







 本文详细介绍了MapReduce编程模型,以及如何运行和分析Hadoop的WordCount程序。MapReduce通过"分而治之"的思想处理大规模数据,包括Map阶段、Shuffle阶段和Reduce阶段。在WordCount程序中,Map阶段对文本进行拆分和计数,Reduce阶段则将结果进行汇总。文章还涵盖了数据类型、源代码分析和执行流程。
本文详细介绍了MapReduce编程模型,以及如何运行和分析Hadoop的WordCount程序。MapReduce通过"分而治之"的思想处理大规模数据,包括Map阶段、Shuffle阶段和Reduce阶段。在WordCount程序中,Map阶段对文本进行拆分和计数,Reduce阶段则将结果进行汇总。文章还涵盖了数据类型、源代码分析和执行流程。
通常我们在学习一门语言的时候,写的第一个程序就是Hello World。而在学习Hadoop时,我们要写的第一个程序就是词频统计WordCount程序。
一、MapReduce简介
1.1 MapReduce编程模型
MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是”任务的分解与结果的汇总”。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:
- JobTracker用于调度工作的,一个Hadoop集群中只有一个JobTracker,位于master。
- TaskTracker用于执行工作,位于各slave上。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
1.2 MapReduce工作过程
对于一个MR任务,它的输入、输出以及中间结果都是<key, value>键值对:
- Map:
<k1, v1>——>list(<k2, v2>) - Reduce:
<k2, list(v2)>——>list(<k3, v3>)
MR程序的执行过程主要分为三步:Map阶段、Shuffle阶段、Reduce阶段,如下图:
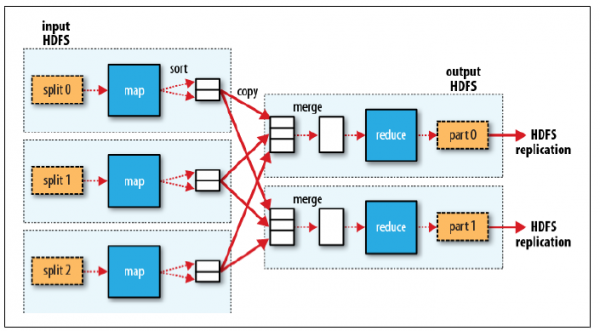
Map阶段
分片(Split):map阶段的输入通常是HDFS上文件,在运行Mapper前,FileInputFormat会将输入文件分割成多个split ——1个split至少包含1个HDFS的Block(默认为64M);然后每一个分片运行一个map进行处理。
执行(Map):对输入分片中的每个键值对调用
map()函数进行运算,然后输出一个结果键值对。- Partitioner:对
map()的输出进行partition,即根据key或value及reduce的数量来决定当前的这对键值对最终应该交由哪个reduce处理。默认是对key哈希后再以reduce task数量取模,默认的取模方式只是为了避免数据倾斜。然后该key/value对以及partitionIdx的结果都会被写入环形缓冲区。
- Partitioner:对
溢写(Spill):map输出写在内存中的环形缓冲区,默认当缓冲区满80%,启动溢写线程,将缓冲的数据写出到磁盘。
- Sort:在溢写到磁盘之前,使用快排对缓冲区数据按照partitionIdx, key排序。(每个partitionIdx表示一个分区,一个分区对应一个reduce)
- Combiner:如果设置了Combiner,那么在Sort之后,还会对具有相同key的键值对进行合并,减少溢写到磁盘的数据量。
合并(Merge):溢写可能会生成多个文件,这时需要将多个文件合并成一个文件。合并的过程中会不断地进行 sort & combine 操作,最后合并成了一个已分区且已排序的文件。
Shuffle阶段:广义上Shuffle阶段横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和merge/sort过程。通常认为Shuffle阶段就是将map的输出作为reduce的输入的过程
Copy过程:Reduce端启动一些copy线程,通过HTTP方式将map端输出文件中属于自己的部分拉取到本地。Reduce会从多个map端拉取数据,并且每个map的数据都是有序的。
Merge过程:Copy过来的数据会先放入内存缓冲区中,这里的缓冲区比较大;当缓冲区数据量达到一定阈值时,将数据溢写到磁盘(与map端类似,溢写过程会执行 sort & combine)。如果生成了多个溢写文件,它们会被merge成一个有序的最终文件。这个过程也会不停地执行 sort & combine 操作。
Reduce阶段:Shuffle阶段最终生成了一个有序的文件作为Reduce的输入,对于该文件中的每一个键值对调用
reduce()方法,并将结果写到HDFS。
二、运行WordCount程序
在运行程序之前,需要先搭建好Hadoop集群环境,参考《Hadoop+HBase+ZooKeeper分布式集群环境搭建》。
2.1 源代码
WordCount可以说是最简单的MapReduce程序了,只包含三个文件:一个 Map 的 Java 文件,一个 Reduce 的 Java 文件,一个负责调用的主程序 Java 文件。
我们在当前用户的主文件夹下创建wordcount_01/目录,在该目录下再创建src/和classes/。 src 目录存放 Java 的源代码,classes 目录存放编译结果。
TokenizerMapper.java
package com.lisong.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
IntWritable one = new IntWritable(1);
Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}IntSumReducer.java
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









