







一、先上代码
import java.util.List;
import org.apache.http.HttpHost;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.scheduler.QueueScheduler;
import us.codecraft.webmagic.scheduler.component.HashSetDuplicateRemover;
public class CSDNPageProcessor implements PageProcessor {
// 爬虫第一部分,基本配置
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setHttpProxy(new HttpHost("xxx.xxx.xx.xx", xxxx));
@Override
public void process(Page page) {
// 爬虫第二部分,抽取页面
// 如果不是文章的url地址,则浏览该页面下的文章列表的url,并加入TargetRequests中,爬取分页的url
if(!page.getUrl().regex("http://blog\\.csdn\\.net/liuchuanhong1/article/details.*").match()){
// 抓取文章的url地址
List<String> urls = page.getHtml().xpath("//div[@class='skin_list']").links().regex("http://blog\\.csdn\\.net/.*").all();
// 如果该页面下存在分页,则将分页的url主地址也加入目标请求中
List<String> url2 = page.getHtml().xpath("//div[@class='pagelist']").links().all();
url2.addAll(urls);
page.addTargetRequests(url2);
}else{// 否则,就说明该url是文章的url,则爬出该篇文章对应的具体信息
CSDNInfo info = new CSDNInfo();
String article = page.getHtml().xpath("//div[@class='skin_m']/div[@class='skin_center']/div[@class='skin_center_t']/div[@class='skin_list']/dl/dd/h3/a/text()").get();
info.setArticleName(article);
page.putField("csdnInfo", info);
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
// 爬虫第三部分,程序的启停以及输出,url去重,线程池大小设置等。
Spider.create(new CSDNPageProcessor()).addUrl("http://blog.csdn.net/liuchuanhong1").addPipeline(new CSDNPipeline()).scheduler(new QueueScheduler().setDuplicateRemover(new HashSetDuplicateRemover())).thread(10).run();
}
}二、说明
使用WebMagic爬虫,主要分为3个部分:
1、WebMagic的基本配置
可以进行的配置项如下:

2、抽取页面并保存
例如,我们需要将博客:下的所有文章列表的url都爬出来,用WebMagic如何来实现了?
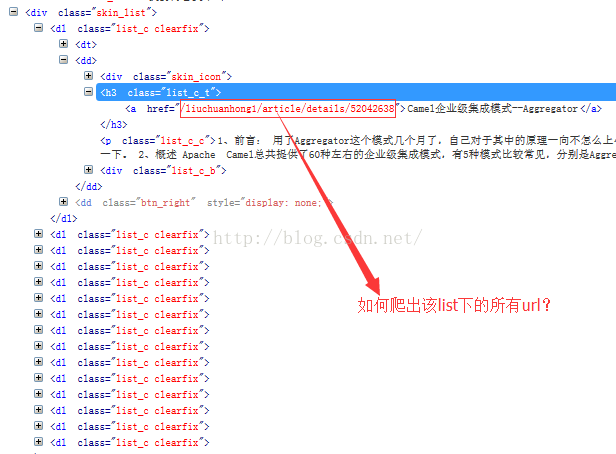
实现一:使用xpath
如下:
xpath("//div[@class='skin_list']").links().regex("http://blog\\.csdn\\.net/.*").all()上面这个xpath表示“skin_list”这个div下的所有链接,并进行正则匹配,过滤掉不符合条件的链接。
实现二:CSS选择器
如下:
page.getHtml().css("div.skin_list")实现三:正则表达式
如下:
page.getHtml().links().regex("http://blog\\.csdn\\.net/.*")这种方式是将HTML中的所有链接都爬出来,然后进行正则匹配,感觉这种方式没有上面两种方式好,目的性不是很强。
实现四:JsonPath
这种方式限于json格式的字符串。
有了上面集中方法,我们就可以很轻松的发现链接了。
3、程序的启停以及输出,url去重,线程池大小设置等
爬虫结果的输出
爬虫结果的输出是通过Pipeline来实现的,WebMagic内置了如下集中Pipeline:
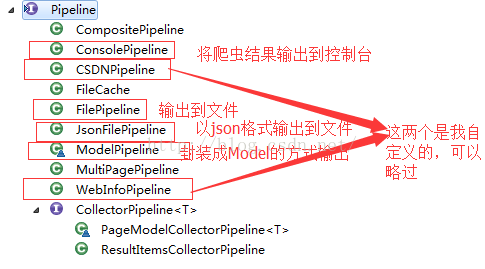
下面我们来自定义一个Pipeline,自定义Pipeline很简单,只需要实现Pipeline接口即可,代码如下:
import javax.annotation.Resource;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
public class CSDNPipeline implements Pipeline {
@Resource(name="csdnInfoDao")
private CSDNInfoDao dao;
@Override
public void process(ResultItems resultItems, Task task) {
// 此处可以存库,可以输出到Excel等介质
CSDNInfo infos = resultItems.get("csdnInfo");
System.out.println("article:"+infos.getArticleName());
dao.save(infos);
}
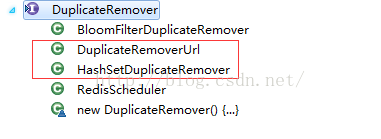
}Url去重
在我们爬虫的过程中,会发现加入TargetRequest的URL会重复,那么怎么将重复的URL删掉了,WebMagic已经为我们考虑好了。WebMagic通过Scheduler来实现,WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。如下:
三、爬虫结果
article:Hbase表设计总结
article:让HBase和Zookeeper分离开来单独执行
article:spring data hadoop操作hbase
article:redis sentinel部署(Windows下实现)
article:zookeeper集群环境搭建
article:Kafka环境搭建以及服务封装
article:spring整合redis sentinel实现redis HA服务调用
article:Camel企业级集成模式--Aggregator
article:Hbase中内置Filter详解
article:搭建HBase单机环境
article:Spring Bean的初始化和销毁方式详解
article:spring整合JMS之异步消息监听机制
article:Enterprise Architect多人协作方法
article:JMS消息类型
article:spring+ActiveMQ+JMS+线程池实现简单的分布式,多线程,多任务的异步任务处理系统
article:Jenkins集成Cucumber生成图形化的测试报告
article:Cucumber中涉及到的类型转换
article:java中callback回调机制解析
article:jersey+maven构建restful服务--入门篇
article:spring整合JMS一同步收发消息(基于ActiveMQ的实现)
article:使用线程池实现异步打日志和存库的任务调度
article:storm基础详解
article:java中的阻塞队列
article:Memcache详解
article:spring data jpa使用详解
article:Hibernate-validator校验框架
article:spring 静态AOP切第三方jar包
article:jdk自带线程池详解从上面的测试结果中可以看出,爬出了所有的文章,连分页的所有url都爬出来了。














 5521
5521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









