







虽然学术界和工业界对XML数据库的研究和开发并不完全一致,但是两者的目标却非常相似:解决现有问题,扩展应用领域。
一.学术界与工业界的两种不同索求
Ronald Bourret 在他那篇著名的《XML Database Products》中,将XML数据库产品分为中间件(Middleware)、支持XML的数据库(XML-Enabled Databases)、纯XML数据库(Native XML Databases)、XML服务器(XML Servers)、Wrappers、内容管理系统(Content Management Systems)、XML查询引擎(XML Query Engines)、XML Data Binding、Discontinued products等九种,在业界影响很大。但是,在XML数据库的研究和开发人员眼里,或许只有支持XML的数据库、纯XML数据库能够称得上是真正意义上的XML数据库。支持XML的数据库可以被看做是支持XML数据的数据库系统,它可能是关系数据库、对象数据库等。就在一年半以前,还有相当多的人在争论关系库支持的XML数据库和纯XML数据库孰优孰劣的问题。但是,纯XML数据库却在这种争论中悄然进步,在技术上有了长足的发展。
人们已经越来越倾向于认为XML数据库就是纯XML数据库。随着金融界确立XBRL(XML的一个子集)标准和政府规范电子政务的XML格式,实践推动着XML数据库技术不断向前发展。
XML数据库系统从最初简单的查询引擎,不断地加入查询优化、事务处理、触发器、并发控制、代数系统等传统的数据库技术,一步步地从性能和功能上完善自己。
从目前XML数据库的产品情况来看,学术界的实验系统和市场产品之间有着些许微妙的差别,尽管它们的主流技术是一致的。
学术界完成的实验室原型系统一般侧重于下面的一些特点:
● 专注于查询性能的提高,对查询优化的研究较多。为了提高查询效率,学术界十分重视索引结构的设计,先后提出二十几种适合于XML数据的索引方式,比如影响很大、简单易用的三元组索引,并在此基础上开发出了以结构化联接为基础的查询模式匹配方法。
● 强调平台无关性。在XML数据库研究的早期,业界曾存在一个争论:到底将XML数据存储在关系库中,还是另外开发存储XML的物理数据库。这在一定程度上影响着XML的研究者,在设计索引结构时必须考虑使索引过的XML数据可以存储在多种数据库结构中。
● 从理论的角度较多地考虑了XML数据库的模式设计规范化问题。设计了基于键的函数依赖推理,在如何优化XML数据库设计、消除数据冗余和不一致方面有了一些实质上的进展。
工业界的XML数据库产品更加强调实用,有着一些与学术界原型系统不尽相同的特点:
● 现有的主流XML数据库产品都在底层提供collection数据结构,以存储XML元素节点,通过B+树结构来索引这些元素节点。这一点与关系库系统的底层处理如出一辙。在collection之上一般还会有一级或两级索引,以加快查询处理速度。这一点比平台无关的实验原型系统更高效实用。
● 市场上的数据库产品通过引入日志管理,建立了较完善的事务处理机制,这为上层的数据库应用开发提供了便利。目前的商用XML数据库一般提供事务处理功能,包括提交、回滚和日志文件。通过提供事务日志机制,纪录系统执行的每个事务的详细情况,保证在系统出现问题后可以完全恢复。
● 增强了对异构数据源的集成管理。树型结构的XML数据有其难以管理的一面,但是,XML技术的可扩展性又使得它具有集成异构数据源的强大能力。因此,市场上的XML数据库产品普遍具有较强的集成多种数据源的功能。这也是当前市场上的XML数据库产品的一大亮点。
二.实验室的原型系统和商用化产品
最近几年以来,在学术界和工业界的共同推动下,如雨后春笋般诞生出大量的XML数据库原型系统和商用产品。
在Ronald Bourret的《XML Database Products》中一共列了36种XML数据库产品,大致上可分为三大类型:
● 商业类(commercial):如Ipedo、Tamino、Natix、Xyleme等。其中,美国Ipedo公司的Ipedo XML Database和德国Software AG公司的Tamino是其中的佼佼者,成为目前市场上的主流产品。
● 研究类(research):如Stanford大学早期开发的Lore等。
● 开放源码类(open source):其中影响较大的是Berkeley DB XML、dbXML、XDB和Xindice。
需要指出的是, Lore database systems 只是Stanford大学早期针对半结构化数据而开发的数据库系统。Lore连同其专设语言Lorel都是为半结构化数据而写的。尽管说XML数据在某种程度上也是一种半结构化数据,但是,两者之间还是有着一些差别,导致Lore database systems很难成为一种完全意义上的XML数据库系统。
事实上,在学术界,真正受到关注的XML数据库原型系统有三家:密歇根大学安阿伯分校的Timber、西雅图华盛顿大学的Tukwila和威斯康星大学麦迪逊分校的Niagara。其中,影响最大的是Timber,在该系统的实施过程中,产生了许多有关XML数据库的新的概念和方法。当然,多伦多大学的Tox也是一个相当不错的系统,尤其是其出色的索引结构。但是,总体上不如前面的三家有名。
三.核心技术的进展
综合XML数据库的实验室原型和商业产品的共性,形成了如图1所示的一幅XML数据库的一般结构图。依据图1, XML数据库的核心技术主要包括:
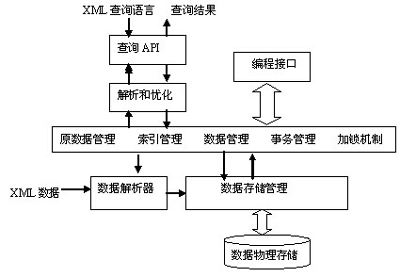
1.查询语言
自从1995年XML技术的研究和开发逐渐升温以来,形形色色的XML查询语言不断问世。比较有代表性的如早期的XML-QL、XQL、UnQL,后来的Quilt、Xpath,以及由Quilt发展而来的XQuery。在W3C的极力推动和学术界、工业界的大力支持下,XQuery逐渐在这些查询语言中脱颖而出,成为事实上的工业标准。
XQuery的FLWR语句规范,有着与关系数据库的SQL完全类似的表达方式,使得它在一般用户眼里,也变得友好起来。
而Xpath可以理解为是XQuery的一个子集。Xpath表达式在相关文献中被证明与查询模式树是等价的,这也与学术界推崇的模式树查询方式一致,使得实验室系统可以毫不困难地处理Xpath查询表达式,并能进行查询优化。这一点在XML数据库研究中显得颇有价值。
2.XML文档解析
在图1中,将XML文档载入数据库时,会经过一个XML数据解析器。数据解析器会依据一定的规则对XML数据进行解析后装入数据库。目前的数据解析器一般提供SAX(simple API for XML)和DOM(document object model)两种方式。
SAX和DOM是针对XML文档的两种不同的应用程序编程接口API。SAX更多地依赖语法制导(syntax driven),而DOM则提供一组功能程序来开发与XML数据相关的应用。
SAX解析器是边读入边解析,带有一定的实时性,特别适合于XML流数据的处理。而DOM解析器是待整个文档均导入内存后才开始解析,在一定程度上受到内存容量的限制。目前的XML数据库产品均支持这两种解析方式。
3.查询处理
查询处理的方式和效率,一直是XML数据库研究和开发者关注的首要问题。
如图1所示,XML数据库的查询处理一般是从解析查询语言(如XQuery)的查询语句表达式开始的。XML数据库的查询解析器将表达式解析为一棵查询模式树(有的系统叫做语法树)。
假设一个XQuery表达式为:
book [tittle = ‘XML’] // [ year = ‘2000’]
它所对应的模式树如图2所示,它表示我们要查询的 book节点满足下面的条件:

● 有一个子节点tittle,它的内容为串值XML;
● 它有一个后代节点year,它的内容为串值2000。
从语义上来说,就是:查找“一本2000年出版的、名为XML的书”。
接下来就是到XML数据库中去匹配这棵树,得到最终的XML结果文档。
在如何匹配模式树的技术上,实验室原型系统与商业产品之间有着一些差别。
比如,在Timber中,考虑了一种叫做“结构化联接”的技术。它的基本思路是将上述的模式树分解为二元关系序列。而在此之前,也已经将XML文档库做了索引处理,文档中每个元素节点均被标以一个三元组索引,形式为:(文档标识符,开始位置:结束位置,层号)。
于是,该查询模式可以分两步来完成:在索引过的XML数据库中匹配上述分解的二元结构关系;将查找到的二元结构匹配结果组装(stitching)成最终的符合上述查询表达式的完整文档。
结构化联接技术在2002年被提出并在Timber中实现以后,在学术界引起过较大的反响。自2002年以来不断有技术上的改进文章出现在数据库的三大国际会议(VLDB、SIGMOD/PODS、ICDE)上,其中较有影响的成果是隐检整枝联接(holistic twig join)技术,可以用相互连接的多栈结构一次性生成查询结果文档。
在商用产品中,由于文档元素节点均存储在B+树结构中,可以直接到底层的数据库中去查找相关的匹配节点序列,再根据其指针关联,将结果节点集组装成结果文档。
总的来说,实验室产品在输入节点序列较长时效率会较高,尤其是隐检整枝联接技术。而商用产品在查询的文档较大时更显优势。
在查询处理阶段,实验室产品做了而商用产品没做的事情就是模式树的最小化。它的主要思想就是,模式树的匹配效率依赖于模式树的规模(元素节点的多少)。而一般的模式树均存在一定量的冗余节点,可以通过最小化算法予以去除。
根据复旦大学数据库研究中心XML小组的实验结果表明,在随机建立的XML查询模式树集合中,最小化算法平均可以消除30%的冗余节点。
当然,模式树最小化算法的时间复杂度比较高,目前的关注点主要在于时间复杂度的降低上。最新算法的时间复杂度已经降低到低阶的多项式时间了。这项技术的实用化是值得期待的。
4.事务处理和版本控制
目前的商用XML数据库一般提供事务处理功能,包括提交、撤回和日志文件。我们知道,事务为数据库的一组操作,这些操作组成一个逻辑单元,执行时要么全部完成,要么全部不做(do all or do nothing)。XML数据库通过提供事务日志机制,纪录系统执行的每个事务的详细情况,保证在系统出现问题后可以完全恢复。
事务遵循的ACID性质 (原子性、一致性、独立性和持久性) 保证了大部分事务处理稳定地运行。
商用XML数据库也包含对XML文档的版本控制功能。使用版本控制,用户或应用程序可以检入(check in)或检出(check out)XML文档,利用版本号、日期或者标签获得以前版本的文档,以及显示XML文档的版本历史信息。每一个处于版本控制之下的文档都有自己的历史信息,纪录了修改文档的作者以及时间等。使用者可以根据文档或用户或日期来查看整个的版本历史信息。
版本控制允许用户通过查询更新原信息。通过更新引擎可以注释、修改和精炼信息。内置的版本系统跟踪信息的变化,提供这些变化的历史信息。
应该说,在事务处理和版本控制机制上,实验室产品的考虑是不够的,所提供的事务处理的功能显得简单。尽管加州大学洛杉矶分校的数据库实验室在XML的版本控制方面有一些突出的成果,但是,目前尚未形成产品。
还有一个需要说明的是多事务并发控制机制和加锁协议。这项技术的研发目前刚刚起步。现今的商用XML数据库只在逻辑层面提供并发加锁协议,但粒度为整个文档。随着单个XML文档的增大,这个粒度显然太粗。这一点可能要等待研究界开发出粒度为文档元素节点的并发协议了。
5.代数系统和模式规范化
代数表达式和数据库模式设计理论曾经是关系数据库理论的精髓。代数系统成为关系库查询优化的重要工具,而范式理论的提出也曾为RDBMS设计优化的库结构提供了依据。那么,人们不禁要问,在XML数据库中是否存在相类似的理论和方法?
由于这两个问题有一定的难度,注定只能是由学术界的实验系统先行一步。
学术界公认的三大实验系统都设计了相应的代数系统,其中影响最为广泛的是Timber中实现的TAX(Tree Algebra for XML)。TAX以整个文档树作为操作的基本单位,在逻辑层提供选择、投影、联接等类似关系库的9种基本操作和5种附加操作,以匹配模式树得到实例树(witness tree)为基本操作方法。在物理层提出7种基本操作实现上述逻辑运算。
Timber依据TAX对XML查询语句进行改写和优化,但是效果并不理想。业界对TAX存在问题的看法是,过分地模仿了关系库的代数系统而忽略了对XML文档本身特点的考虑。
XML模式规范化理论的早期开拓者是宾夕法尼亚大学的樊文飞等人。从定义XML的键(key)和函数依赖,到XML和DTD范式,再到基于约束的XML数据库的模式规范化,XML数据库的模式规范化理论在稳步地推动着。国内的复旦大学数据库研究中心等单位也有着不错的研究进展。在未来两年内,估计会有较成熟的XML数据库模式设计理论投入到实验室产品和商用系统中。
6.多数据源的集成
多数据源的集成是数据库市场对XML数据库系统提出的要求。从1970年IBM公司的E.F.Codd提出关系数据库的概念以来,关系数据库在几乎所有的应用领域都取得了巨大成功。XML数据库是一个新事物,它从诞生的那一天起,就面临着关系数据库一统天下的局面。有人说,关系数据库完全战胜层次和网状数据库用了将近20年时间,XML数据库也会用20年时间战胜关系数据库。这种看法并不全面。至少从目前来看,两者应该各展所长,共同服务于巨大的数据库市场。
那么,XML数据库的优势在哪呢?用XML技术来进行多数据源的集成就是其中之一。
从2001年以后,面对多数据源的集成这个传统关系型数据库系统做不了的事情,Ipedo等商用数据库系统将自己的数据库系统扩展为一个集成平台,它可以将关系数据库系统、MIS系统、OA系统、文件系统等集成在同一个平台上,给用户提供统一的界面。如Ipedo公司的Ipedo XML智能平台,为用户提供XML View来统一访问底层的异构数据。人们也从这一点上进一步看到了XML技术的力量。
四.未来的技术发展方向
经过近5年业界同仁的共同努力,XML数据库技术取得了很大的进展,已经有若干种XML数据库产品问世并服务于社会生活的各个方面。但是,XML数据库的事业才刚刚开始,还有很多问题等待着我们去解决。
未来几年,XML数据库技术有可能在下述方面取得进展:
● 异构数据源的集成。XML数据库对多数据源的集成,是对XML技术可扩展性这一长处的极好发挥。但是,就目前的集成程度和在应用层上所提供的功能来看还是远远不够的。如何从对数据的集成过渡到对系统的集成,从而在远景目标上实现类似于网格计算(grid computing)概念的系统,恐怕是XML数据库工作者的核心任务之一。
● 底层索引结构。目前的商用XML数据库系统优于实验室原型系统的特点之一就是其底层的索引结构。但是,现有的商用XML数据库的底层索引结构一般都是B+树。虽然B+树索引是一种成熟的索引结构,但是,研究结果显示,在XML数据库中,它的性能表现并不是最好的。学术界已经开发出了若干种适用于XML数据的索引结构,如XR树、XB树等,需要XML数据库工作者来进一步关注。
● 并发加锁协议。在现有的XML数据库系统中,加锁的粒度是整个文档,事务并发的层次也在文档一级。随着应用级文档的日益增大,这个粒度在一定程度上将会成为系统效率的瓶颈。如何通过边锁(edge lock)机制来实现元素节点级粒度的加锁?这一工作现在吸引了不少研究者的目光,而且,上述的锁协议是在逻辑层,如何将它映射到底层的B+树索引(或者XR树索引)上,也是必须要做的一件事情。
● XML模式规范化是一个值得关注的方向。一旦取得突破,将会使我们可以像在关系库中那样方便地设计XML数据库的结构,消除数据的冗余和不一致现象。目前,这一领域已经成为学术界关注的热点。但是,完整的、为业界所公认的理论体系尚未建立。














 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









