







链接:https://zhuanlan.zhihu.com/p/27344882
来源:知乎
Android应用程序把经过测量、布局、绘制后的surface缓存数据,通过SurfaceFlinger把数据渲染到屏幕上,通过Android的刷新机制来刷新数据。即 应用层负责绘制, 系统层负责渲染,通过 进程间通信把应用层需要绘制的数据传递到系统层服务,系统层服务通过 显示刷新机制把数据更新到屏幕。
接下来分别从 应用层、系统层和刷新机制三个方面来介绍下Android系统的显示原理。
应用层
我们都知道一个Android的UI界面layout是整体一棵由很多不同层次的View组成的树形结构,它们存在着父子关系,子View在父View中,这些View都经过一个相同的流程最终显示到屏幕上。
在Android中每个View的绘制中有三个核心步骤,通过Measure和Layout来确定当前需要绘制的View所在的大小和位置,通过绘制(Draw)到surface。
1)Measure
用深度优先原则递归得到所有View的宽、高;获取当前View的正确宽度childWidthMeasureSpec和childHeightMeasureSpec之后,可以调用它的成员函数Measure来设置它的大小。若子View是一个ViewGroup,那么它又会重复执行操作,直到它的所在子孙View的大小都测量完成为止。
2)Layout
用深度优先原则递归得到所有View的位置;当一个子View在应用程序窗口左上角的位置确定之后,再结合它在前面测量过程中确定的宽度和高度,就可以完全确定它在应用程序窗口中的布局。
3)Draw
Android支持两种绘制方式:软件绘制(CPU)和硬件绘制(GPU,要求>= Android3.0)。硬件加速在UI的显示和绘制的效率远远高于CPU绘制,但硬件也有明显缺点:
- 耗电:GPU功耗比CPU高;
- 兼容问题:某些接口和函数不支持硬件加速;
- 内存大:使用OpenGL的接口至少需要8MB内存。
系统层
Android是通过系统级进程中的SurfaceFlinger服务来把真正需要显示的数据渲染到屏幕上。SurfaceFlinger的主要工作是:
- 响应客户端事件,创建Layer与客户端的Surface建立连接。
- 接收客户端数据及属性,修改Layer属性,如尺寸、颜色、透明度等。
- 将创建的Layer内容刷新到屏幕上。
- 维持Layer的序列,并对Layer最终输出做出裁剪计算。
因应用层和系统层分别是两个不同进程,需要一个跨进程的通信机制来实现数据传输,在Android的显示系统中,使用了Android的匿名共享内存:SharedClient。每一个应用和SurfaceFlinger之间都会创建一个SharedClient,每个SharedClient中,最多可以创建31个SharedBufferStack,每个Surface都对应一个SharedBufferStack,也就是一个window。这意味着一个Android应用程序最多可以包含31个窗口,同时每个SharedBufferStack中又包含两个(<4.1)或三个(>=4.1)缓冲区。
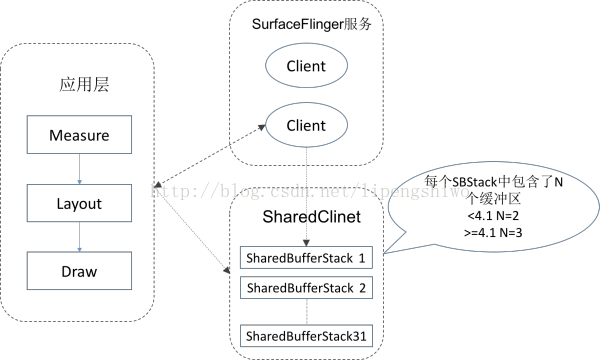
总结:应用层绘制到缓冲区,SurfaceFlinger把缓存区数据渲染到屏幕,两个进程之间使用Android的匿名共享内存SharedClient缓存需要显示的数据。
显示刷新机制
Android系统一直在不断的优化、更新,但直到4.0版本发布,有关UI显示不流畅的问题仍未得到根本解决。
从Android4.1版本开始,Android对显示系统进行了重构,引入了三个核心元素:VSYNC, Tripple Buffer和Choreographer。VSYNC是Vertical Synchronized的缩写,是一种定时中断;Tripple Buffer是显示数据的缓冲区;Choreographer起调度作用,将绘制工作统一到VSYNC的某个时间点上,使应用的绘制工作有序进行。
Android在绘制UI时,会采用一种称为“双缓冲”的技术,双缓冲即使用两个缓冲区(在SharedBufferStack中),其中一个称为Front Buffer,另外一个称为Back Buffer。UI总是先在Back Buffer中绘制,然后再和Front Buffer交换,渲染到显示设备中。理想情况下,一个刷新会在16ms内完成(60FPS),下图就是描述的这样一个刷新过程(Display处理前Front Buffer,CPU、GPU处理Back Buffer。
1.没有VSYNC信号同步时
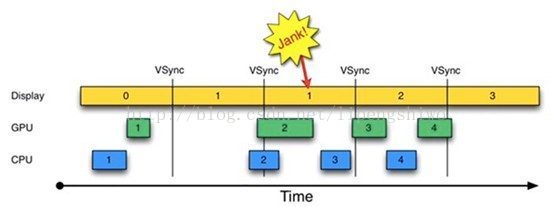
但实际运行时情况并不一定如此
1)第一个16ms开始:Display显示第0帧,CPU处理完第一帧后,GPU紧接其后处理继续第一帧。三者都在正常工作。
2)进入第二个16ms:因为早在上一个16ms时间内,第1帧已经由CPU,GPU处理完毕。故Display可以直接显示第1帧。显示没有问题。但在本16ms期间,CPU和GPU却并未及时去绘制第2帧数据(前面的空白区表示CPU和GPU忙其它的事),直到在本周期快结束时,CPU/GPU才去处理第2帧数据。
3)进入第三个16ms,此时Display应该显示第2帧数据,但由于CPU和GPU还没有处理完第2帧数据,故Display只能继续显示第一帧的数据,结果使得第1帧多画了一次(对应时间段上标注了一个Jank),导致错过了显示第二帧。
通过上述分析可知,此处发生Jank的关键问题在于,为何第1个16ms段内,CPU/GPU没有及时处理第2帧数据?原因很简单,CPU可能是在忙别的事情,不知道该到处理UI绘制的时间了。可CPU一旦想起来要去处理第2帧数据,时间又错过了。 为解决这个问题,Android 4.1中引入了VSYNC,核心目的是解决刷新不同步的问题。
2.引入VSYNC信号同步后
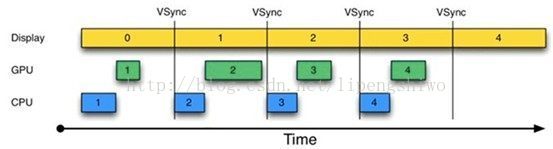
在加入VSYNC信号同步后,每收到VSYNC中断,CPU就开始处理各帧数据。已经解决了刷新不同步的问题。
但是上图中仍然存在一个问题:CPU和GPU处理数据的速度似乎都能在16ms内完成,而且还有时间空余,也就是说,CPU/GPU的FPS(帧率)要高于Display的FPS。由于CPU/GPU只在收到VSYNC时才开始数据处理,故它们的FPS被拉低到与Display的FPS相同。但这种处理并没有什么问题,因为Android设备的Display FPS一般是60,其对应的显示效果非常平滑。
但如果CPU/GPU的FPS小于Display的FPS,情况又不同了,将会发生如下图的情况:
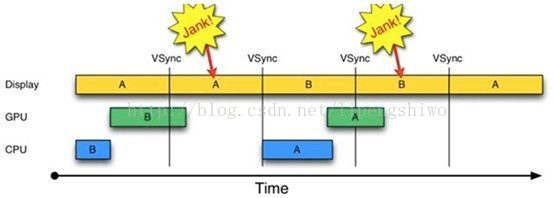
1)在第二个16ms时间段,Display本应显示B帧,但却因为GPU还在处理B帧,导致A帧被重复显示。
2)同理,在第二个16ms时间段内,CPU无所事事,因为A Buffer被Display在使用。B Buffer被GPU在使用。注意,一旦过了VSYNC时间点,CPU就不能被触发以处理绘制工作了。
为什么CPU不能在第二个16ms处开始绘制工作呢?原因就是只有两个Buffer(Android 4.1之前)。如果有第三个Buffer的存在,CPU就能直接使用它,而不至于空闲。于是在Android4.1以后,引出了第三个缓冲区:Tripple Buffer。Tripple Buffer利用CPU/GPU的空闲等待时间提前准备好数据,并不一定会使用。
3.引入Tripple Buffer后
引入Tripple Buffer后的刷新时序如下图:
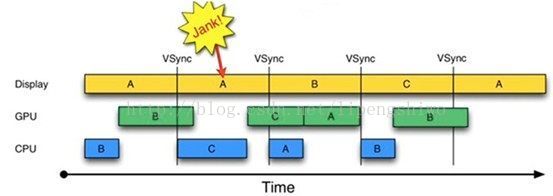
上图中,第二个16ms时间段,CPU使用C Buffer绘图。虽然还是会多显示A帧一次,但后续显示就比较顺畅了。
是不是Buffer越多越好呢?回答是否定的。由上图可知,在第二个时间段内,CPU绘制的第C帧数据要到第四个16ms才能显示,这比双Buffer情况多了16ms延迟。所以缓冲区并不是越多越好。
总结
从Android系统的显示原理可以看到,影响绘制的根本原因有以下两方面:
- 1.绘制任务太重,绘制一帧内容耗时太长。
- 2.主线程太忙了,导致VSYNC信号来时还没有准备好数据导致丢帧。
实际开发中,我们应该只在主线程做以下几方面的工作:
- UI生命周期控制
- 系统事件处理
- 消息处理
- 界面布局
- 界面绘制
- 界面刷新
除了这些以外,尽量避免将其它处理放到主线程中,特别是复杂的数据计算和网络请求。














 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









