







http://blog.csdn.net/ebay/article/details/52798074
作者:Jesse Meng
eBay自2014年末开始kubernetes的落地工作,并在2015年扩大研发投入。目前kubernetes已经部署在eBay的生产环境,并将作为下一代云计算平台。本文结合社区kubernetes的设计和实现,并结合OpenStack云基础架构,深入分析kubernetes服务部署的设计与实现。如果您在寻找服务发布的方案或者在寻找kubernetes服务相关的模块的原理或行为,阅读本文会让你有比较明确的方向。
总揽
Kubernetes架构
下图是kubernetes的架构图,当用户将应用从传统平台转移至kubernetes时,首当其冲的任务就是将应用容器话,并定义pod和replicaset(或者petsets,如果迁移的是有状态应用)来运行应用,kubernetes提供针对应用的PDMR(provision, deployment, monitoring, remediation)。通常来讲,kubernetes为pod分配的是私有ip。如果需要提供应用的跨集群访问,则需要通过Service以及Ingress来实现。
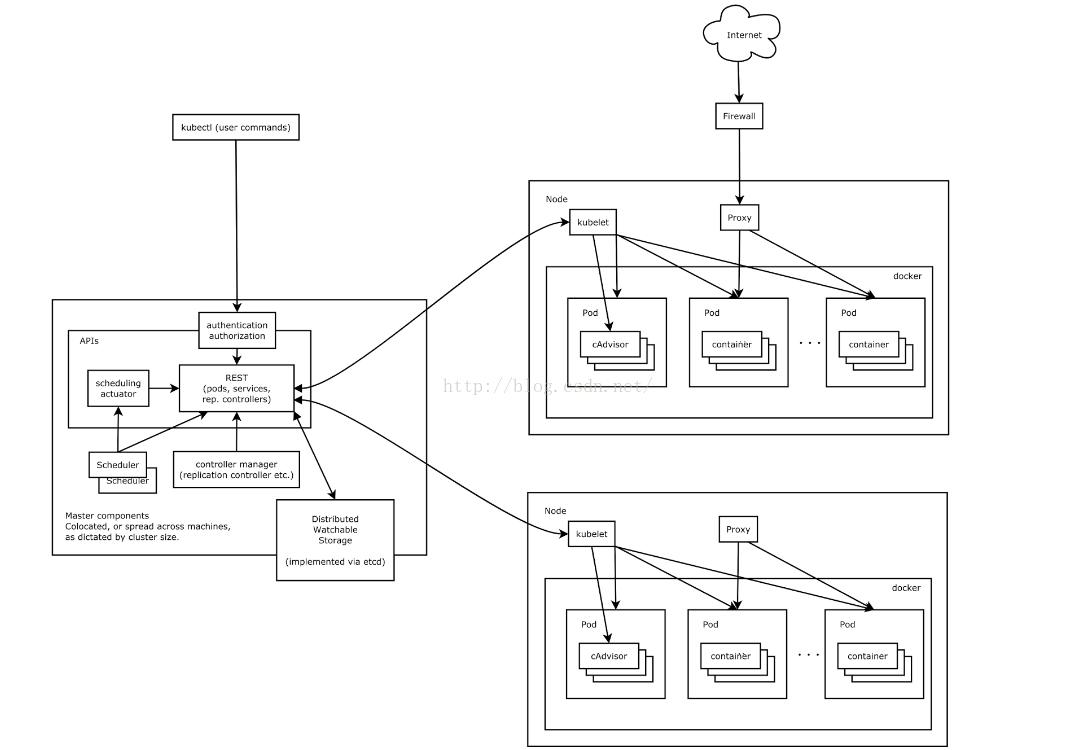
服务的发布
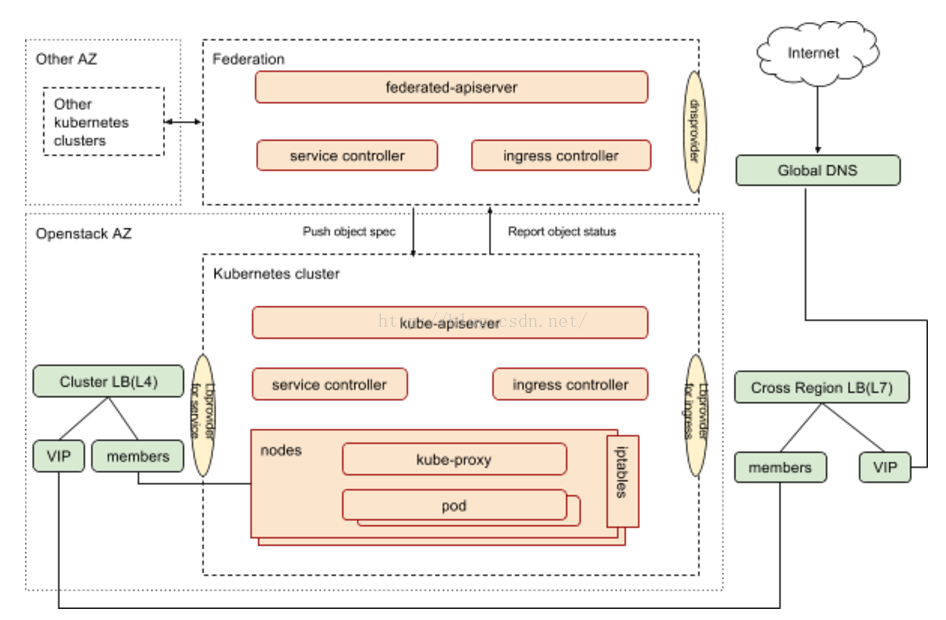
下图展示的是kubernetes 集群包括集群联邦中服务相关的组件以及组件之间的关系。
Federated-apiserver作为集群联邦推荐的面向用户的接口,接受用户请求,并根据联邦层面的调度器和控制器,将用户请求分裂/转发至kubernetes集群。
根据用户IaaS环境的不同,可能需要采用不同的provider来实现与外部组件的整合,目前这些定制化provider 包括:
-
DNS provider:社区实现包括 gce googledns,aws dns,eBay采用自己的GTM client
-
Load Balancer provider for service: 主流云平台都有自己的provider,eBay的Kubernetes部署在openstack之上,采用社区版本的openstack provider。
-
Load Balancer provider for ingress:社区目前有gclb和nginx两个版本的ingress controller,eBay与自己的内部load balancer management system(LBMS)对接,采用自己订制的基于LBMS client的ingress controller。
关于kubernetes的基本概念如pod, service等,网上有很多相关文章,可以参考kubernetes官网或网上的入门文章,本文不再一一赘述。本文希望针对kubernetes服务发布,进行end to end的分析,并针对特定云环境如eBay采用的openstack的具体实践。
服务发布
第一步:定义你的服务
eBay很多应用都采用微服务架构,这使得在大多数情况下,作为服务所有者,除了实现业务逻辑以外,还需要考虑如何把服务发布到kubernetes集群或者集群外部,使这些服务能够被kubernetes应用,其他kubernetes集群的应用以及外部应用使用。
这是一个业界的通用需求,因此kubernetes提供了灵活的服务发布方式,用户可以通过ServiceType来指定如何来发布服务。
-
ClusterIP: 此类型是默认的,这种类型的服务只能在集群内部访问。
-
NodePort: 此类型同时会分配clusterIP,并进一步在集群所有节点的同一端口上曝露服务,用户可以通过任意的 <NodeIP>:NodePort 访问服务。
-
LoadBalancer: 此类型同时会分配clusterIP,分配NodePort,并且通过cloud provider来实现LB设备的配制,并且在LB设备中配置中,将<NodeIP>:NodePort作为pool member,LB设备依据转发规则将流量转到节点的NodePort。
内部服务
ClusterIP
如果你的service只服务于cluster 内部,那么service type定义为ClusterIP就足够了。
Kube-proxy是运行在kubernetes 集群所有节点的组件,它的主要职责是实现服务的虚拟IP。
针对只面向集群内部的服务,我们建议用户使用ClusterIP作为服务类型,该类型比nodePort少占用节点端口,并比LoadBalancer类型减少对LB设备的访问,我们应该尽可能的避免不必要的LB设备的访问,因为任何外部依赖都有失败的可能性。
外部服务
NodePort
针对类型是”NodePort”的服务,kubernetes master会从与定义的端口范围内请求一个端口号(默认范围:30000-32767),每个节点会把该端口的流量转发到对应的服务,端口号会先是在服务的spec.ports[*].nodePort
如果你希望指定端口,你可以通过nodePort来定义端口号,系统会检查该端口是否可用,如果可用就则分配该指定端口。指定端口时需要考虑端口冲突,并且端口需要在预定义的范围内。
这为开发者提供了自由度,他们可以配制自己的LB设备,配制未被kubernetes完全支持的云环境,直接开放一个或者多个节点的IP供用户访问服务。
eBay的kubernetes 集群架设在openstack 环境之上,采用openstack vm作为kubernetes node,这些node在隔离的VPC,无法直接访问,因此对外不采用nodePort方式发布服务。
LoadBalancer
针对支持外部LB设备的cloud provider的情况,将type字段设置为LoadBalancer会为服务通过异步调用生成负载均衡配制,负载均衡配制会体现在服务的status.loadBalancer 字段。
实际上,当此类型的服务进行load balancer配置时,nodeip:nodeport 作为LB Pool的member,最终的traffic还是转到某node的nodeport上的。
因为eBay有openstack作为IaaS层架构,每个openstack AZ有专属的负载均衡设备,负载均衡设备与虚拟机(即kubernetes node)的连通性在openstack AZ创建的时候就已经设置好,并且openstack的LBaaS已经把针对LB设备的操作做了抽象,这让kubernetes和LB设备的通信变得非常简单。eBay直接采用社区版本的openstack provider作为cloud provider,该provider会调用openstack LBaaS api来进行LB设备的配制,无需订制即可实现与LB设备的集成。
Service Controller:服务是如何被发布到集群外部的
Kubernetes controller manager的主要作用是watch kube-apiserver的相关对象,在有新对象事件如创建,更新和删除发生时,进行相应的配制,如servicecontroller的主要作用是为service配制负载均衡,replicaset controller主要作用是管理replicaset中定义的pod,保证pod与replicas一致。如果你对kubernetes代码比较熟悉,你会发现servicecontroller是其中职责相对清晰,代码相对简单的一个控制器。
通过解读servicecontroller的源码,我们可以了解到servicecontroller 同时监控service和node两种对象的变化,针对任何新创建或者更新的服务,servicecontroller调用loadbalancer provider的接口来实现loadbalancer的配制。因为loadbalancer的member是cluster中所有的ready node,所以当有任何node的变化时,我们需要重新配制所有的Loadbalancer Pool以体现这种变化,这也就是servicecontroller要同时监控node对象的原因。
下图展示的是当servicecontroller调用openstack LB provider时所做的操作的时序图。
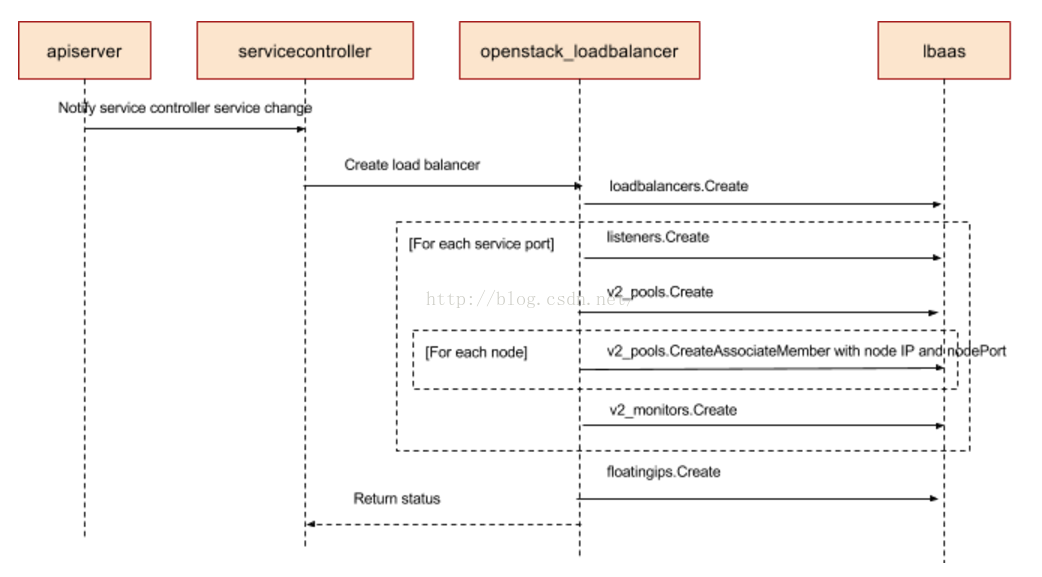
所以最终的配置结果是针对每个service的port,在LB设备上会创建一个loadbalancer pool,VIP可以接受外部请求,Pool Member是节点IP加nodePort。LB设备和Node(即openstack VM)处于同一个aviailablity zone和VPC,其连通性在aviailablity zone创建时即得到保证。物理上,LB设备和虚拟机所在的物理机通过路由连接,路由规则保证LB设备对特定IP段的VM可见。
这样的配制结果保证VIP接受到的所有traffic,能够根据LB设备的规则,跳转到kubernetes node的nodePort。
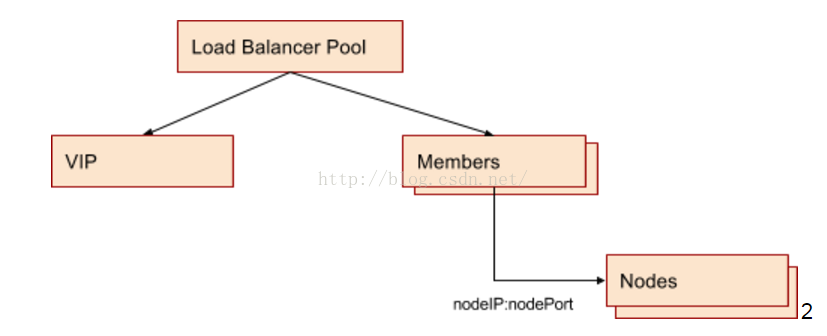
为什么用NodeIP:nodePort作为LB member,如果一个cluster规模较大,如几千个Node,LB pool会不会很大,为什么不用pod IP作为LB?
-
LB和VM之间的路由规则配制只包含VM IP段,在AZ部署的时候创建。pod ip在通常情况下是不同的range,与LB之间无法直接相通。采用node IP作为Pool member使得底层架构openstack的配制和kubernetes的配制分离开来,不用考虑pod的IP范围划定。
-
node的变化相对pod而言较少,这样可以减少对LB 设备的访问,LB可能会出错。
-
LB service type是基于node port type的,service 同时提供两种访问方式。
-
集群中每个节点被轮询到的机会均等,这使得每个节点需要解析iptables的机会一致,进而使iptables解析在每台机器的资源需求一致,避免某些节点因为iptable rules解析导致压力过大的可能性。(与Tim Hockin面对面讨论过此事)
kube-proxy: 接好最后一棒,从Node到Pod
我们知道,kubernetes服务只是把应用对外提供服务的方式做了抽象,真正的应用跑在Pod的成员Container里,我们通过LB设备已经把提交至VIP的请求转到kubernetes nodes对应的nodePort上,那么nodePort上的请求是如何进一步转到提供后台服务的Pod的呢?Kube-proxy is the secret sauce,我们来看看kube-proxy都做了什么。
目前kube-proxy支持两种模式,userspace和iptables,iptables模式因为不需要userspace和kernel space的切换,在数据转发上有更高的效率。所以从1.2版本开始,iptables是默认模式,只有当kernel版本不支持iptables时,userspace模式才需要被启用。
kubernetes只操作了filter和nat表。
Filter
在该表中,一个基本原则是只过滤数据包而不修改他们。filter table的优势是小而快,可以hook到input,output和forward。这意味着针对任何给定的数据包,只有可能有一个地方可以过滤它。
NAT
此表的主要作用是在PREROUTING和POSTROUNTING的钩子中,修改目标地址和原地址。与filter表稍有不同的是,该表中只有新连接的第一个包会被修改,修改的结果会自动apply到同一连接的后续包中。
下面是基于iptables chain的数据包流向图
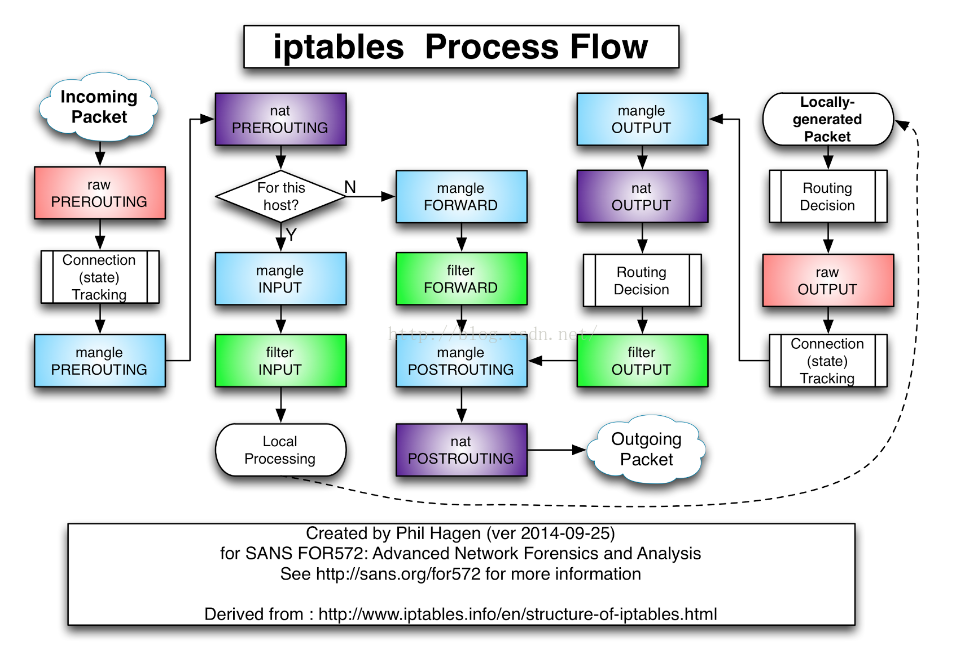
基于iptables的kube-proxy的实现代码在pkg/proxy/iptables/proxier.Go,其主要职责包括两大块,一块是侦听service更新事件,并更新service相关的iptables规则,一块是侦听endpoint更新事件,更新endpoint相关的iptables规则,将包请求转入endpoint对应的Pod,如果某个service尚没有Pod创建,那么针对此service的请求将会被drop掉。
kube-proxy对iptables的链进行了扩充,自定义了KUBE-SERVICES,KUBE-NODEPORTS,KUBE-POSTROUTING,KUBE-MARK-MASQ和KUBE-MARK-DROP五个链,并主要通过为 KUBE-SERVICES chain增加rule来配制traffic routing 规则。
我们可以通过对照源码和iptables 规则表,来分析针对下面的service信息,kubernetes做了怎么样的iptables 配制。
| kubectl get svc es1 -o yaml apiVersion: v1 kind: Service metadata: creationTimestamp: 2016-08-26T05:03:38Z labels: component: elasticsearch name: es1 namespace: default resourceVersion: "7514" selfLink: /api/v1/namespaces/default/services/es1 uid: 72f28428-6b4a-11e6-887a-42010af00002 spec: clusterIP: 10.0.147.93 ports: - name: http nodePort: 32135 port: 9200 protocol: TCP targetPort: 9200 selector: component: elasticsearch sessionAffinity: None type: LoadBalancer status: loadBalancer: ingress: - ip: 104.197.138.206 kubectl get endpoints es1 NAME ENDPOINTS AGE es1 10.180.2.11:9200 11d |
-
在iptables表中,通过iptables-save可以看到在nat表中创建好的这些链。
| :KUBE-MARK-DROP - [0:0] /*对于未能匹配到跳转规则的traffic set mark 0x8000,有此标记的数据包会在filter表drop掉*/ :KUBE-MARK-MASQ - [0:0] /*对于符合条件的包 set mark 0x4000, 有此标记的数据包会在KUBE-POSTROUTING chain中统一做MASQUERADE*/ :KUBE-NODEPORTS - [0:0] /*针对通过nodeport访问的package做的操作*/ :KUBE-POSTROUTING - [0:0] :KUBE-SERVICES - [0:0] /*操作跳转规则的主要chain*/ |
-
为默认的prerouting,output和postrouting chain 增加规则,跳转至kubernetes自定义的新chain。
| -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING |
-
对于KUBE-MARK-MASQ链中所有规则设置了kubernetes独有MARK标记,在KUBE-POSTROUTING链中对NODE节点上匹配kubernetes独有MARK标记的数据包,进行SNAT处理。
| -A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000 |
-
Kube-proxy接着对每个服务创建“KUBE-SVC-”链,并在nat表中将KUBE-SERVICES链中每个目标地址是service的数据包导入这个“KUBE-SVC-”链,如果endpoint尚未创建,KUBE-SVC-链中没有规则,任何incomming packets在规则匹配失败后会被KUBE-MARK-DROP。
| -A KUBE-SERVICES ! -s 10.180.0.0/14 -d 10.0.147.93/32 -p tcp -m comment --comment "default/es1:http cluster IP" -m tcp --dport 9200 -j KUBE-MARK-MASQ /*非Pod内部,针对cluster IP的请求,做snat操作*/ -A KUBE-SERVICES -d 10.0.147.93/32 -p tcp -m comment --comment "default/es1:http cluster IP" -m tcp --dport 9200 -j KUBE-SVC-LAS23QA33HXV7KBL /*针对cluster IP的请求*/ -A KUBE-SERVICES -d 104.197.138.206/32 -p tcp -m comment --comment "default/es1:http loadbalancer IP" -m tcp --dport 9200 -j KUBE-FW-LAS23QA33HXV7KBL /*针对LB IP的请求,直接交由iptables转发,防止来自cluster内部的请求给LB设备造成压力*/ -A KUBE-FW-LAS23QA33HXV7KBL -m comment --comment "default/es1:http loadbalancer IP" -j KUBE-MARK-MASQ -A KUBE-FW-LAS23QA33HXV7KBL -m comment --comment "default/es1:http loadbalancer IP" -j KUBE-SVC-LAS23QA33HXV7KBL -A KUBE-FW-LAS23QA33HXV7KBL -m comment --comment "default/es1:http loadbalancer IP" -j KUBE-MARK-DROP |
-
调用openLocalPort侦听service nodePort,增加KUBE-NODEPORTS chain,并添加跳转规则将此端口收到的packets转到KUBE-SVC-LAS23QA33HXV7KBL链
| -A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS /*来自集群外部,通过NodePort或者LoadBalancer访问的请求*/ -A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http" -m tcp --dport 32135 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http" -m tcp --dport 32135 -j KUBE-SVC-LAS23QA33HXV7KBL |
-
Endpoint Chain,当接收到的 serviceInfo中包含endpoint信息时,为endpoint创建跳转规则。
-A KUBE-SVC-LAS23QA33HXV7KBL -m comment --comment "default/es1:http" -j KUBE-SEP-G4AX7RHRQVIX7P25 -A KUBE-SEP-G4AX7RHRQVIX7P25 -s 10.180.2.11/32 -m comment --comment "default/es1:http" -j KUBE-MARK-MASQ -A KUBE-SEP-G4AX7RHRQVIX7P25 -p tcp -m comment --comment "default/es1:http" -m tcp -j DNAT --to-destination 10.180.2.11:9200 |
-
如果service类型为nodePort,(从LB转发至node的数据包均属此类)那么将KUBE-NODEPORTS链中每个目的地址是NODE节点端口的数据包导入这个“KUBE-SVC-”链;
| -A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS -A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http" -m tcp --dport 32135 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http" -m tcp --dport 32135 -j KUBE-SVC-LAS23QA33HXV7KBL |
-
如果一个service对应的pod有多个replicas,在iptables中会有多条记录,并通过 -m statistic --mode random --probability 来控制比率。
| -A KUBE-SVC-7BB4GED2QYDGC4GN -m comment --comment "kube-system/elasticsearch-logging:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-I7ND2XAHQESZGFZQ -A KUBE-SVC-7BB4GED2QYDGC4GN -m comment --comment "kube-system/elasticsearch-logging:" -j KUBE-SEP-OECUK2RLRF65RRGG |
Iptables chain支持嵌套并因为依据不同的匹配条件可支持多种分支,比较难用标准的流程图来体现调用关系,为进一步归纳iptables的跳转流程,上面的PREROUTING chain的最终跳转规则,抽象为下图,仅供参考。
针对通过cluster LB转发进来的外部请求,因为LB设备的memeber是nodeIP: node Port,所以针对这类请求,在iptables 层走的是KUBE-NODEPORTS分支。
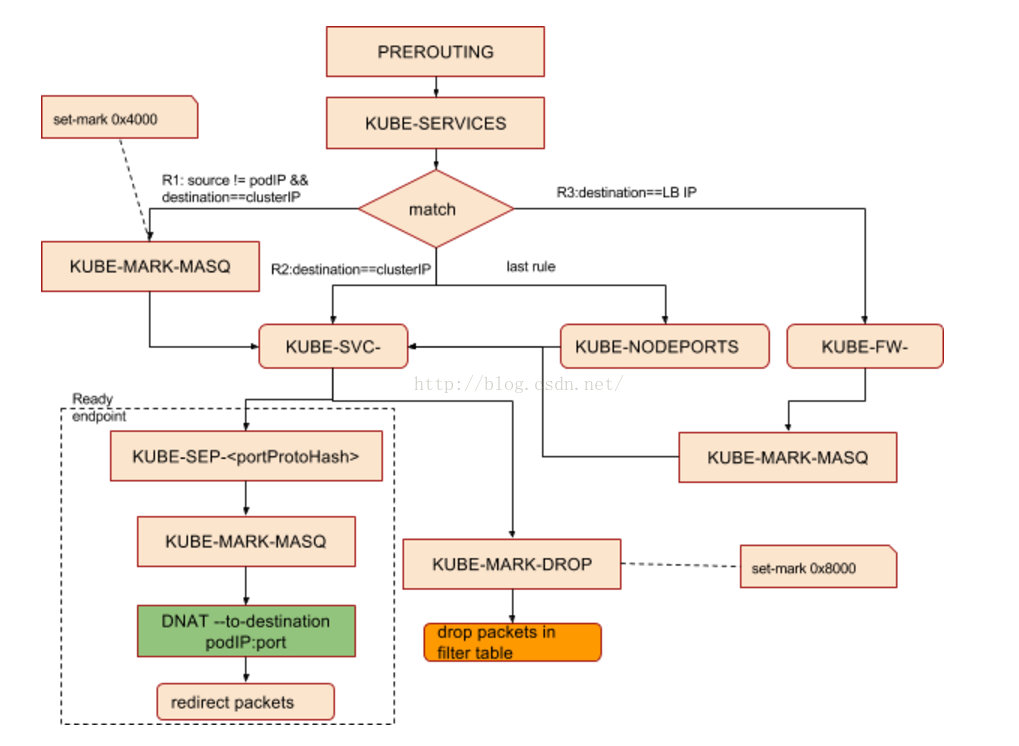
Ingress:更优雅的发布服务
通过IP tables,kubernetes实现了数据的高效转发,通过与集群LB设备的整合,实现了服务对外的发布,一切看起来已经working perfectly,实则不然。
全局IP不够用怎么办
很多时候,我们的公共服务需要提供global routeable的IP,针对类型为LoadBalancer的每一个service,系统都会自动分配一个全局IP。因为kubernetes用户拥有创建服务的自由,如果我们确保服务分配的IP都是global routeable的,很容易造成全局IP的滥用,甚至不够用。
Dynamic dns
通常,我们提供给用户的服务地址是域名而不是IP地址,我们需要通过某种方式(手工或者自动)在DNS server中写入服务的dns record。虽然服务本身没有生命周期,kubernetes的本意是希望serivce 长期存在的。因为服务的IP是动态分配的,如果用户重建服务,IP是会重新分配的,所以DNS server中的记录也是动态的。这使得针对同一服务,可能存在TTL问题,客户有可能会遭遇访问失败。
L7 rules
针对服务发布,一种常见的场景是,用户分配几个专用的全局IP,将这些全局IP作为服务访问的入口,这些IP会预先在DNS server中创建好dns record。针对不同的服务,通过L7转发规则,进行hostname/path到具体服务的跳转。
TLS termination
因安全需求,面向用户的服务,只支持安全访问协议,如https。主流的LB设备都支持TLS termination,即面向用户的服务是https的,https connection在LB设备结束,LB设备到提供服务的应用中间的连接是非secure,因为这一段的连接往往在防火墙内部,属于可信网络。这种模式既提供了安全保证,又把安全配制从应用中分离出来,简化应用开发。
Ingress
针对上述的问题,kubernetes从1.2 release开始提供Ingress来支持七层路由。对于大多数环境来讲,服务和Pod通常只有在cluster网络可以路由的IP,对于这样的环境,来自internet的请求要么被drop要么被转发到别处(在eBay我们的service IP 是global routable的)。
internet
|
------------
[ Services ]
Ingress定义了一系列使得inbound 连接到达集群服务的规则,在kubernetes中所处的地位如下。
internet
|
[ Ingress ]
--|-----|--
[ Services ]
Ingress可以为服务配制外部可达的URL,负载均衡traffic,SSL,提供基于名字的虚拟hosting。
Ingress可以指定包含TLS私钥和证书的secret来传递TLS 连接所需的证书信息。secret信息可以通过如下步骤创建:
| 生成证书 $ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /tmp/tls.key -out /tmp/tls.crt -subj "/CN=echoheaders/O=echoheaders" 创建证书对应的tls key和crt $ echo " name: tls |
通过在ingress 定义中指定tls.secretName可以非常方便的指定证书,相应的,ingress controller需要实现证书上传和配制的逻辑。
| apiVersion: extensions/v1beta1 |
Ingress Controller
用户通过向apiserver提交请求创建ingress对象,而我们需要对应的ingress controller来操作ingress 对象,实现Loadbalancer的配制。因为不同的用户环境,采用的Loadbalancer不尽相同,社区的ingress controller采用add-on的形式实现,目前有基于nginx和gclb(google cloud load balancer)的ingress controller的开源实现。
拿基于nginx的ingress controller为例,该ingress controller监控apiserver,针对任何ingress的create 和 update事件,通过获取ingress对应的服务,endpoint以及config,生成或更新nginx的配制文件,并reload nginx使配制即时生效。
eBay作为e commercial公司,网络环境与其它互联网公司类似。区别于传统的flat 模式,因为traffic management的需要,我们采用两层LB设备的拓扑结构,每个集群有cluster local load balancer,在此之上有跨集群的cross region load balancer。其中cluster local LB负责的是region内部的负载均衡,cross region LB负责的是跨region的负载均衡,为避免单点故障和满足流量管理的需求,针对同一应用,所有的cluster local LB pool的VIP都作为cross region LB pool的memeber,形成如下图的拓扑结构。
真对两层loadbalancer的管理我们称之为Local Traffic Management,在此之上,我们需要与Global Traffic Manager整合,主要是全局DNS server(geography aware),使得用户请求可以转发至就近的处理节点。与GTM的整合由federation service/ingress controller来完成。
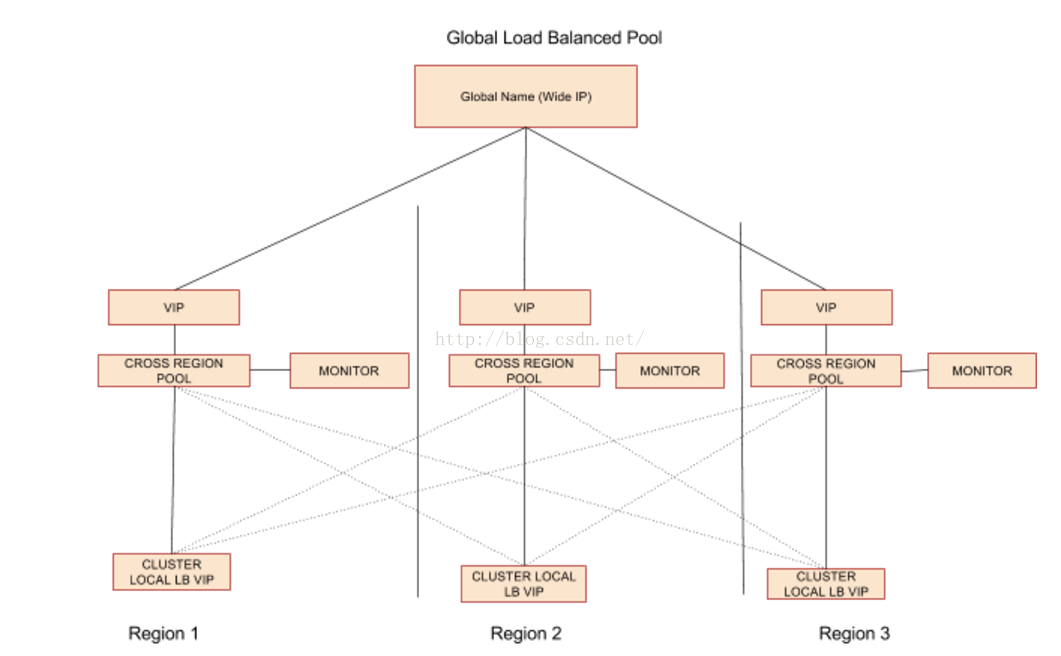
基于此拓扑,我们采用自己实现的Ingress controller来监控ingress 对象,针对任何ingress的创建和更新,查找对应的cluster local LB VIP,并且将这些VIP作为memeber,创建cross region的LB设备的配制。同时,我们在评估可以应用在生产环境的software load balancer。
集群联邦:投入生产环境吧
我们分析了Kubernetes针对流量转发的原理,介绍了将kubernetes服务对外发布的方式以及eBay的实践,那么部署生产系统的服务还欠缺什么呢?跨Availability Zone的高可用。
虽然kubernetes借助replicaset(或replicationcontroller)天然支持pod级别的高可用,但我们不能假定数据中心永远不会出问题,数据中心也可能遭遇区域断电,地震等大规模灾难。
自1.2版本开始,kubernetes开始引入federation提供跨cluster的高可用,通过将不同AZ,不同Region的kubernetes集群组成同一个联邦,我们可以实现使kubernetes满足生产系统的要求。
本文的图一展示了联邦层control plane的主要组件,下面的章节着重分析一下每个组件的具体作用。如果用户希望部署跨集群的应用和服务,建议将federation apiserver作为唯一访问入口,federation controller会将待创建资源转发至相应的kubernetes集群。
Cluster Controller
集群要加入联邦,首先要通过federation apiserver创建cluster对象,cluster controller负责针对集群做healthcheck。
Federated Replicaset Controller
Replicaset是replicationcontroller的替代版本(在kubernetes中二者是等价的,但在federation control plane,replicationcontroller因为未来会被deprecated而未获支持)。Federated Replicaset Controller负责将用户定义的replicaset,依据特定的调度算法,转发至目标集群。当用户定义了replicaset,包括replica,pod,container等信息,可以通过annotation指定目标该replicaset在每个目标cluster要部署的replica数量。如果未指定目标集群,那么该replicaset会被平均分配到每个kubernetes中。
下面是一个指定特定cluster中replica数量的例子:
| "federation.kubernetes.io/replica-set-preferences": `{"rebalance": true, "clusters": { "k8s-1": {"minReplicas": 10, "maxReplicas": 20, "weight": 2}, "*": {"weight": 1} }} |
Replicaset controller同时会监控每个集群中replicaset的状态,确保所有集群中的replicas总和与用户期望吻合,如果承担scale和failover等职责。
Federated Service Controller
Federated Service Controller负责将用户定义的service spec转发到所有状态正常的集群中(replicaset controller是依据调度算法调度,service和ingress不涉及调度)。
集群的服务控制器接收到服务创建或更新事件后,如果该服务类型为LoadBalancer,则调用loadbalancer provider 为该服务分配load balancer IP,并将状态汇报给集群联邦。
Federated Service Controller承担更多的监控和协调职责,包括:
-
监控所有集群的service 状态,如果LoadBalancer IP发生变化,则更新Federation apiserver。
-
调用dns provider接口,将zone level,region level和global level的cname写入 global dns server,
DNS name的pattern如下,其中federationname和dnsZoneName是在federation的配制文件中指定的联邦名字和域名(如:ebay.com),zoneName和regionName是从每个cluster master node的label中获取的zone和region信息。
| Zone level: servicename.namespace.federationname.svc.zoneName.regionName.dnsZoneName Region level:servicename.namespace.federationname.svc.regionName.dnsZoneName Global level:servicename.namespace.federationname.svc.dnsZoneName |
-
监控所有集群中,service对应的endpoint信息。kubernetes endpoint controller会为每个running pod创建endpoint对象,如果endpoint中存在ReadyAddress,说明该endpoint可达,federation service controller调用将该集群的LB 信息作为A records的IP地址写入GLobal DNS。
-
维护服务状态,如果某集群不可达,或某集群中的所有endpoint均为不可达,则将该集群对应的LB IP从dns中移除。
下图展示了集群拓扑下,服务创建的流程。
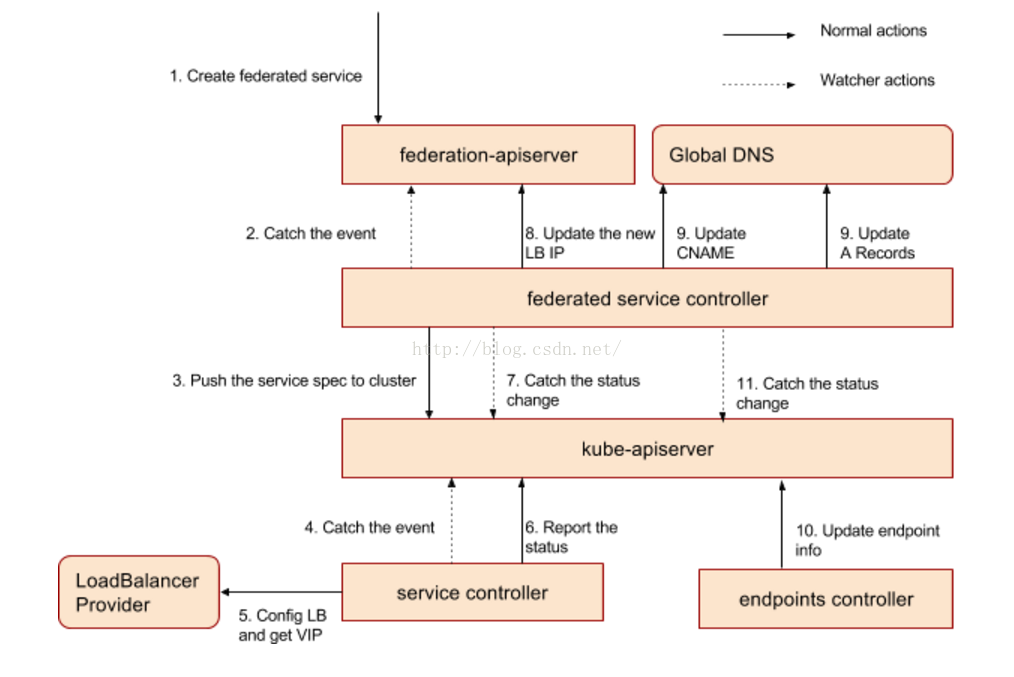
Federated Ingress Controller
Federated Ingress Controller的职责与工作原理非常相近,它监控Ingress的创建,更新或删除实践,将请求转发至每个集群Ingress Controller,并通过监控集群来维护Ingress的状态。
服务发现
集群内部服务发现
Skydns作为kubernetes的addon,保证集群内部的服务发现。在1.2以及之前的版本,skydns由kube2sky,skydns和etcd组成。1.3针对dns addon做了较大改动,skydns被kubedns取代,职责是监控集群中service和endpoint的变化,并维护基于内存查找的数据结构。etcd被移除,另外引入了dnsmasq来提高效率。
Skydns作为built的addon,会在cluster创建时启动。
在cluster bootstrap时指定 dns server ip
| ENABLE_CLUSTER_DNS="${KUBE_ENABLE_CLUSTER_DNS:-true}" DNS_SERVER_IP="${KUBE_DNS_SERVER_IP:-10.0.0.10}" DNS_DOMAIN="${KUBE_DNS_DOMAIN:-cluster.local}" DNS_REPLICAS=1 |
该配置会写入kubelet配置,这使得该kubelet启动的所有pod在做nslookup的时候,能够向正确的dns server地址发送请求。
集群外部服务发现
目前针对kubernetes外部访问,kubernetes没有天然集成DNS,但因为kubernetes本身开放灵活的查找服务的Rest API,CLI和UI,用户可以查询服务并根据loadbalancer IP:port或node IP:nodePort的方式访问。
另外,集群联邦的服务控制器都与global dns server整合,dns name会依据既定模式自动写入,用户可以通过dns query获取地址,或直接通过hostname服务。
如果定义了L7rule,则可以方便的通过预定义的URI访问服务。
如果我们在eBay的kubernetes集群中部署了一个web服务,在集群联邦的视角下,一个来自互联网的访问,经历如下的转发最终到达应用本身。
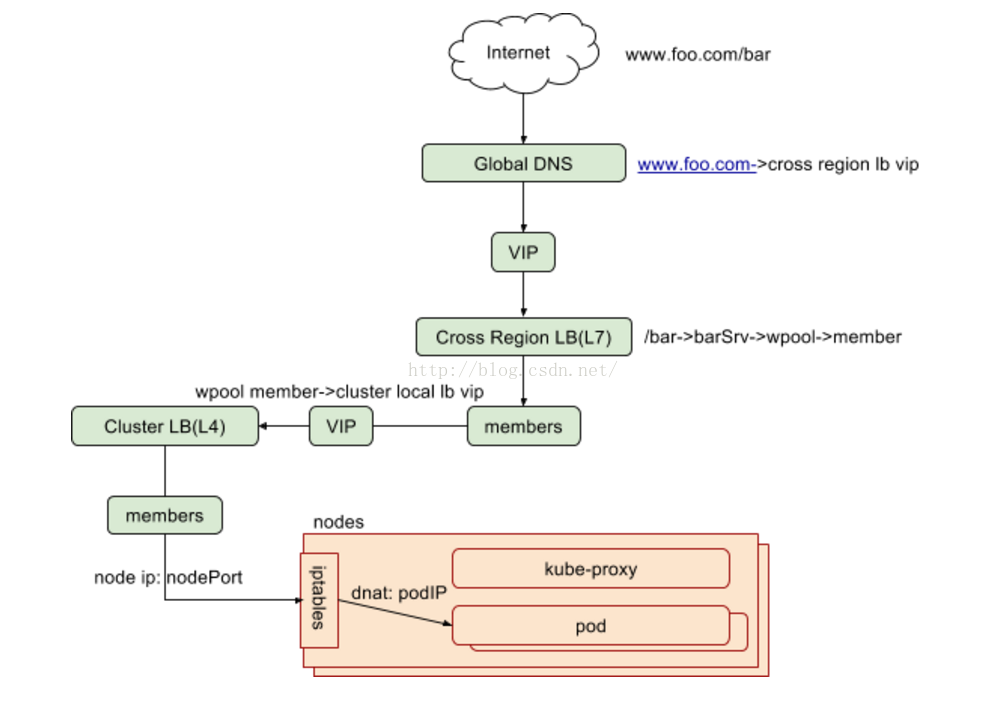
小结
kubernetes是一个高速发展的开源项目,此文适用的版本是1.4。还有更多跟服务相关的设计和开发正在进行中。一个典型的例子是Service Catalog的PR正在探讨将类似cloud foundry中的Service Broker在kubernetes实现更便捷的全局服务注册和发现。
如果您发现本文的内容有任何谬误或者因为kubernetes版本更新已经不再适用,请联系作者:mengfj@gmail.com
参考资料
Kubernetes doc:http://kubernetes.io/docs/
Kubernetes source code:https://github.com/kubernetes/kubernetes/
Iptables flow chart:http://stuffphilwrites.com/2014/09/iptables-processing-flowchart/














 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









