







前言
对于深度学习,新手我推荐先看UFLDL,不做assignment的话,一两个晚上就可以看完。毕竟卷积、池化啥的并不是什么特别玄的东西。课程简明扼要,一针见血,把最基础、最重要的点都点出来 了。
cs231n这个是一个完整的课程,内容就多了点,虽然说课程是computer vision的,但80%还是深度学习的内容。图像的工作暂时用不上,我就先略过了。
突然发现这两个课程都是斯坦福的,牛校就是牛。
- 课程主页 http://vision.stanford.edu/teaching/cs231n/syllabus.html
- 百度云的视频存档&课件。youtube的视频被举报下架了,不知为毛。 http://pan.baidu.com/s/1pKsTivp
lecture 1
历史课,吹吹水,当作练听力,跳过问题也不大。华裔语速还是慢,后面lecture2别人讲的时候语速快得一下子懵逼了。
貌似是Fei-Fei Li唯一一次出现。不过人家确实是大牛,所以名字还是排在ppt前面。
lecture 2-4
机器学习的复习。当练听力好了。我以前写过一篇博客,可以对照看看:[kaggle实战] Digit Recognizer – 从KNN,LR,SVM,RF到深度学习。
- KNN对比较复杂的图像,增大k应该是有效的。
-
svm这个hinge loss应该看明白吧 Li=∑i≠yimax(0,sj−syi+1) 不明白的自己回去复习svm了。
-
计算拆解到activation gate,back propagation物理解释。以前就觉得是个链式求导没啥特别。
-
下面这个图不错, mark一下。

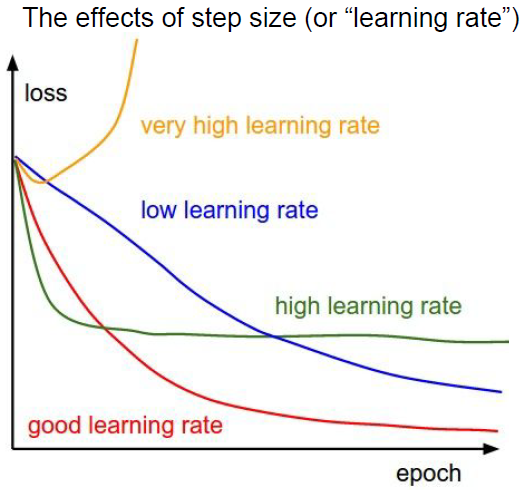
这几节课,复习之余,主要还可以gain some image intuition
lecture 5
- 提醒可以利用pre training好的模型,比如Caffe Model Zoo的。再finetune自己的own data。看了下,貌似都是图像的。估计其他的太domain specific了。毕竟图像问题挺棘手的,目前深度学习确实带来不少突破,其他领域要用深度学习的话,感觉有点玄。

activation functions
以前看keras的文档提到ReLu,还以为很复杂,其实式子很简单,简单就是好啊。
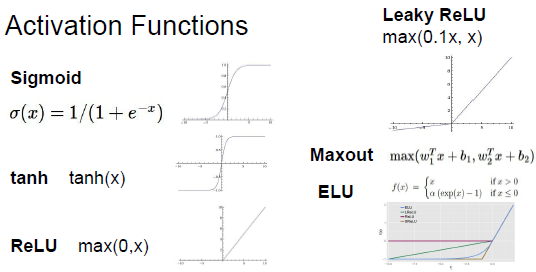
重要的是理解背后的原因
* sigmoid sigmoid各种不好,然后就开始改进了。


TLDR是too long; doesn’t read
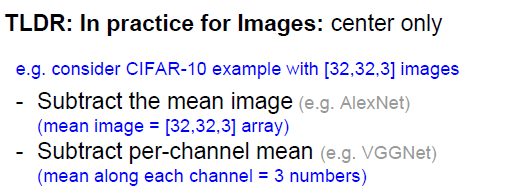
Data Preprocessing
UFLDL里面的zca白化啥的。
weight Initialization
- 就是告诉你一个结论,weight没初始化好的话,会影响后面的training。导致train出来的weight分布很不好。
- 根据对称性,初始化的时候如果weight不随机那训练出来的weight就都一毛一样了。
- bias倒是直接0就可以了。
用的时候倒是直接用现成的结论就好。但如果你要搞特殊的activation function,那就得注意初始化的问题了。

relu的除以2
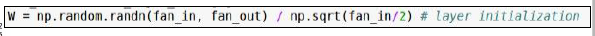
Batch Normalization
刚开始还不太明白跟preprocessing的区别,好像就是分batch做而已。听课听着听着也走神了。

看了assignment才知道,这个是插入在网络中间的layer。
However even if we preprocess the input data, the activations at deeper layers of the network will likely no longer be decorrelated and will no longer have zero mean or unit variance since they are output from earlier layers in the network. Even worse, during the training process the distribution of features at each layer of the network will shift as the weights of each layer are updated.
……
To overcome this problem, [3] proposes to insert batch normalization layers into the network.
总之,是一个有点偏工程实现的优化,貌似还挺有用。2015,挺新的,所以UFLDL没有。
summary

http://lossfunctions.tumblr.com 居然有这个网站,有空可以去看看。loss算是模型直观可视化的一个重要部分。
lecture 6
前几页是复习的,可以mark一下。
貌似因为DL的loss是高度非凸,所以需要下面这些优化。LR啥的没听说过要用adam啥的。估计sgd就很好了。
- sgd最慢
- momentum 动量,通俗一点貌似就是惯性的意思?
-
Nesterov Momentum “lookahead” gradient, 就是先用更新后的位置的梯度。代码实现的时候稍微变形了下。
-
adaGrad 梯度大的抑制一下步长。
-
RMSProp优化上面的
-
Adam: momentum + RMSProp
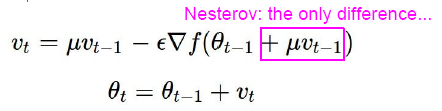

L-BFLS好像是LR用的吧。
L-BFGS does not transfer very well to mini-batch setting.
上代码
Regularization: Dropout
2014,也是挺新的。注意效果是regularization。
- Forces the network to have a redundant representation。简直就是为图像设计的,因为物体换不同角度,或者只出现局部啥的,并不影响人类识别物体。
- test的时候可以多次dropout采样求平均。 Monte Carlo approximation: do many forward passes with different dropout masks, average all redictions;或者直接不dropout,那就注意数值要scaling一下,不然值肯定比原来drop的时候偏大啊。一般选不dropout吧,练习里用这种。
lecture 7
- cnn时候的stride,padding等概念。挺简单,但肯定要弄清楚,调参侠调参肯定碰到。
- 多层conv之后,一个点能看到的原始图像范围会变大,所以conv有点像在层层抽象特征,从点到线到面的感觉。conv图像上是解释得通,其他领域就不知道了。当然这门课就是图像的。
- pooling直观上看数据会被降维。当然对于图像,冗余信息很多。看到的max pooling居多,average pooling其实就是图像尺寸的缩放,大图生成缩略图。所以pooling在图像上也是有物理含义的。
- relu之前在另外地方看到,可以用区分信号、噪声来解释。
有没感觉到,DL简直就是为图像问题定制的?

最后截个图。smaller filter对计算有利,后面有课程讲到。
lecture 8
图像相关的。先略吧。Fast R-CNN,Faster R-CNN啥的,名字这么屌。YOLO最快,后面有时间直接玩玩这个吧。
lecture 9
告诉你怎么可视化和fool CNN。剩下一些图像的东西。DeepDream啥的。
lecture 10
RNN(Recurrent Neural Networks,不会翻译的就直接用英文吧,貌似有人翻译错了),LSTM(Long short term memory)。也没有很神的东西,就是改变一下网络结构。所以不要害怕。可以看看 min-char-rnn 的代码作为切入点。
RNN
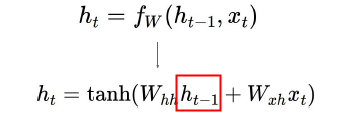
其实就是多加上h(t-1)这玩意,activation function用的是tanh,不知为毛。
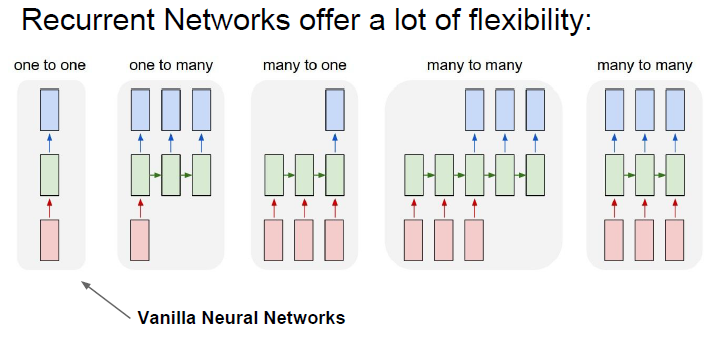
RNN有多种结构,最简单是Vanilla RNN。assignment就用这种。
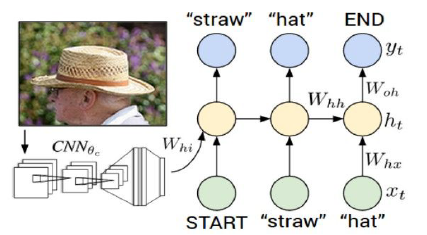
Image Captioning 这个例子挺有意思的,就是通过CNN提取图像特征h0给RNN,然后RNN的输入就是一串word id,中间传递的h(t)就是夹杂图像feature和word id的东西。很难想象这样居然work。细节自己做assignment吧。
LSTM
感觉讲得不怎么好,不如看这篇http://colah.github.io/posts/2015-08-Understanding-LSTMs/, 现在google LSTM,这篇已经排第一了,果然群众的眼睛是雪亮的。
lecture 12
- 学习caffe、theano、lasagne、keras等的读音。
- 每个库的pros / cons总结。不过最好还是得自己动动手,才能加深理解。先简单过一遍把,实践过后再来仔细看看第二遍,有些事情你没经历过不会明白的。

Assignment
年纪大了,挑了一些做,没完全做完。
assignment 1
年纪大了,原本不想做。但是得熟悉一下numpy,不然后面assignment的有点吃力。熟悉octave的话,也不会太吃力。
- knn让你感受一下vectorized方式代码速度快多少。因为可以底层代码可以针对矩阵计算专门优化。
- linear_svm的vectorized实现费了不少脑子。直接从naive实现去推,或者自己画了个矩阵的示意图推吧,一步步来也不难,空想有点绕的。Hinge loss 是一个凸函数,不过它有些点不可微的,只是有subgradient。之前学svm都是用对偶、smo啥的来解,为什么?(这里有篇Quora大概意思就是说能方便使用kernel,处理原始线性不可分的情况,优化的参数少了,跟数据维度无关了)。 sgd并不stable,多跑几次结果可能不一样。这里已经开始灌输调参侠的思想了,挺好。
- linear_classifiers random choice的时候忘记X和y要用同一个采样下标啊。坑爹。
- softmax的score居然不用exp再normalize,害我查半天。现在脑子转得快,直接用vectorized方式实现了。naive方式反而觉得得翻译回去,年纪大就不写了,代码里直接调用vectorized方式的。
- two_layer_net 调参调参
- features 图像相关,HOG和color histogram都帮你写好了。其他领域看看提取特征方面有没可以借鉴的,color histogram就是一种统计特征。HOG看上去也是统计类的特征,统计各方向的梯度得到边缘,没细看,大概是这样吧。HOG=Histogram of oriented gradient,哦,最后才反应过来看英文全称就好。
注意除法的时候,int可能需要转成float。忘记在哪碰到过了。
assignment 2
虽然看内容没啥意思,原本也不想做。但其实是帮你熟悉modular approach,对后面看caffe、torch等源码还是有帮助的。assignment设计得还是很高明啊。relu虽然可以看做layer上的activation function,但实现的时候当作layer统一处理更方便。之前看keras例子的时候就有点困惑,不知道为啥代码里FC跟activation function分开了。这样代码看上去并不是我想象中的一层层。之前在UFLDL里都是FC+sigmoid作一个layer。
notebook里面帮你写好“单元测试”了,挺好的,这样每一步都有checkpoint知道自己对了没。
numpy默认是传引用,记得用xx.copy()方法返回深拷贝。
assignment 3
传送一个tanh导数
- rnn_layers.py h(t)在BP的时候除了自己节点输出,t+1节点也有gradient传递过来的。说多了都是泪,查半天。
小结
基本把课程学完了,感觉课程设计得相当赞,内容也很新。把相应的知识都整理到一起,免得自己零零散散地找论文、找资料,还是推荐大家都系统地学一下比较好。课程的Materials也很棒,不要忘记看。编程的assignment就更不用说了,老老实实做下去确实能学到不少东西,加深课程的理解。讲师karpathy我挺喜欢的,可以上他的博客去看看 http://karpathy.github.io/。深度学习还有另外一门cs224d,是关于nlp的 ,感觉现在深度学习就是图像和nlp比较合适。公司现在为了DL而DL,我也不知能搞出什么东西。
转载:http://blog.csdn.net/dinosoft/article/details/51813615














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









