占区域用来存放数据包实际数据(含校验和,即除头部区域外的)大小,Short所占区域用来存放header protobuf对象序列化的大小,头部所占区域剩余的地方就是存放头部信息byte[];
1.4、计算chunkSize大小
chunkSize = bytesPerChecksum + getChecksumSize(),getChecksumSize()是获取校验和的大小,chunkSize意思是包含数据校验和块、真实数据块的大小
1.5、计算每个包能包含的块数
chunkSize=Math.max(bodySize/chunkSize, 1),最小为1;
1.6、计算缓冲区内数据大小:
packetSize = chunkSize*chunksPerPacket
chunkSize表示块大小,chunksPerPacket表示每个数据包由多少数据块
1.7、实际申请的缓冲区大小还要加上头部Header的最大大小
bufferSize = PacketHeader.PKT_MAX_HEADER_LEN + packetSize
2、申请缓存区数组
3、构造DFSPacket实例,确定各指针位置、其它指标等
2和3代码如下:
/** Use {@link ByteArrayManager} to create buffer for non-heartbeat packets.*/
/**
* 创建一个数据包
*/
private DFSPacket createPacket(int packetSize, int chunksPerPkt, long offsetInBlock,
long seqno, boolean lastPacketInBlock) throws InterruptedIOException {
final byte[] buf;
final int bufferSize = PacketHeader.PKT_MAX_HEADER_LEN + packetSize;
try {
buf = byteArrayManager.newByteArray(bufferSize);
} catch (InterruptedException ie) {
final InterruptedIOException iioe = new InterruptedIOException(
"seqno=" + seqno);
iioe.initCause(ie);
throw iioe;
}
return new DFSPacket(buf, chunksPerPkt, offsetInBlock, seqno,
getChecksumSize(), lastPacketInBlock);
}(二)写数据至缓冲区
写数据的过程:
1、 先写入一个校验和块;
2、 再写入一个真实数据块;
3、 块数增1;
4、 重复1-3,写入后续数据块组;
写数据是在DFSOutputStream中触发的,代码如下:
// 写入校验和
currentPacket.writeChecksum(checksum, ckoff, cklen);
// 写入数据
currentPacket.writeData(b, offset, len);
// 增加块数目
currentPacket.incNumChunks();
// 迭代累加bytesCurBlock
bytesCurBlock += len;DataPacket的实现也比较简单,代码如下(有注释):
/**
* Write data to this packet.
* 往包内写入数据
*
* @param inarray input array of data
* @param off the offset of data to write
* @param len the length of data to write
* @throws ClosedChannelException
*/
synchronized void writeData(byte[] inarray, int off, int len)
throws ClosedChannelException {
// 检测缓冲区
checkBuffer();
// 检测数据当前位置后如果 写入len个字节,是否会超过缓冲区大小
if (dataPos + len > buf.length) {
throw new BufferOverflowException();
}
// 数据拷贝:从数据当前位置处起开始存放len个字节
System.arraycopy(inarray, off, buf, dataPos, len);
// 数据当前位置累加len,指针向后移动
dataPos += len;
}
/**
* Write checksums to this packet
* 往包内写入校验和
*
* @param inarray input array of checksums
* @param off the offset of checksums to write
* @param len the length of checksums to write
* @throws ClosedChannelException
*/
synchronized void writeChecksum(byte[] inarray, int off, int len)
throws ClosedChannelException {
// 检测缓冲区
checkBuffer();
// 校验数据校验和长度
if (len == 0) {
return;
}
// 根据当前校验和位置和即将写入的数据大小,判断是否超过数据起始位置处,即是否越界
if (checksumPos + len > dataStart) {
throw new BufferOverflowException();
}
// 数据拷贝:从校验和当前位置处起开始存放len个字节
System.arraycopy(inarray, off, buf, checksumPos, len);
// 数据校验和当前位置累加len
checksumPos += len;
}
/**
* increase the number of chunks by one
* 增加数据块(chunk)数目
*/
synchronized void incNumChunks(){
numChunks++;
}(三)缓冲区数据flush到输出流
发送数据过程:
1、 计算数据包的数据长度;
2、 生成头部header信息:一个protobuf对象;
3、 整理缓冲区,去除校验和块区域和真实数据块区域间的空隙;
4、 添加头部信息到缓冲区:从校验和块区域起始往前计算头部信息的起始位置;
5、 将缓冲区数据写入到输出流。
逻辑比较简单,代码如下:
/**
* Write the full packet, including the header, to the given output stream.
* 将整个数据包写入到指定流,包含头部header
*
* @param stm
* @throws IOException
*/
synchronized void writeTo(DataOutputStream stm) throws IOException {
// 检测缓冲区
checkBuffer();
// 计算数据长度
final int dataLen = dataPos - dataStart;
// 计算校验和长度
final int checksumLen = checksumPos - checksumStart;
// 计算整个包的数据长度(数据长度+校验和长度+固定长度4)
final int pktLen = HdfsConstants.BYTES_IN_INTEGER + dataLen + checksumLen;
// 构造数据包包头信息(protobuf对象)
PacketHeader header = new PacketHeader(
pktLen, offsetInBlock, seqno, lastPacketInBlock, dataLen, syncBlock);
if (checksumPos != dataStart) {// 如果校验和数据当前位置不等于数据起始处,挪动校验和数据以填补空白
// 这个可能在最后一个数据包或者一个hflush/hsyn调用时发生
// Move the checksum to cover the gap. This can happen for the last
// packet or during an hflush/hsync call.
System.arraycopy(buf, checksumStart, buf,
dataStart - checksumLen , checksumLen);
// 重置checksumPos、checksumStart
checksumPos = dataStart;
checksumStart = checksumPos - checksumLen;
}
// 计算header的起始位置:数据块校验和起始处减去序列化后的头部大小
final int headerStart = checksumStart - header.getSerializedSize();
// 做一些必要的确保
assert checksumStart + 1 >= header.getSerializedSize();
assert headerStart >= 0;
assert headerStart + header.getSerializedSize() == checksumStart;
// Copy the header data into the buffer immediately preceding the checksum
// data.
// 将header数据写入缓冲区。header是用protobuf序列化的
System.arraycopy(header.getBytes(), 0, buf, headerStart,
header.getSerializedSize());
// corrupt the data for testing.
// 测试用
if (DFSClientFaultInjector.get().corruptPacket()) {
buf[headerStart+header.getSerializedSize() + checksumLen + dataLen-1] ^= 0xff;
}
// Write the now contiguous full packet to the output stream.
// 写入当前整个连续的packet至输出流
// 从header起始处,写入长度为头部大小、校验和长度、数据长度的总和
stm.write(buf, headerStart, header.getSerializedSize() + checksumLen + dataLen);
// undo corruption.
// 测试用
if (DFSClientFaultInjector.get().uncorruptPacket()) {
buf[headerStart+header.getSerializedSize() + checksumLen + dataLen-1] ^= 0xff;
}
}如果长时间没有数据传输,在输出流未关闭的情况下,客户端会发送心跳包给数据节点,心跳包是DataPacket的一种特殊实现,它通过数据包序列号为-1来进行特殊标识,如下:
public static final long HEART_BEAT_SEQNO = -1L; /**
* Check if this packet is a heart beat packet
* 判断该包释放为心跳包
*
* @return true if the sequence number is HEART_BEAT_SEQNO
*/
boolean isHeartbeatPacket() {
// 心跳包的序列号均为-1
return seqno == HEART_BEAT_SEQNO;
} /**
* For heartbeat packets, create buffer directly by new byte[]
* since heartbeats should not be blocked.
*/
private DFSPacket createHeartbeatPacket() throws InterruptedIOException {
final byte[] buf = new byte[PacketHeader.PKT_MAX_HEADER_LEN];
return new DFSPacket(buf, 0, 0, DFSPacket.HEART_BEAT_SEQNO,
getChecksumSize(), false);
}













 3301
3301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









