







基于密度算法的改进
本篇博客来自我的github小项目,如果对您有帮助,希望您前去点星 !
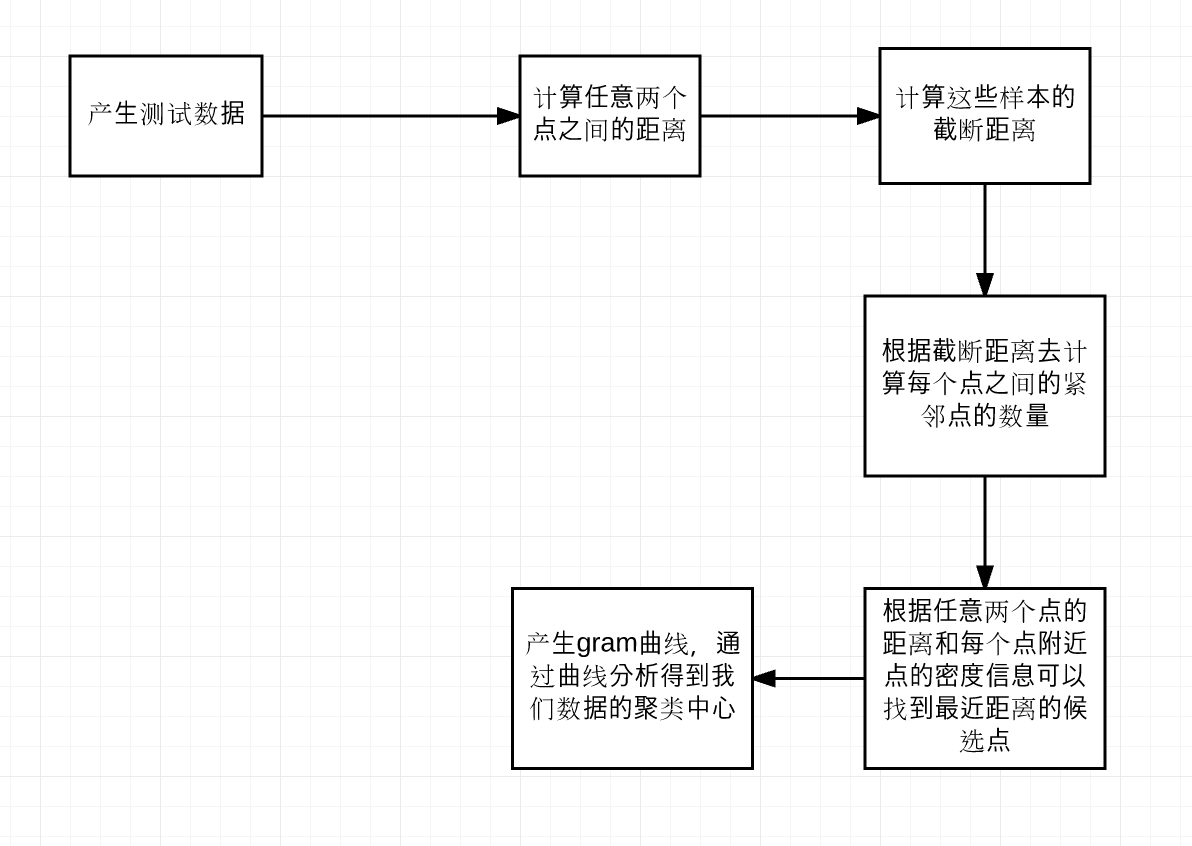
使用基于密度的聚类算法,进行高维特征的聚类分析,从高维数据中提取出类似的有用信息,从而简化了特征数量,并且去除了部分冗余信息。
在聚类算法中,有这样几种算法:
- 划分的算法, K-Means
- 层次的方法, CURE
- 基于密度的算法, DBSCAN,DPCA(Desity Peaks Clusering Algorithm)
- 基于网格的算法, CLIQUE
- 基于模型的算法, 主要是一些概率的算法
由Alex Rodriguez和Alessandro Laio发表的《Clustering by fast search and find of density peaks》的主要思想是寻找被低密度区域分离的高密度区域。
基于这样的一种假设:
对于一个数据集,聚类中心被一些低局部密度的数据点包围,而且这些低局部密度的点距离其他有高局部密度的点的距离都比较大。
如何定义局部密度?
找到与某个数据点之间的距离小于截断距离的数据点的数量
如何寻找与高密度之间的距离?
- 找到所有比第i个数据点局部密度都打的数据点中,与第i个数据点之间的距离最小的值;
- 而对于有最大密度的数据点,通常取 σi=maxj(dij) ;
如何确定聚类中心、外点?
- DPCA中将那些具有较大距离 σi ,且同时具有较大局部密度的 ρi 的点定义为聚类中心。
- 同时具有较高的距离,但是密度却较小的数据点称为异常点。
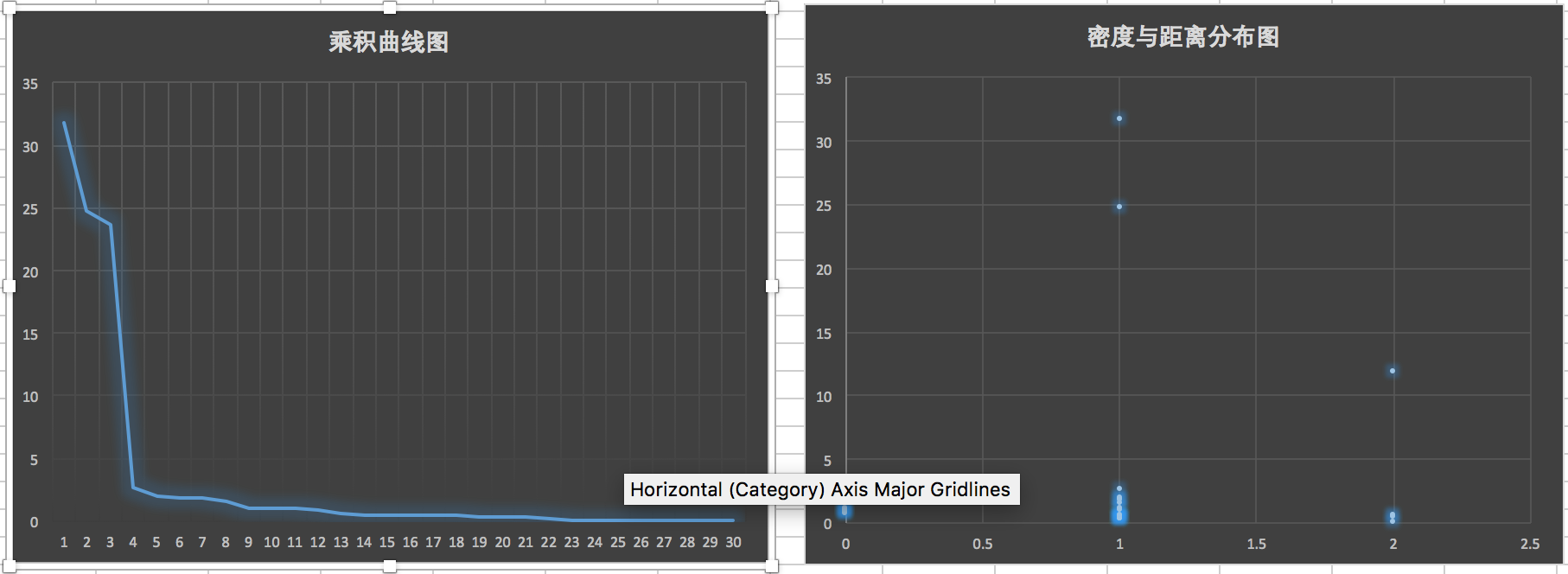
- 根据论文中的决策图和乘积曲线去寻找潜在的聚类中心
- 一条线中,去掉为零的部分,然后取出指定的前百分之几的数据即可
- 将数据按照层次聚类,将曲线分层,找到可能的聚类中心
Requirements
- g++-4.7以上版本
- 内存最好够大,因为至少要存储任意两个向量之间的距离
- 使用libopm进行算法的并行化,提高运行效率
程序运行展示
### 测试数据的分布 - 样本数据的展示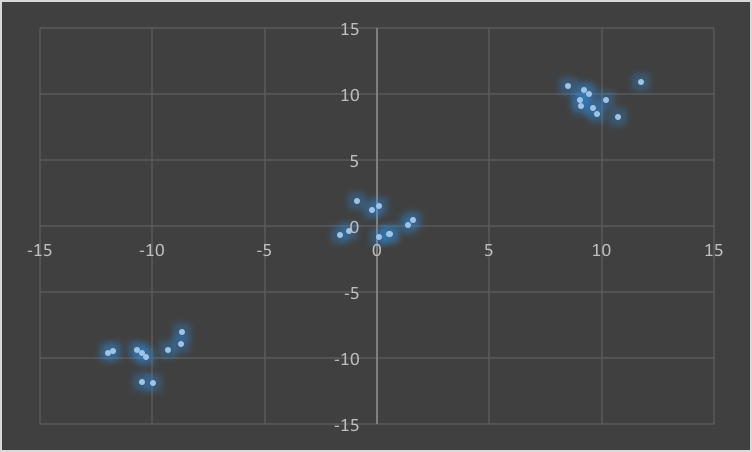
- 按照论文中的方法去寻找聚类中心














 4855
4855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









