







在数据挖掘中,统计学习方法常常用到R语言,因此,我们后面将对R语言在统计学习中的应用进行专题介绍,方便从理论上对统计学习有进一步深入的认识。
1初始步骤
开始运营R很简单,一种可以从系统菜单启动,双击图标或在系统命令行中输入命令”R“。这将产生一个控制台窗口,或在当前终端窗口启动一个交互式程序。在这两种情况下,R都是通过问答模式工作,即输入命令行并按下Enter键,然后程序运行,输出相关结果,继续要求更多输入。当R在准备输入状态时,它显示的提示符石“>”符号。
1.1大型计算器
R中最简单的任务可能就是输入一个算数表达式并得到结果。
eg:
2+2
[1] 4
exp(-2)
[1] 0.1353353
rnorm(15)
[1] 2.03314449 -1.94219751 0.02376473 0.79630659 -0.01148198 1.05401025
[7] 1.72357438 -1.30536388 -0.57136489 -2.27014811 -1.43595185 0.33359974
[13] 1.33672836 0.33639512 0.16830860
结果前面的[1]石R输出数字和向量的方式的一部分。括号中的数字时那一行第一个数字的序号。
1.2赋值
在R中变量可以自由选取,它可以有字母,数字和点号构成。然而,有一个限制是不能以数字开头,数字后也不能紧跟点号。
有些变量名已被系统使用,因此最好避免使用,如c、q、t、C、D、F、I和T,也有其他如diff、df和pt等。
<-为赋值符号,两个符号间无空格。
eg:
x<-2
x
[1] 2
x+x
[1] 4
1.3向量运算
结构c(…)用来构造向量。下面举例计算一组身高的BMI,并求变量的均值和标准差。
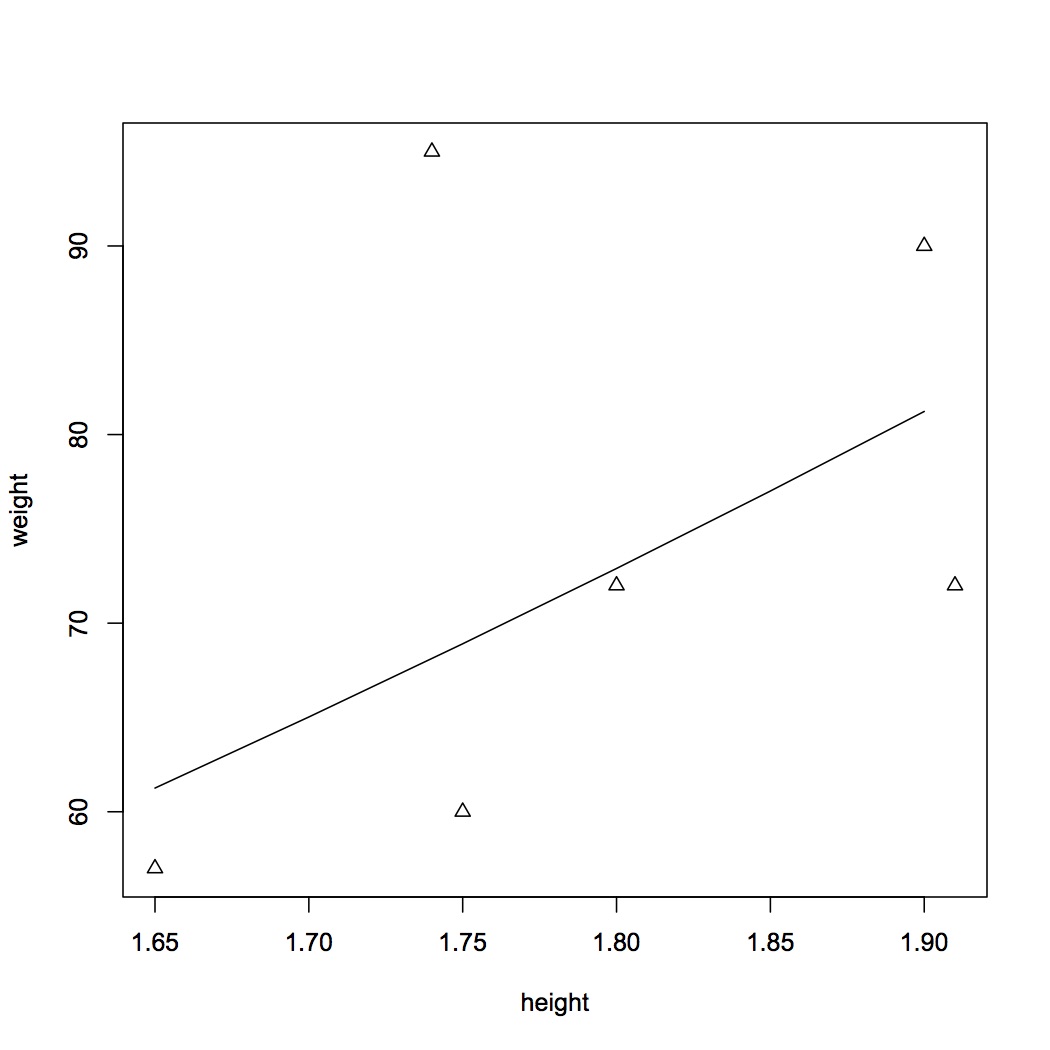
weight<-c(60, 72, 57, 90, 95, 72)
height<-c(1.75, 1.80, 1.65, 1.90, 1.74, 1.91)
bmi<-weight/height^2
bmi
[1] 19.59184 22.22222 20.93664 24.93075 31.37799 19.73630
xbar<-sum(weight)/length(weight)
sqrt(sum((weight-xbar)^2)/(length(weight)-1))
[1] 15.42293
mean(weight)
[1] 74.33333
sd(weight)
[1] 15.42293
1.4作图
plot(height, weight)
hh<-c(1.65, 1.70, 1.75, 1.80, 1.85, 1.90)
plot(height, weight, lines(hh, 22.5*hh^2), pch=2)
2 R语言基础
2.1 表达式和对象
R的一个基本交互模式时表达式求值。用户输入一个表达式,系统计算它并输出结果。
表达式通常包含变量引用、运算符、函数调用及其他。
表达式作用于对象。对象时一个抽象的术语,可以正对任何可以给变量赋值的事物。
2.2 函数和参数
一个函数的形式参数可以通过如下方式看到,eg:
>args(plot.default)
function (x, y = NULL, type = “p”, xlim = NULL, ylim = NULL,
log = “”, main = NULL, sub = NULL, xlab = NULL, ylab = NULL,
ann = par(“ann”), axes = TRUE, frame.plot = axes, panel.first = NULL,
panel.last = NULL, asp = NA, …)
NULL
很多函数的参数都有默认值,在不赋值的情况下系统自动选择默认值。
2.3 向量
数值向量c(…)
字符向量c(“ ”,“ ”…),也可用单引号。
逻辑向量c(T,F ….)
c(“huey”, “dewey”, “essy”)
[1] “huey” “dewey” “essy”
c(T, F, F, T)
[1] TRUE FALSE FALSE TRUE
bmi>25
[1] FALSE FALSE FALSE FALSE TRUE FALSE
2.4 引用和转义序列
要输出一个不带引号的字符串,需要使用cat函数。
cat(c(‘huey’, ‘dewey’, ‘louie’))
huey dewey louie
反斜杠\被称为转移字符,可以用\”方式插入引用字符。
eg:
cat(‘what is \”R”?’)
what is “R”?
2.5 缺失值
在实际数据分析中,数据点很多时候是无法得到的,R允许向量包含特殊的NA值。这个值在计算中可以执行,从而对NA的操作也产生NA作为结果。
2.6 生成向量的函数
2.6.1 c它时“concatenate”的简写,含义是把各分项首位连接。如果连接不同类型的向量,它们将被转化为最少“限制”的类型。
x<-c(red=’huey’, blue=’dewey’, green=’louie’)
x
red blue green
“huey” “dewey” “louie”
names(x)
[1] “red” “blue” “green”
c(FALSE, 3)
[1] 0 3
c(pi, “abc”)
[1] “3.14159265358979” “abc”
2.6.2 seq(‘sequence’),用来建立数字等差序列。
seq(4, 9)
[1] 4 5 6 7 8 9
4:9
[1] 4 5 6 7 8 9
seq(4, 8,2)
[1] 4 6 8
步长为1的情形特殊写法,如4:9。
2.6.3 rep(‘replicate’)用来产生重复值。使用时有两个参数,依赖于第二个参数是一个向量还是一个数字,产生的结果会有不同:
cops<-c(7, 9,13)
rep(cops, 3)
[1] 7 9 13 7 9 13 7 9 13
rep(cops, 1:3)
[1] 7 9 9 13 13 13
rep(1:2, c(10,15))
[1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
rep(1:2, each=10)
[1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2
2.7 矩阵和数组
在R中,‘矩阵’被拓展成仁义类型的元素,所以,可以建立一个字符串矩阵。
x<-1:12
dim(x)<-c(3,4)
x
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
dim函数设置或更改x的维度,使R将一个12个数字的向量作为一个3*4矩阵处理。
创建矩阵的一个更好的方法是使用matrix函数:matrix(1:12, nrow=3, byrow=T)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
byrow=T将矩阵改变成按行而不是列的形式填充。
对矩阵进行操作有用的函数包括rownames、colnames、转置函数t。x<-matrix(1:12, nrow=3, byrow=T)
rownames(x)<-LETTERS[1:3]
x
[,1] [,2] [,3] [,4]
A 1 2 3 4
B 5 6 7 8
C 9 10 11 12
t(x)
A B C
[1,] 1 5 9
[2,] 2 6 10
[3,] 3 7 11
[4,] 4 8 12
LETTERS是一个包含大写字母A-Z的内置变量。其他有用的相似变量有,letters,month.name,month.bbx<-letters[1:3]
x
[1] “a” “b” “c”
x<-cat(letters[1:3])
a b c
x<-month.abb[1:3]
x
[1] “Jan” “Feb” “Mar”
可以按列或按行分别使用cbind和rbind函数将向量“粘”在一起。
cbind(A=1:4, B=5:8, C=9:12)
A B C
[1,] 1 5 9
[2,] 2 6 10
[3,] 3 7 11
[4,] 4 8 12
rbind(A=1:4, B=5:8, C=9:12)
[,1] [,2] [,3] [,4]
A 1 2 3 4
B 5 6 7 8
C 9 10 11 12
2.8 因子
在R中,分类变量被指定为因子。
术语说一个因子有一系列水平——比如说4个水平。一个四水因子包含两项含义:(1)1到4之间整数的一个向量;(2)一个长度为4的包含字符串的特征向量。
pain<-c(0, 3, 2, 2, 1)
fpain<-factor(pain, level=0:3)
levels(fpain)<-c(‘none’, ‘mild’, ‘medium’, ‘severe’)
fpain
[1] none severe medium medium mild
Levels: none mild medium severe
as.numeric(fpain)
[1] 1 4 3 3 2
levels(fpain)
[1] “none” “mild” “medium” “severe”
函数as.numeric提取数字编码为1~4,levels提取水平的名称。注意数字0~3的原始输入编码不显示了,因为一个因子的内置表达方式始终是从1开始的数字。
2.9 列表
把一系列对象组合成一个复合对象有时候是很有用的。这可以通过list函数实现。
intake.pre<-c(5260, 5470, 5640, 6180, 6390, 6515, 6805, 7515, 7515, 8230, 8770)
intake.post<-c(3910, 4220, 3885, 5160, 5645, 4680, 5265, 5975, 6790, 6900, 7355)
mylist<-list(before=intake.pre, after=intake.post)
mylist
$before
[1] 5260 5470 5640 6180 6390 6515 6805 7515 7515 8230 8770
$after
[1] 3910 4220 3885 5160 5645 4680 5265 5975 6790 6900 7355
mylist$before
[1] 5260 5470 5640 6180 6390 6515 6805 7515 7515 8230 8770
2.10 数据框
数据框被称作“数据矩阵”或“数据集”。它时一系列等长度的向量和/或因子,它们交叉相关,使得同一位置的数据来自同一试验单元。除此之外,它具有唯一的一组行名称。
d<-data.frame(intake.pre, intake.post)
d
intake.pre intake.post
1 5260 3910
2 5470 4220
3 5640 3885
4 6180 5160
5 6390 5645
6 6515 4680
7 6805 5265
8 7515 5975
9 7515 6790
10 8230 6900
11 8770 7355
2.11 索引
如果需要向量中的一个具体元素,使用方括号来选择数据,称为索引货子集选择。
intake.pre[5]
[1] 6390
intake.pre[c(3, 5, 8)]
[1] 5640 6390 7515
intake.pre[-c(3,5,8)]
[1] 5260 5470 6180 6515 6805 7515 8230 8770
注意使用c(…)构造定义包含数字3、5、8的向量是必要的。R一个巧妙的功能是可以使用负索引。
2.12 条件选择
实际中需要提取满足某种标准的数据,可以通过插入一个关系表达式来得到。
intake.post[intake.pre>7000]
[1] 5975 6790 6900 7355
比较操作符有,<、>、==、>=、<=、!=。逻辑运算符&(和),|(或),!(不是)。
is.na(x)用来寻找x中哪些元素被记录成缺失(NA)。
2.13 数据框的索引
从数据框中提取向量:
d$intake.pre
[1] 5260 5470 5640 6180 6390 6515 6805 7515 7515 8230 8770
另一种方法是直接使用类似矩阵的结构:d<-data.frame(intake.pre,intake.post)
d[5,1]
[1] 6390
d[5,]
intake.pre intake.post
5 6390 5645
d[d intake.pre>7000,]intake.preintake.post87515597597515679010823069001187707355sel<−d intake.pre>7000
sel
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE TRUE TRUE
d[sel,]
intake.pre intake.post
8 7515 5975
9 7515 6790
10 8230 6900
11 8770 7355
head(d)
intake.pre intake.post
1 5260 3910
2 5470 4220
3 5640 3885
4 6180 5160
5 6390 5645
6 6515 4680
tail(d)
intake.pre intake.post
6 6515 4680
7 6805 5265
8 7515 5975
9 7515 6790
10 8230 6900
11 8770 7355
head函数默认显示前6行,tail函数默认显示后6行。
2.14 分组数据和数据框
在数据框中存储分组数据的自然方法是在一个向量中存储数据本身,另一个与之平行的因子(factor)纪录哪些数据来自哪些组。
split函数
2.15 隐式循环
循环的一个常用功能是把一个函数应用到一组值或向量中的每一个元素,并将结果返回一个单式结果中。
lapply函数总是返回一个列表;
sapply函数尽可能将结果简化成矢量或矩阵。
2.16 排序
对向量排序使用sort函数。
x<-rnorm(12)
x
[1] 0.4335017 0.4372568 1.1934421 1.3727015 0.3497570 0.6886749
[7] 0.6046269 0.0287556 -0.5967954 2.3482167 -1.0567021 0.2046624
sort(x)
[1] -1.0567021 -0.5967954 0.0287556 0.2046624 0.3497570 0.4335017
[7] 0.4372568 0.6046269 0.6886749 1.1934421 1.3727015 2.3482167
order(x)
[1] 11 9 8 12 5 1 2 7 6 3 4 10
o<-order(x)
x[o]
[1] -1.0567021 -0.5967954 0.0287556 0.2046624 0.3497570 0.4335017
[7] 0.4372568 0.6046269 0.6886749 1.1934421 1.3727015 2.3482167














 6194
6194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









