







ceph的CRUSH数据分布算法介绍
简介
CRUSH是ceph的一个模块,主要解决可控、可扩展、去中心化的数据副本分布问题。
ceph设计了CRUSH(一个可扩展的伪随机数据分布算法),用在分布式对象存储系统上,可以有效映射数据对象到存储设 备上(不需要中心设备)。因为大型系统的结构是动态变化的,CRUSH能够处理存储设备的添加和移除,并最小化由于存储设备的添加和移动而导致的数据迁移。
对象存储设备(object-based storage devices)管理磁盘数据块的分配,并提供对象的读写接口。在一些对象存储系统中,每个文件的数据被分成多个对象,这些对象分布在整个存储集群中。对象存储系统简化了数据层(把数据块列表换成对象列表,并把低级的数据块分配问题交给各个设备)。对象存储系统的基本问题是如何分布数据到上千个存储设备上。
一个robust解决方案是把数据随机分布到存储设备上,这个方法能够保证负载均衡,保证新旧数据混合在一起。但是简单HASH分布不能有效处理设备数量的变化,导致大量数据迁移。ceph开发了CRUSH(Controoled Replication Under Scalable Hashing),一种伪随机数据分布算法,它能够在层级结构的存储集群中有效的分布对象的副本。CRUSH实现了一种伪随机(确定性)的函数,它的参数 是object id或object group id,并返回一组存储设备(用于保存object副本)。CRUSH需要cluster map(描述存储集群的层级结构)、和副本分布策略(rule)。
CRUSH有两个关键优点:
任何组件都可以独立计算出每个object所在的位置(去中心化)。
只需要很少的元数据(cluster map),只要当删除添加设备时,这些元数据才需要改变。
CRUSH算法
CRUSH算法通过每个设备的权重来计算数据对象的分布。对象分布是由cluster map和data distribution policy决定的。cluster map描述了可用存储资源和层级结构(比如有多少个机架,每个机架上有多少个服务器,每个服务器上有多少个磁盘)。data distribution policy由placement rules组成。rule决定了每个数据对象有多少个副本,这些副本存储的限制条件(比如3个副本放在不同的机架中)。
CRUSH算出x到一组OSD集合(OSD是对象存储设备):
(osd0, osd1, osd2 … osdn) = CRUSH(x)CRUSH利用多参数HASH函数,HASH函数中的参数包括x,使得从x到OSD集合是确定性的和独立的。CRUSH只使用了cluster map、placement rules、x。CRUSH是伪随机算法,相似输入的结果之间没有相关性。
层级的Cluster map
Cluster map由device和bucket组成,它们都有id和权重值。Bucket可以包含任意数量item。item可以都是的devices或者都是 buckets。管理员控制存储设备的权重。权重和存储设备的容量有关。Bucket的权重被定义为它所包含所有item的权重之和。CRUSH基于4种 不同的bucket type,每种有不同的选择算法。
副本分布
副本在存储设备上的分布影响数据的安全。cluster map反应了存储系统的物理结构。CRUSH placement policies决定把对象副本分布在不同的区域(某个区域发生故障时并不会影响其他区域)。每个rule包含一系列操作(用在层级结构上)。
这些操作包括:
- tack(a)
:选择一个item,一般是bucket,并返回bucket所包含的所有item。这些item是后续操作的参数,这些item组成向量i。 - select(n,
t):迭代操作每个item(向量i中的item),对于每个item(向量i中的item)向下遍历(遍历这个item所包含的item),都返回n个
不同的item(type为t的item),并把这些item都放到向量i中。select函数会调用c(r,
x)函数,这个函数会在每个bucket中伪随机选择一个item。 - emit:把向量i放到result中。
存储设备有一个确定的类型。每个bucket都有type属性值,用于区分不同的bucket类型(比如”row”、”rack”、”host” 等,type可以自定义)。rules可以包含多个take和emit语句块,这样就允许从不同的存储池中选择副本的storage target。
冲突、故障、超载
select(n, t)操作会循环选择第 r=1,…,n 个副本,r作为选择参数。在这个过程中,假如选择到的item遇到三种情况(冲突,故障,超载)时,CRUSH会拒绝选择这个item,并使用r’(r’ 和r、出错次数、firstn参数有关)作为选择参数重新选择item。
- 冲突:这个item已经在向量i中,已被选择。
- 故障:设备发生故障,不能被选择。
- 超载:设备使用容量超过警戒线,没有剩余空间保存数据对象。
故障设备和超载设备会在cluster map上标记(还留在系统中),这样避免了不必要的数据迁移。
MAP改变和数据迁移
当添加移除存储设备,或有存储设备发生故障时(cluster map发生改变时),存储系统中的数据会发生迁移。好的数据分布算法可以最小化数据迁移大小。
Bucket的类型
CRUSH映射算法解决了效率和扩展性这两个矛盾的目标。而且当存储集群发生变化时,可以最小化数据迁移,并重新恢复平衡分布。CRUSH定义了四种具有不同算法的的buckets。每种bucket基于不同的数据结构,并有不同的c(r,x)伪随机选择函数。
不同的bucket有不同的性能和特性:
- Uniform Buckets:适用于具有相同权重的item,而且bucket很少添加删除item。它的查找速度是最快的。
- List
Buckets:它的结构是链表结构,所包含的item可以具有任意的权重。CRUSH从表头开始查找副本的位置,它先得到表头item的权重Wh、剩余
链表中所有item的权重之和Ws,然后根据hash(x, r,
item)得到一个[0~1]的值v,假如这个值v在[0~Wh/Ws)之中,则副本在表头item中,并返回表头item的id。否者继续遍历剩余的链
表。 - Tree Buckets:链表的查找复杂度是O(n),决策树的查找复杂度是O(log
n)。item是决策树的叶子节点,决策树中的其他节点知道它左右子树的权重,节点的权重等于左右子树的权重之和。CRUSH从root节点开始查找副本
的位置,它先得到节点的左子树的权重Wl,得到节点的权重Wn,然后根据hash(x, r,
node_id)得到一个[0~1]的值v,假如这个值v在[0~Wl/Wn)中,则副本在左子树中,否者在右子树中。继续遍历节点,直到到达叶子节点。
Tree
Bucket的关键是当添加删除叶子节点时,决策树中的其他节点的node_id不变。决策树中节点的node_id的标识是根据对二叉树的中序遍历来决
定的(node_id不等于item的id,也不等于节点的权重)。 - Straw
Buckets:这种类型让bucket所包含的所有item公平的竞争(不像list和tree一样需要遍历)。这种算法就像抽签一样,所有的item
都有机会被抽中(只有最长的签才能被抽中)。每个签的长度是由length = f(Wi)*hash(x, r, i)
决定的,f(Wi)和item的权重有关,i是item的id号。c(r, x) = MAXi(f(Wi) * hash(x, r, i))。
图1 Tree Buckets的结构
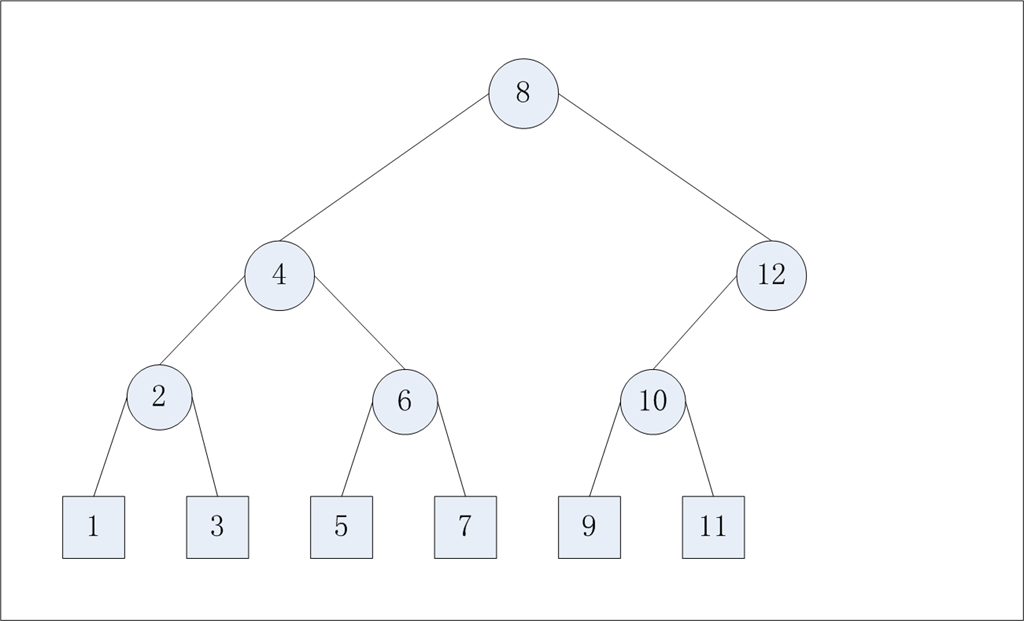
图2 不同Bucket的算法复杂度和数据迁移大小

结论
要根据存储系统中设备的情况和预期扩展计划来选择不同的bucket。















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









