






前言:
今天在网上看到一条面试题,是关于常见排序算法和各自负杂度的,考虑到如果自己碰到这道题也未必能回答好,在这里对这方面知识巩固学习、整理了一下。
概述:
排序算法很多种,今天这里就几种常见的排序算法进行学习了解。
原理及实现:
一、插入排序:
(1)直接插入排序:
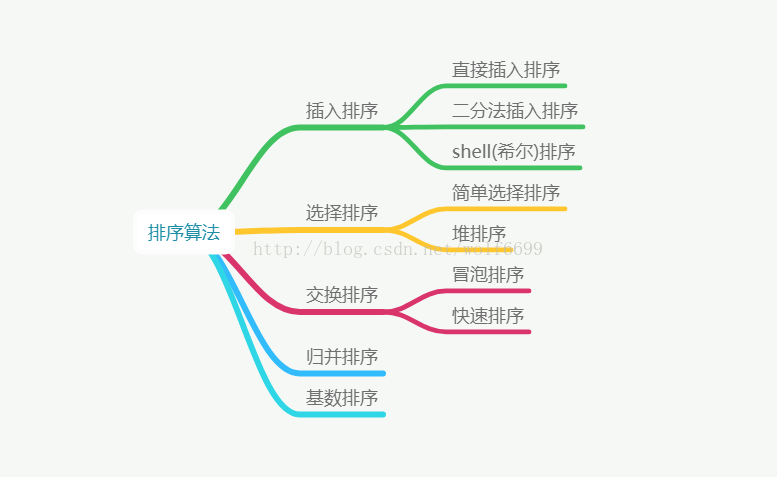
基本思想:有一个已经有序的数据序列,要在这个数据序列里面插入一个数据,并且要求插入后的数据序列增1且任然有序。即:我们把数据序列的第一个数看成是一个有序的数据序列,从第二个数开始,逐个添加到前面有序序列的合适位置,直到整个变成有序的序列为止。
要点:每次比较要取一个参照,作为临时存储判断数组的边界。
如下图,展示了插入排序的简易过程。
优点:稳定,快。如果碰到和待插入元素相等的,待插入元素插在后面,所以序列中相等的元素在排序前后的顺序没有改变,所以直接插入排序是稳定的。
缺点:比较次数不一定,比较次数越少,插入点后的数据移动越多,特别是当数据量庞大的时候。用链表可以解决这一问题。
具体实现:
static void directSort(int []array){
//打印初始数据
System.out.print("初始数据序列:");
for(int a:array){
System.out.print(a+" ");
}
System.out.println("");
//直接插入排序实现
for(int i = 1;i < array.length;i++){
int temp = array[i];//参照,也是我们的待插入元素
int j;
for(j = i - 1;j >= 0 && array[j] > temp;j--){
//将前面大的值向后移
array[j+1] = array[j];
}
array[j+1] = temp;//插入元素
//打印当前排序结果
System.out.print("第"+i+"次排序"+"(参照:"+temp+")"+":");
for(int a:array){
System.out.print(a+" ");
}
System.out.println("");
}
//打印最终数据序列
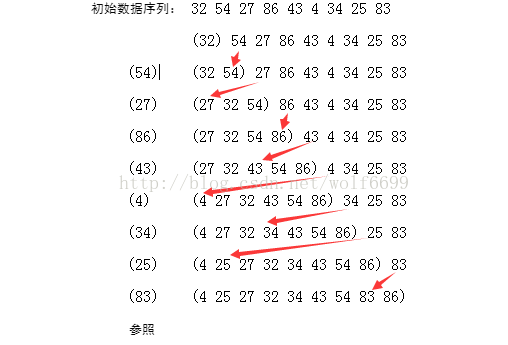
System.out.print("最终数据序列:");
for(int a:array){
System.out.print(" "+a);
}
}输出结果:
效率:
时间复杂度:
最坏情况:数据序列完全逆序,插入新的元素的时候,需要判断已有有序数据序列的全部数据。插入第二个元素的时候需要考察前一个元素,插入第三个元素的时候需要考察前两个元素,.....,插入第n个元素的时候,需要考察前n-1个元素,比较次数是1+2+3+.....+(n-1),等差数列求和,结果为n^2/2,所以最坏情况下的复杂度为O(n^2)。
最好情况:数据序列已经有序,每插入一个新的元素的时候,只要考察前面一个元素,所以复杂度为O(n)。
平均情况:O(n^2)。
空间复杂度:
需要的辅助空间大小是O(1)。
(2)二分法插入排序:
基本思路:二分法插入排序的基本思路和直接插入排序的基本思路是相同的,不同点在于寻找插入的位置,直接插入排序是用插入元素和已有有序序列的元素从后向前,一个个比较,找到合适位置。而二分法插入排序是用二分查找法来寻找插入的位置,用待插入元素和已有有序数据序列的中间元素进行比较,以有序序列的中间元素作为分界,确定待插入元素是在查找序列的左边还是右边,如果在左边,就以左边的序列作为查找序列,右边类似。递归处理新序列,直到当前查找序列的长度小于1结束。
如下图,取最后一个数据的判断来示例一下过程:
优点:稳定。
缺点:比较次数是固定的,和记录的初始顺序无关,在最坏情况下比直接插入排序快,最好情况下比直接插入排序慢。
具体实现:
static void Sort(int []array){
//二分法插入排序实现
int left = 0;//左边界
int right = array.length - 1;//右边界
int temp;//临时值
int low,high;//区间边界值
int middle;//中间值
for(int i = left + 1;i <= right;i++){
temp = array[i];
low = left;
high = i - 1;
//二分法判断插入位置
while(low <= high){
middle = (low + high)/2;
if(array[i] >= array[middle]){
low = middle + 1;
}else{
high = middle - 1;
}
}
//移动数据,插入元素
for(int j = i - 1;j >= low;j--){
array[j+1] = array[j];
}
array[low] = temp;
}
}效率:
时间复杂度:
适合用于数据较多的场景,与直接插入排序相比,在寻找插入位置上花的时间减少,但是数据移动的次数一样;比较次数 和初始数据序列顺序无关,查找插入位置的次数是一定的,所以比较的次数也是一定的,时间复杂度为O(n^2)。
空间复杂度:
需要的辅助空间大小是O(1)。
(3)shell(希尔)排序:
基本思路:在直接排序的基础上做了很大的改进,又被称作缩小增量排序。将待排序的数据序列按特定增量划分成若干个子序列,对各个子序列进行插入排序;然后再选择一个更小的增量,再将数据序列划分成若干个子序列进行排序........最后增量为1,即使用直接插入排序,使最终数据序列有序。
要点:取增量,n是数据序列里面数据的个数,增量的序列{n/2,n/4,n/8 ...... ,1}。
如下图,展示取增量、划分子序列判断的过程:

优点:快、数据移动少。
缺点:不稳定、增量d的取值是多少,应该取多少个不同的值都无法确定。
具体实现:
static void sort(int[] array) {
// 打印初始数据
System.out.print("初始数据序列:");
for (int a : array) {
System.out.print(a + " ");
}
System.out.println("");
// 希尔排序
int d = array.length;//初始增量
while(true){
d = d / 2;
for(int i = 0;i < d;i ++){//按增量划分子序列
for(int j = i + d;j < array.length;j = j + d){//遍历子序列
int temp = array[j];//直接插入排序的参照值
int k;
for(k = j - d;k >= 0 && array[k] > temp;k = k - d){//直接插入排序,后移数据
array[k + d] = array[k];
}
//插入数据,后移一位游标到最后一次比较的位置插入
array[k+d] = temp;
}
}
//打印log
System.out.print("增量:"+d);
System.out.print("。结果:");
for (int a : array) {
System.out.print(a + " ");
}
System.out.println("");
//跳出循环
if(d == 1){
break;
}
}
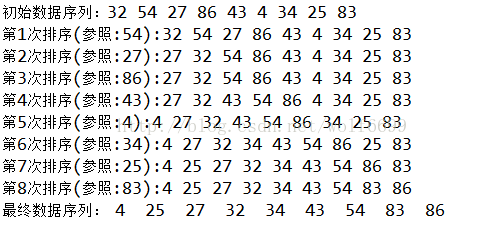
// 打印最终数据序列
System.out.print("最终数据序列:");
for (int a : array) {
System.out.print(" " + a);
}
}时间复杂度:
最坏情况:O(n^2)。
最好情况:O(nlogn)。
平均:O(nlogn)。
空间复杂度:
需要的辅助空间大小是O(1)。
既然说到了希尔排序是直接排序的升级版,那么说一下相对于直接排序的优点在哪:
①待排序数组初始状态基本有序的时候,直接插入排序的比较和插入的次数相对比较少;
②当待排序数组的长度n不大的时候,n和n^2相差不大,即直接插入排序的时间复杂度最好情况O(n)和最坏情况O(n^2)差别不大;
③增量排序初始的时候,增量的值比较大,分的组比较少,每组的数据也比较少,所以每组直接插入排序较快;随着增量的逐渐减小,分的组越来越多,每组的数据也越多,但是由于之前的各个分组的排序,使现有的各组顺序比较接近有序的状态,所以,新的排序也会比较快。
二、选择排序
(1)简单选择排序:
基本思路:在待排序的数组中,遍历找出最小的一个数和第一个位置的数交换,然后再在剩下的数中找出最小的和第二个位置的交换,依次类推,直到对比玩倒数第二个和最后一个。
如下图所示,比较过程:

优点:移动数据的次数已知,n-1次。
缺点:不稳定,比较的次数多。
具体实现:
static void sort(int[] array) {
// 打印初始数据
System.out.print("初始数据序列:");
for (int a : array) {
System.out.print(a + " ");
}
System.out.println("");
//简单选择排序
int position = 0;
for(int i = 0;i < array.length;i++){
int temp = array[i];
position = i;
int j;
for(j = i + 1;j < array.length;j++){
if(array[j] < temp){
temp = array[j];
position = j;
}
}
array[position] = array[i];
array[i] = temp;
//打印日志
System.out.print("第"+i+"位置排序:");
for (int a : array) {
System.out.print(" " + a);
}
System.out.println("");
}
// 打印最终数据序列
System.out.print("最终数据序列:");
for (int a : array) {
System.out.print(" " + a);
}
}时间复杂度:
最好情况:O(n^2)。
最坏情况:O(n^2)。
平均情况:O(n^2)。
空间复杂度:
需要的辅助空间大小是O(1)。
(2)堆排序:
基本思想:这里说的堆不是堆栈的堆,这里的堆是一种数据结构。堆排序是树形选择排序,是对简单选择排序的改进。堆可以视为完全二叉树,完全二叉树除了最底层之外,其他每一层都是满的,这里我们把要排序的数组表示成堆,堆的每一个节点对应数组的一个元素。一个二叉树,如果某个节点的值总是不小于其根节点的值,则根节点是所有节点中最小的,成为小顶堆;如果某个节点的值总是不大于其父节点的值,则根节点是所有节点中最大的,称为大顶堆。
说起来不好理解,下面通过图文展示下过程:
这里用的一组初始数组数据:32,54,27,86,43,4,34,25,83。
对应表示成二叉树形结构为:(对应红字为节点编号)
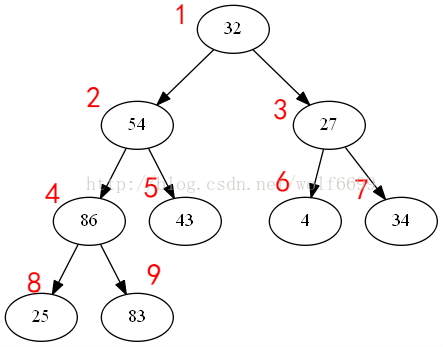
从编号可以看出一定的规律,如果节点的编号为i,那么他的左右两个子节点的编号分别为2*i,2*i+1。
据此退出数学定义:有n个元素的序列(k1,k2......kn),当且仅当满足(这里盗个图)
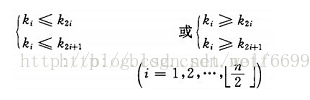
此时称之为堆,前者为小顶堆,后者为大顶堆。
注意:堆只对父子节点做了约束,并没有对兄弟节点做约束,兄弟节点不存在必然的大小关系。
下面来展示具体的比较步骤(这里以大顶堆来展示):
总的思路就是:数组表示成二叉树,二叉树调整成大顶堆,取出堆顶最大元素,堆最后一个元素移到堆顶,这是堆被破坏,重复调整堆,取元素的过程,直到全部有序。
①数组表示成二叉树
原始数组:32,54,27,86,43,4,34,25,83。
表示成二叉树:
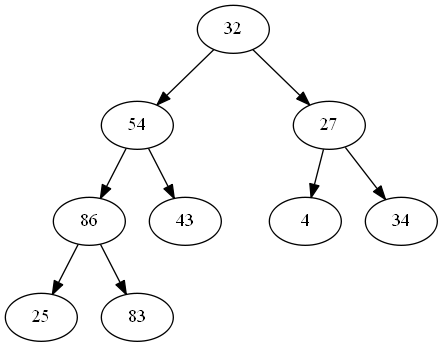
②调整成堆
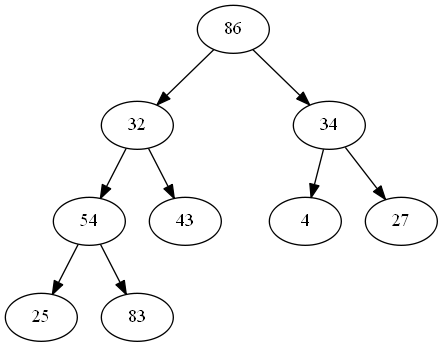
这里如何调整成堆是关键,按照上面的推导公式,我们可以拿到最后一个父节点编号n/2,父节点的范围是[1,2.....n/2]。从最后一个父节点开始分别和左右子节点比较,
把最大的值移动到父节点,直到比较到最顶上的根节点,这个时候可以把最大值移到顶上根节点,成大顶堆。
如图这里调整成大顶堆:
③取出顶端最大元素
大顶堆,顶端元素为最大值,和堆尾值互换,然后取出最大值,如图:
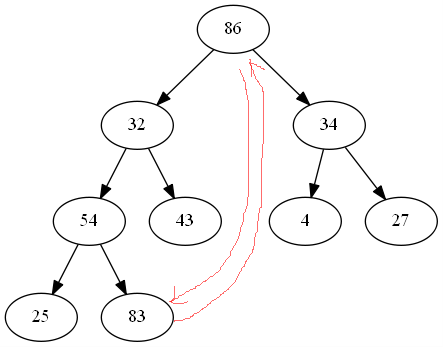
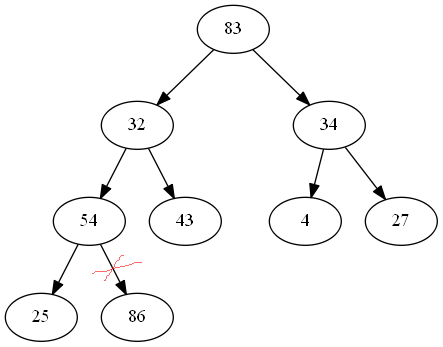
最大值换到最后一个,然后把最大值取走,取出的元素放入序列尾,将剩下的n-1各元素重新调整成堆,循环此操作,直到有序。(这里我的示例数据取得有点尴尬,正好剩下的n-1个元素的最大值在堆尾,被换后还是个堆-_-||。纯属巧合,
这个时候是需要对剩下的n-1个元素重新调整成堆的)。
可能写的不是很好理解,可以参考这几篇文章,写的比较详细(点击打开链接,点击打开链接,点击打开链接)。
优点:平均时间上,堆排序的时间常数比快排要大一些,因此通常会慢一些,但是堆排序最差时间也是O(nlogn)的,这点比快排好。
缺点:不稳定。
具体实现:
public static void mergeSort(int []arr){
int lastIndex = arr.length - 1;
while(lastIndex > 0){
ajustHeap(arr,lastIndex);//创建大顶堆
lastIndex --;
}
}
/**
* 建堆
* @param arr
* @param n
*/
private static void ajustHeap(int []arr,int n){
int index = (n-1) / 2;
int lagestIndex;
for(int i = index;i >= 0;i--){
lagestIndex = i;//记录最大值的下标
//判断是否存在右子节点
if(2*i + 2 <= n){//存在,右子节点存在,左子节点必然存在
if(arr[2*i+1] >= arr[i]){//如果左子节点大于等于父节点
lagestIndex = 2*i+1;
}
if(arr[2*i+2] >= arr[i] && arr[2*i+2] >= arr[2*i+1]){//如果右子节点大于等于父节点,并且右子节点大于等于左子节点
lagestIndex = 2*i+2;
}
}else{
//右子节点不存在
if(arr[2*i+1] >= arr[i]){
lagestIndex = 2*i+1;
}
}
//每个子堆比较完了,将最大的移到父节点
if(i != lagestIndex){
swap(arr,lagestIndex,i);
}
}
//堆顶最大的元素和堆尾的交换
swap(arr,0,n);
}
/**
* 元素交换
* @param arr
* @param lagestIndex
* @param lastIndex
*/
private static void swap(int []arr,int lagestIndex,int lastIndex){
int temp = arr[lagestIndex];
arr[lagestIndex] = arr[lastIndex];
arr[lastIndex] = temp;
}时间复杂度:
由于堆排序对原始记录的状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlogn)。
最好情况:O(nlogn)。
最坏情况:O(nlogn)。
平均情况:O(nlogn)。
空间复杂度:
需要辅助空间O(1)。
三、交换排序
(1)冒泡排序:
基本思路:依次比较待排序数组的相邻两个数,依据排序要求,如果他们的顺序错误,就交换位置;重复遍历数组,直到有序。
如下图所示,比较过程:

优点:稳定。
缺点:慢,每次只移动相邻数据。
具体实现:
static void sort(int[] array) {
// 打印初始数据
System.out.print("初始数据序列:");
for (int a : array) {
System.out.print(a + " ");
}
System.out.println("");
//冒泡排序
int temp;
for(int i = array.length - 1;i > 0;i--){
for(int j = 0;j < i;j++){
if(array[j+1] < array[j]){
temp = array[j+1];
array[j+1] = array[j];
array[j] = temp;
}
}
}
// 打印最终数据序列
System.out.print("最终数据序列:");
for (int a : array) {
System.out.print(" " + a);
}
}时间复杂度:
最好情况:O(n)。
最坏情况:O(n^2)。
平均情况:O(n^2)。
空间复杂度:
辅助空间O(1)。
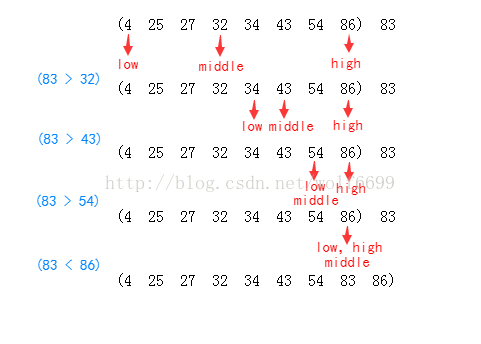
(2)快速排序:
基本思路:通过一趟排序将要排序的数组分割成两个独立部分,其中一部分的所有数据都要比另一部分小,然后再按此方法分别对两部分进行快速排序,依次类推,整个过程递归进行,以达到整个数组有序。
如下图,下面以一轮比较的过程来展示:
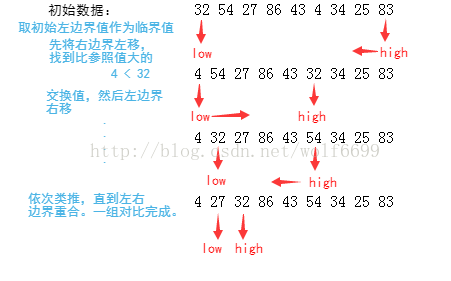
优点:极快,数据移动少。
缺点:不稳定。
具体实现:
static void sort(int arr[], int left, int right) {
int low = left;
int high = right;
int temp = arr[left];
while(low < high){
while(low < high && arr[high] >= temp){
high --;
}
if(low < high){
int tem = arr[low];
arr[low] = arr[high];
arr[high] = tem;
}
while(low < high && arr[low] <= temp){
low ++;
}
if(low < high){
int tem = arr[low];
arr[low] = arr[high];
arr[high] = tem;
}
}
if(left < low){
sort(arr,left,low-1);
}
if(high < right){
sort(arr,high+1,right);
}
}效率:
时间复杂度:
最好情况:O(nlogn)。
最坏情况:O(n^2)。
平均情况:O(nlogn)。
空间复杂度:O(nlogn)~O(n^2)。
四、归并排序
基本思路:归并排序是建立在归并操作基础上的有效排序算法。该算法是采用分治法,将两个已有有序的子序列合并成一个大的有序的序列,通过递归,层层合并。
要点:首先要将一个数组拆分成A和B两个子数组,然后再分别对两个子数组再各自拆分出两个子数组,依次递归拆分,直到每个子数组的元素只有一个,可以视为这些子数组都各自有序;然后再按从小到大的顺序逆向层层合并,最后就可以得到一个有序的数组。
如图,展示过程:
优点:稳定。
缺点:空间复杂度为O(n),在数据量较大的时候让人难以接受,考虑到机器本身内存小,慎用。
具体实现:
/**
* <pre>
* 二路归并
* 原理:将两个有序表合并和一个有序表
* </pre>
* @param a
* @param temp
* @param left
* 第一个有序表的起始下标
* @param middle
* 第二个有序表的起始下标
* @param right
* 第二个有序表的结束小标
*
*/
private static void merge(int[] a,int [] temp, int left, int middle, int right) {
int i = left;
int j = middle;
int k = 0;
while(i < middle && j <= right){
if(a[i] <= a[j]){
temp[k] = a[i];
k++;
i++;
}else{
temp[k] = a[j];
k++;
j++;
}
}
while(i < middle){
temp[k] = a[i];
k++;
i++;
}
while(j <= right){
temp[k] = a[j];
k++;
j++;
}
//插入到原数组
for(int index = 0;index < k;index++){
a[left+index] = temp[index];
}
} /**
*递归拆分
*/
public static void mergeSort(int[] a,int [] temp, int left, int right) {
//当left = right时,长度为1,终止
if(left < right){
int middle = (right + left)/2;
mergeSort(a, temp, left, middle);//左子数组
mergeSort(a, temp, middle+1, right);//右子数组
merge(a,temp, left, middle+1, right);//合并数组
}
}时间复杂度:
归并排序的效率是很高的,由于递归划分为子序列只需要logn复杂度,而合并每两个子序列需要大约2n次赋值,为O(n)复杂度,因此,只需要简单相乘即可得到归并排序的时间复杂度 O(㏒n)。并且由于归并算法是固定的,不受输入数据影响,所以它在最好、最坏、平均情况下表现几乎相同,均为O(n㏒n)。
最好情况:O(nlogn)。
最坏情况:O(nlogn)。
平均情况:O(nlogn)。
空间复杂度:O(n)。(归并排序最大的缺陷在于其空间复杂度。在合并子数组的时候需要一个辅助数组,然后再把这个数据拷贝回原数组。所以,归并排序的空间复杂度(额外空间)为O(n)。而且如果取消辅助数组而又要保证原来的数组中数据不被覆盖,那就必须要在数组中花费大量时间来移动数据。不仅容易出错,还降低了效率。因此这个辅助空间是少不掉的。)
五、基数排序
基本思路:属于“分配式排序”,又称“桶子法”,透过键值的部分资讯,将要排序的元素分配到某些“桶”中,以达到排序的作用。实现思路是,将所有待比较的值(正整数)统一为同样的数位长度,数位较短的数前面补0,然后从最低位开始,依次进行依次排序,这样从最低位排序一直到最高位排序完成以后,数组就变成有序的数组。(两种排序方式,LSD(Least significant digital)和MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD相反。)。
如图,展示比较过程:

优点:稳定。
缺点:关键字可分解;记录的关键字位数较少,如果密集更好;如果是数字时,最好是无符号的,否则将增加相应的映射复杂度,可先将其正负分开排序。
具体实现:
/**
*@param a 原数组
*@param max 数组中位数最长的元素的位数
*/
public static void mergeSort(int[] a,int max) {
int k = 0;
int n = 1;//计算键值排序依据
int m = 1;//控制键值排序依据是哪一位
int [][] temp = new int[10][a.length];//多维数组,左边10行作为“桶子”,右边插入数据
int [] orderIndex = new int[10];//记录每个“桶子”有多少个值
while(m <= max){//从各位开始判断
for(int i = 0;i < a.length;i++){//分到每个桶子
int lsd = (a[i]/n) % 10;
temp[lsd][orderIndex[lsd]] = a[i];
orderIndex[lsd]++;
}
for(int i = 0;i < 10;i++){//合并
if(orderIndex[i] != 0){
for(int j = 0;j < orderIndex[i];j++){
a[k] = temp[i][j];
k++;
}
orderIndex[i] = 0;
}
}
k = 0;
m++;
n = n*10;
}
}时间复杂度:
分配的时间复杂度为O(n),收集的的时间复杂度为O(r),分配和收集共需要d趟,所以基数排序的时间复杂度为O(d(n+r))。
最好情况:O(d(n+r))。
最坏情况:O(d(n+r))。
平均情况:O(d(n+r))。
空间复杂度:分配元素时,使用的桶空间;所以空间复杂度为:O(10 × n)= O(n)。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









