







本文总结与<machine learning in action>一书
一. Logistic回归简介
1. 回归:
假设现在有一些数据点,我们用一条直线对这些点进行拟合(最佳拟合直线),这个拟合过程成为回归。“回归”一
词源于最佳拟合,表示要找到最佳拟合参数值。
2. Logistic回归的思想
根据现有数据对分类边界线建立回归公式,以此进行分类。
3. Logistic回归的一般过程
(1) 收集数据:采用任意方法收集数据。
(2) 准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳。
(3) 分析数据:采用任意方法对数据进行分析。
(4) 训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
(5) 测试算法:一旦训练步骤完成,分类将会很快。
(6) 使用算法:首先,我们需要输入一些数据,并将其转换成相应的结构化数值;接着,基于训练好的回归系数
就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他
分析工作。
4. Logistic回归的优缺点
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类性能可能不高。
适应数据类型:数值型和标称型数据。
二. 分类函数选择
我们应该选择的函数能接受所有的输入然后预测出类别。在两类情况下,上述函数应该输出0或1.
1. 海维塞德阶跃函数(Heaviside step function):也成为单位阶跃函数。其问题在于函数在跳跃点上从0瞬间跳跃到
1,这个瞬间跳跃过程往往很难处理。因此,我们采用与之有类似功能的函数——Sigmoid函数。
2. Sigmoid函数:
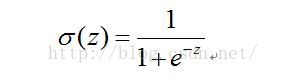
因此,为了实现Logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把所有结果值相加,将这
个总和代入Sigmoid函数,进而得到一个范围在0-1之间的数值。任何大于0.5的数据被分入1类,小于0.5则被分入0
类。Logistic回归可以看成是一种概率估计。因此,这个确定这个最佳回归系数成为关键。
3. Sigmoid函数的输入:
sigmoid函数的输入是特征向量的线性加权,即回归系数与特征值的向量内积。由于分界面方程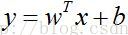
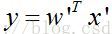

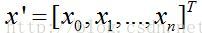
,这实际上在特征值上增加了一维数据。则Sigmoid输入值为:
z为一个标量数值。然后带入Sigmoid的函数,即可得到相应的分类值,并与实际的类别标签进行对比,计算出分类误
差值。然后根据最优化方法(如梯度上升法、随机梯度上升法)对回归系数进行更新。另外,最佳的回归系数对应的最
佳分界面(二维空间为分界线)为: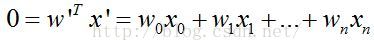
三. 梯度上升法
对于回归系数,一般采用梯度上升法进行更新,其思想是:要找到某函数的最大值,最好的方法是沿着该函数的梯
度方法进行探寻。梯度下降法的思想正好和其相反,沿着负梯度方向进行搜索。
梯度上升法的伪代码如下:
-----------------------------------------------------------------------------------
每个回归系数初始化为1
重复R次: # 这个R根据实际情况自己设置
计算整个数据集的梯度
使用alpha x gradient更新回归系数的向量
返回回归系数
----------------------------------------------------------------------------------
四. 随机梯度上升算法
由于梯度上升算法在每次更新回归系数时都需要遍历整个数据集,对于小数据集该算法是理想的,但是对于大数
据集,显然算法的时间复杂度过高,难以实现。一种改进的方法是一次仅用一个样本点来更新回归系数,该方法称为
随机梯度上升算法。由于每次新样本的到来都可以对分类器进行增量式更新,因此该算法也称为在线学习算法。与"在
线学习算法"相对应的,一次处理所有数据的方法被称为批处理。
算法的伪代码:
----------------------------------------------------------
所有回归系数初始化为1
对样本集中每个样本
计算该样本的梯度
使用alpha x gradient更新回归系数值
返回回归系数值
----------------------------------------------------------
五. 改进的随机梯度上升算法
主要从以下三个方面下手:
(1) 在上述算法中增加一个迭代次数的设置,可设置默认值。
(2) alpha的动态改变,随着外层迭代次数增加以及内层数据的改变,对alpha动态的减小。alpha要设置一个常数
项,主要是为了保证多次迭代后新增数据仍然对回归系数产生一定影响。动态改变alpha的目的主要是为了缓解数据
的波动或者高频波动。
(3) 采用随机选择样本,而非之前按顺序选择样本。这样可以减少训练结果的周期性波动。
备注:上述的随机梯度上升算法相对于梯度上升算法的主要优势在于降低了时间复杂度。而改进的随机梯度法相对
于随机梯度法的基础上,缓解了其劣势(如训练结果的周期性波动),且使分类效果大大提高,可类比于梯度上升法。
六. 如何处理数据集中的数据缺失问题
数据中含有缺失值是个非常棘手的问题,很多文献都在致力于解决此类问题。由于数据的昂贵,我们对有损失或
损坏的数据直接扔掉往往是不可取的,可以采用以下方法进行处理:
(1) 使用可用特征的均值来填补缺失值;
(2) 使用特殊值来填补缺失值,如-1或0;
(3) 忽略有缺失值的样本;
(4) 使用相似样本的均值来填补缺失值;
(5) 使用另外的机器学习算法预测缺失值。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









