







3、隐语义模型
LFM核心思想在于通过隐含的特征联系用户兴趣和物品,即基于用户行为的统计数据来自动聚类,发现物品中隐含的类别,从而用于推荐。
3.1 基础算法
(1) 假设物品中隐含的类别( 隐特征)有个,参数
用来表征用户u的兴趣和第k个隐类的关系,参数
用来表征第i个物品和第k个隐类之间的关系,从而LFM定义了用户u对物品i的兴趣度量方式:
。那么显然LFM核心在于通过用户行为数据得到参数
(2) 参数
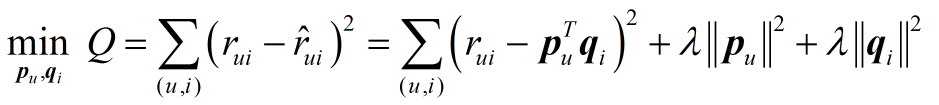
采用随机梯度下降法,很容易得到递推公式为
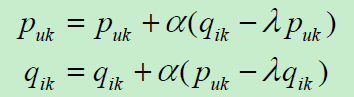
然后完成推荐程序即可。(3) Python实现代码如下:
### Select the negative samples ### in implicit feedback dataset & TopN recommandation ### def extendDataset(items_interacted, items_candidated): # the frequency of occurrence of certain item in the candidated items pool # is proportional to its popularity retDataset = dict() # positive samples for ii in items_interacted.keys(): retDataset[ii] = 1 # negative samples for ii in range(0, len(items_interacted)*3): # the upper bound len(items_interacted)*3 is for ensuring that # the number of negative samples is nearly same as positive samples item = items_candidated[random.randint(0, len(items_candidated)-1)] if item in retDataset: continue retDataset[item] = 0 n += 1 if n > len(items_interacted): break return retDataset def LFM(user_items, K, alpha, lam, maxIter): [P, Q] = InitModel(user_items, K) for iter in range(maxIter): for user, items in user_items.items(): samples = extendDataset(items) for item, rui in samples.items(): eui = rui - Predict(user, item) for k in range(K): P[user][k] += alpha*(eui*Q[item][k]-lam*P[user][k]) Q[item][k] += alpha*(eui*P[user][k]-lam*Q[item][k]) alpha *= 0.9 def Recommend(user, P, Q): rank = dict() for item in Q.keys(): for k, qik in Q[item].items(): puk = P[user][k] if item not in rank: rank[item] += puk*qik return rank
3.2 性能评价
(1)这里首先讲述下上面程序中样本扩展的内容。由于此书的重点在于讨论隐反馈数据集下TopN推荐的问题,显然其中一个特点就是原数据集只有正样本而没有负样本,这对于LFM中的算法学习显然是不可行的,因此,必须在原数据集上想办法为每个用户生成负样本。这里采用以下原则:对于每个用户,从那些热门物品且他没有过行为的物品中采样出一些作为负样本,采样时,要保证每个用户的正负样本数目相当。
(2)在完成样本扩充之后,LFM在TopN推荐中的性能实际上由四个参数影响:隐特征的个数K,学习速率alpha,正则化参数lambda和负/正样本比例ratio。实验证明,参数ratio对LFM性能影响最大。
(3)由LFM算法可以看出,LFM在每次训练时,即计算参数和
,都是在所有用户行为记录上进型的,而且为了效果更好,还要反复迭代,所以每次训练很耗时间和资源,一般实际应用中都是每天训练一次,很难实现实时更新。雅虎在新闻推送中为了解决LFM非常明显的冷启动问题,对兴趣计算公式采取了一些改进,有兴趣可以细读。
3.3 LFM与基于领域方法的比较
(1) 理论基础:LFM具有比较好的理论基础,是一种学习方法。基于领域的方法是一种基于统计的方法,没有学习的过程。
(2) 离线计算的空间复杂度:假设系统有M个用户和N个物品,基于领域的方法需要维护一张离线的相关表,可能这张表还是一张比较稠密的临时相关表,对于UserCF,用户相关表需要O(M*M)的空间,对于ItemCF,物品相关表需要O(N*N)的空间。对于有K个隐类的LFM来说,则需要O(K*(M+N))的存储空间。
(3) 离线计算的时间复杂度:进一步假设系统内每个用户对一件物品有F条评论的话,UserCF计算用户相关表需要的时间复杂度为O(N*(F/N)^2),而ItemCF的物品相关表为O(M*(F/M)^2),对于迭代S次的LFM来说,则是O(K*F*S)。一般情况下,LFM的时间复杂度稍高于基于领域的方法,但没有质的差别。
(4) 在线实时推荐:由于基于领域的方法可以将相关表缓存在内存中,可实施在线实时预测,由于LFM生成用户推荐列表速度太慢,因而不能执行在线实时计算,即当用户有了新的行为后,他的推荐列表并不会发生变化。
(5) 推荐解释:显然,LFM是没法提供推荐解释的。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









