







1. 保护模式下的描述符表的概念:
1) 保护模式相对于实模式最大的不同之处就是对软件的行为做出了很多约束,从而使系统的运行更加安全;
2) 在保护模式下段的使用非常严格,需要用各种信息维护段(比如段界限、可读写性、特权级、最下单位等),而这些信息就用一张描述符表来存放;
3) 描述表的概念:
i. 表中的每一项都保存一个描述符(也称为段描述符),用于存放当前某个段的相关信息,每个表项都固定占8字节(64位),里面存放了段的起始位置、段界限、属性这三个信息 iii. 描述符表是定义在内存中的,所有表项都是在地址层面上紧密连接(即连续)的,因此在进入保护模式之前必须先在内存中找一片空间定义GDT;
4) 保护模式下的CPU如何管理GDT呢?——使用全局描述符表寄存器GDTR:
i. GDTR即GDT Register,是一个48位的寄存器;
ii. 高32位是GDT在内存中的起始位置(即线性基地址),低16位是GDT的界限(即GDT的大小再减1,单位必然是字节),由于界限只有16位,因此最多只能容纳2^16 / 8 = 8192个全局描述符;
iii. 一般定义GDT的完整过程:先在内存中找一段空闲空间定义GDT,然后使用lgdt指令装载GDTR(即将基地址以及表界限装入GDTR中),lgdt即load gdtr的意思;
iv. lgdt的使用形式:lgdt m48,即gdtr的内容必须要事先准备在内存中(共48位);
v. 这样CPU就可以根据GDTR来找到GDT的位置了,并且可以清楚知道GDT的大小以免将其它内容当做GDT的表项;
5) 关于GDT的浮动问题:由于进入保护模式前是实模式,因此一开始只能在实模式下定义GDT,因此GDT只能存放在1MB的空间中,因此如果想将GDT让在4GB的任意位置处就必须等到进入保护模式之后再挪动GDT;
2. 32位线性地址以及段选择子(包括描述符高速缓存器):
1) 由于保护模式下CPU的32根地址线全都可以用(即CPU是32位模式的),所以可以访问的内存大小为4GB,并且32位模式下EIP也是32位的,即一个偏移指针就可以访问全部的4GB内存了,因此理论上就不需要用"段地址 << 4 + 偏移地址"的20位实模式的方式来访问内存了(因为实模式下段寄存器和偏移指针都只有16位(小于20位),只用这些寄存器无法访问20位地址线指向的内存);
2) 但由于Intel“兼容”的商业模式,要求即使是32位的CPU也必须使用"段地址:偏移地址"的形式来访问内存,但不过保护模式下段地址就直接是32位的,而偏移地址也是32位的,因此访问内存的时候无需将段地址移位,而直接就是"段地址+偏移地址=实际的地址",因此保护模式下的段地址和偏移地址都可以表示绝对的地址,那么整个地址空间就是一个线性的4GB的平坦的空间了,因此在保护模式下不管是段地址还是偏移地址都是线性空间中的一个绝对的点,因此它们都称为线性地址;
!而原来实模式下的段地址就不是线性地址,因为要对它×16才能得到1MB线性空间中的一个具体的位置
3) 那么问题来了,段地址既然是32位的,但是32位模式下没有32位的段寄存器,只有原先的16位的段寄存器cs、ds、es等,用16位的段寄存器如何表示32位的段地址呢?这个问题要回到之前讲过的GDT上了,GDT总共可以容纳8192个描述符,而16位的段寄存器就用来选择你想访问的那个段所对应的描述符,而描述符中存放着段的32位线性基地址,而那个32位线性基地址就是所谓保护模式下的段地址了;
!也就是说保护模式下的段寄存器不存放段地址,而是称作”段选择子“,因为所有对段的访问都通过GDT进行,GDT中存放的信息可以防止不安全行为(不像实模式中可以随便跳来跳去访问不该访问的内容而造成系统崩溃);
4) 整理一下保护模式下访问内存的过程(那cs为例):
cs(段选择子)选择一个描述符 --> 从描述符中取出32位线性段基 --> 拿该段基直接和EIP(32位)偏移地址相加 --> 最终得到32位绝对地址
5) 那么问题又来了,在保护模式下每次访问内存之前都要先间接地访问内存中的GDT岂不是很麻烦且很耗时(因为内存的速度比CPU寄存器的速度慢好几个数量级),实际上每个段寄存器的背后都有一个对应的64位描述符高速缓存器,每当段寄存器指向一个新的描述符时CPU都会将GDT对应的表项装进该缓存器中,如果之后不改变段选子的指向则缓存器的内容就不会变,因此在之后对该段的访问过程中32位基地址都会直接从该缓存器中拿,这就比从内存中的GDT拿方便多、快得多了!
!描述符高速缓冲寄存器位于CPU中,速度和普通寄存器相当,但是对程序员来说是不可见的,是由硬件自身来管理的;
3. 段描述符的格式:
1) 前面讲过,一个段描述符就描述符表中的一个表项,占8字节(64位),下面来看一下描述符的具体内容,感叹一下这奇葩的布局,其中上面为高32位,下面位低32位:

2) 其中绿色的是32位线性段基地址,红色的是20位段界限,其余都是段属性,那么问题又来了,不是说保护模式下可以访问全部的4GB空间吗,那为什么段界限是20位的而不是32位的呢?20位不是只能访问1MB的空间吗?
!这就需要属性为G位来配合说明了,G表示Granularity,即粒度的意思,用于解释段界限的含义,表示宽展的单位,如果G为0则表示段的扩展单位为字节,20位的界限则只能表示1MB的空间,如果G为1则表示扩展单位为4KB,则2^20 × 4KB刚好等于4GB,这不就能使用全部的4GB空间了嘛!因此有了G位可以让程序员有更多的选择了;
3) 为什么段基和段界限要分成好几块表示呢?从图中看32位线性段基和20位段界限在二进制位层次上不是连续的,布局如此之奇葩,这是因为Intel的"兼容"商业模式,保护模式最早是在80286中出现的,这个版本的CPU中有24位地址线,描述符的布局是上图的一部分,32位是从80386开始的,为了能兼容80286的程序所以要保留一部分原来的模样,同时在此基础上进行一定扩展,所以就出现了现在奇葩的局面;
4) 由于布局的奇葩,所以在定义描述符的时候也会比较麻烦,段基、段界限、属性不能连续定义,但是可以使用NASM提供的宏的功能来实现:
; Desc Base, Limit, Attr
; %1 %2 %3
%macro Desc 3
dw %2 & 0xFFFF
dw %1 & 0xFFFF
db (%1 >> 16) & 0xFF
dw ((%2 >> 8) & 0xF00) | (%3 & 0xF0FF)
db (%1 >> 24) & 0xFF
%endmacro!Attr供16位,包括了中间的4位段界限的占位,在宏分解的时候将忽略这4位,因此理论上这四位填0填1无所谓,但是为了统一规范都填0,;
!一般Attr都实现用宏定义好,比如DA_DR equ 0x90,其中前缀DA表示Descriptor Attribute,即描述符属性的意思,而后面的DR就表示Data & Read,即可读并且是数据段,这样可以是程序更加清晰;
4. 段描述符的属性:
1) G:之前已讲,表示该如何解释段界限的粒度;
2) D/B:只能作用于两种类型的段,短语代码段就是D位,即Default Operation Size,即默认操作数大小,如果为0,则表示用ip取指,如果为1则表示用eip取指;对于栈段来说就是B位,即Upper Bound,即上部边界,如果为0表示使用sp来操作栈,如果为1就表示用esp来操作栈;
!D/B位为0就是16位的保护模式,这种模式很少使用了,以后基本都是将D/B位置1的;
3) L:是为64位模式准备的,这里先不用,置0即可;
4) AVL:Available,即可使用的位,没有任何意义,仅仅是交给软件使用的位,一般会让操作系统拿去做自己想做的事情;
5) P:Present,即段存在位,0表示描述符对应的段还不在内存中,1就表示存在于内存中;是这样的,有时内存紧张,某个段可能会被交换到硬盘中暂时不用,但是该段的描述符仍然是存在的,只是就将该位清0即可,等到再交换回内存之后再置1;
6) DPL:Descriptor Previlege Level,即描述符的特权级,CPU共有4中特权级,即0、1、2、3,其中0级别最高,可以看做是从处理器继承而来的(一般都是操作系统进程拥有该特权级),3最低(一般是用户程序的级别),不同特权级的程序相互隔离,严格限制相互访问,并且有些指令只能由0级程序使用,为的就是安全;
!该位同时指定了要访问该段所必须用于的最低特权级,如果该位是2,则只有0、1、2特权级的程序才能访问;
7) S:System,即表示该段是否为系统段,0表示是系统段,1就表示是其它类型的段(代码段、数据段、栈段等等),系统段的概念之后会讲;
8) TYPE:共4位,对于数据段来说(栈也包括,只要是不是存放代码的都是数据段)是X、E、W、A,而对于代码段来说则是X、C、R、A
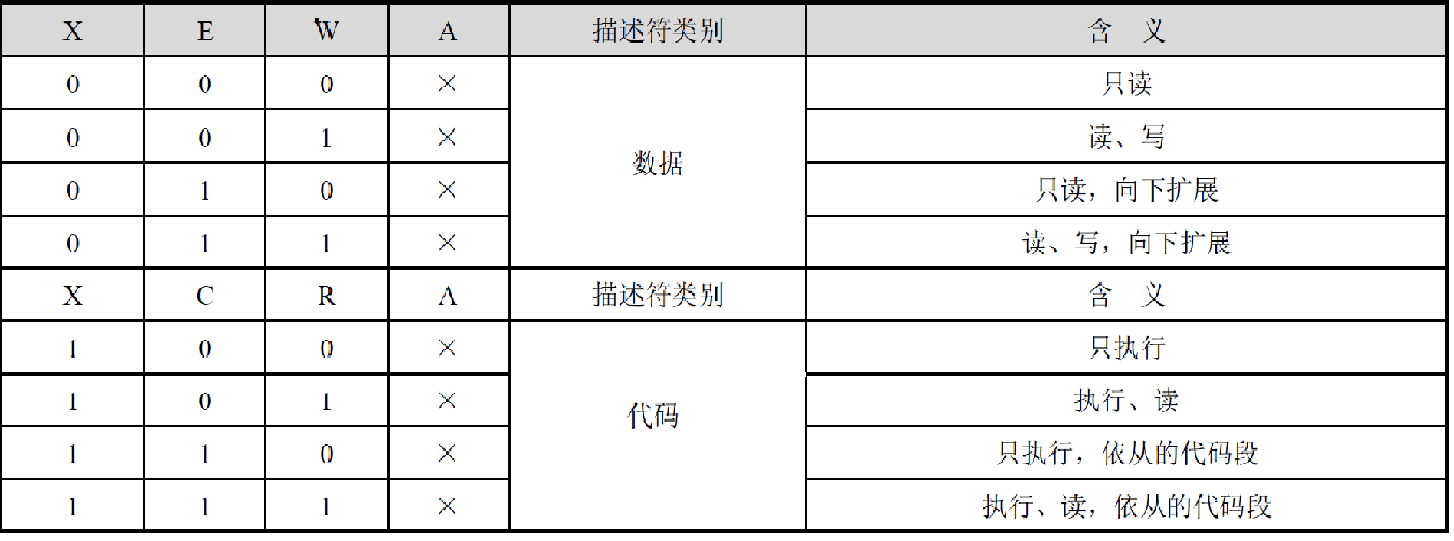
!其中X表示是否可执行,E表示扩展的方向(Extending Direction,0表示向上扩展(普通的数据段)、1表示向下扩展即栈段),W表示是否可写,其中数据段是默认可读的(即必须可读的);
!C表示特权级依从(之后会讲),R表示该代码段是否能被读取;
!是数据段还是代码段只看X位,代码段必须是可执行的,而数据段一定是不能执行的;
!A是Accessed位,表示该段是否被访问过了,用于访问计数,在虚拟内存管理LRU算法中等可以使用,主要留给操作系统;
5. 32位CPU是如何兼容16位实模式的?
1) 实模式下描述符高速缓存器在干什么?实际上在实模式下该缓存器也是工作的,只不过实模式下段寄存器存放的不是选择子(因为没有GDT)而是16位段地址,而在计算20位绝对物理地址的时候需要进行"段地址<<4 + 偏移地址"的变换,因此缓存器中的32位线性基址保存的正式"段地址<<4"的20位段基地址,只不过高12位没有用,恒为0而已,只有进入32位保护模式才真正有用,因此在访问内存的时候也不需要真正地对段地址左移4位,因为直接可以从描述符高速缓存器中取出已经移位好的20位段基并直接和偏移地址相加即可,因此32位CPU运行实模式要比16位CPU要更加快呢!
2) 其次就是”关闭A20机制“了:
i. 由于32位CPU有32根地址线,而实模式只需要用到20根,那该怎么办呢?多出了整整12根;
ii. 其实在实模式下并不需要关闭掉所有的这12根线,而只需要关掉第21根线(即A20,Address #20,从0开始编号)即可;
iii. 在原先16位CPU下当地址超过0xFFFFF时会产生溢位OF,并回0,程序员经常使用这招获得循环的内存空间,因此在32位CPU的环境中程序员同样希望能保留这个特征;
iv. 但是在32位地址线的情况下,地址超过0xFFFFF时只会向A20进位而不会溢位,即变成0x100000,因此干脆就关闭A20(是指永远为0,即使对其置1也没用),这样就能溢位并且保证能回0了;
v. 因此在进入32位保护模式之前必须先将A20打开,否则在保护模式中就只能使用20位地址而不能使用32位地址,这必定会导致程序的错误!
vi. 打开A20需要用到0x92控制端口,这在后面的代码中会讲到;
6. 段选择子的格式:
1) 段选择子就是要装进段寄存器的东西,并不是想选择几号描述符就对其赋值几,段选子有专门的格式;
2) 在16位段选择子中高13位是描述符的索引号,比如选择n号描述符就在高13位填n,而第3位从高到低是TI位和RPL位(占2位);
3) TI:Table Indicator,即描述符表指示器,为0表示选择的描述符在GDT中,为1表示描述符在LDT中;
4) RPL:Requested Privilege Level,即请求访问特权级,还是之前DPL的那4个特权级,这里表示要访问该选择子对应的段的那个程序的特权级,比如在程序A中的访问段B,因此需要将段B的描述符索引填到高13位中,而RPL则是程序A的特权级,如果处理器发现A的特权级低于B则拒绝A访问B,直接产生异常中暖;
5) 因此可以将低3位称为选择子的属性,可以发现选择子就是"描述符索引<<3 | Attr",即"描述符索引×8 | Attr",而每个描述符刚好占8字节,因此如果不考虑属性位的话选择子就是描述符在描述符表中的字节索引(从0号字节开始计算);
6) 因此在这里又可以使用宏函数定义选择子了:
; SELECTOR Index, Attr
%macro SELECTOR 2
dw (%1 << 3) | %2
%endmacro
7. 打开保护模式之门的钥匙——cr0:
1) cr是指Control Register,即控制寄存器,里面包含了一系列控制处理器操作模式和运行状态的标志位;
2) 控制寄存器有多个,cr0、cr1、cr2、cr3、cr4、cr8等;
3) 其中cr0的第0位(也就是最低位)如果是0则处理器处在16位实模式,如果置1就完全进入了32位保护模式,而该位就是PE位(Protect Enable),也就是说cr0的最低位就是打开保护模式之门的钥匙了;
4) 一旦该位被打开,则在一瞬间就进入了32位保护模式,gdtr将开始工作(监控GDT),内存的访问也变成了选择子模式,反正一切都要按照保护模式的来;
8. 从实模式到保护模式的中间过程:
1) 首先必须要关中断cli,因为进入中断例程需要跳转(也就是访问新的内存段),在实模式下是"偏移4位+”的方式,而保护模式下是"选择子“方式,这两种方式截然不同,因此在刚进入保护模式后BIOS中断必定正常使用,为了避免错误,必须在打开cr0#0之前先cli,然后在进入保护模式后重新设置BIOS中断向量,更新之后再开中断sti;
2) 扫除实模式的阴影:
i. 所谓实模式的阴影就是,在打开cr0#0后进入了全面的32位保护模式,但是此时cs中的值还是实模式下的段地址而不是选择子,并且cs的描述符高速缓存器中的内容也不是GDT中表项的内容,由于之后对内存的访问都是按照保护模式的规矩来的,因此不做更新必然会导致系统崩溃!
ii. 使用jmp指令扫除阴影:使用"jmp dword 选择子:偏移地址"的方式即可完成上述任务,首先会将选择子赋给cs,并根据GDT将相应的描述符载入cs的缓存器中,然后将EIP指向偏移地址;
!在32位保护模式下对cs:eip的修改也只能靠转移、调用、返回指令;
!修改其他段寄存器的内部运行过程也和上述同理,还是需要通用寄存器中转,比如mov ax, ds的选择子; mov ds, ax;
3) 清空指令流水线:
i. 由于CPU的并行功能,在执行一条指令的时候就已经将该指令后面的若干条指令提前译码并压入CPU的指令流水线中等待;
ii. 在打开cr0#0时就已经有很多指令在流水线之内了,但这些流水线指令是在进入32位保护模式之前就压入的,因此这些指令的格式都是16位,如果在进入32位保护模式之后仍然执行这些16位指令必定会发生错误,因此必须在打开cr0#0之后先清空流水线;
iii. 使用上述的jmp dword跳转指令即可清空流水线,由于程序的顺序被打破,因此流水线必定需要清空;
!小结:jmp dword在扫除实模式阴影的同时也清空了指令流水线,可以说是一举两得啊!
9. 保护模式准备的步骤总结:
1) 在1MB空间中挑一个合适的位置存放GDT;
2) 想好要定义的描述符,并将定义的内容装载到GDT中;
3) 数一下定义好的GDT的大小并看一下GDT的起始32位线性地址将其装入GDTR中(使用lgdt指令);
4) 打开A20;
5) cli关中断;
6) 打开cr0#0;
7) 用jmp dword清空流水线,并重置cs和cs的描述符高速缓存器;
8) 跳转到jmp指定的位置正式执行32位保护模式代码;
9) 调整BIOS中断向量使之适应32位保护模式下的调用;
10) sti开中断;
11) 干一些其它事情,比如操作系统引导之类的;














 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









