







文章首先通过人类学习与机器学习的对比分析提出问题:
人类往往能够成功的将单一的样本一般概括化学习到新的概念,经典的机器学习算法却需要成千上万的相似样本去做训练集,人类相比传统算法也能对刚学到的概念进行灵活的使用,(行为、想象、解释),文章提出一个模型获取人类对手写字符这种简单视觉概念的学习能力(贝叶斯程序学习),对于单独的分类来说能达到深度学习的水平,能够通过图灵机测试。
人类只要给一个两轮交通工具,就能领会到这个新概念的范围,并且能够学到更丰富的表示,推广到更广阔的范围(去创造新的事物)。
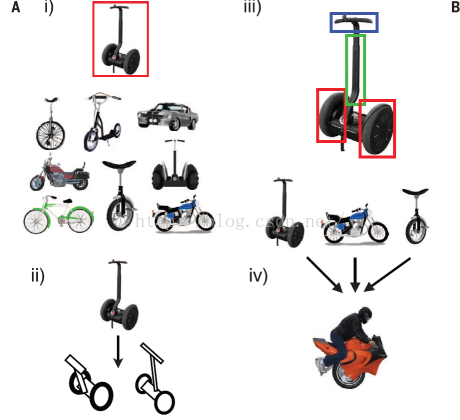
只给出一个新的样本,就能对其进行分类(两轮交通工具),产生抽象化的概念,对样本进行解析(部件,子部件,位置关系),并且能够根据已有样本的特点去产生新的样本。目前最好的分类器也不能完成这些额外的功能,需要专门的算法。
BPL概述
BPL(贝叶斯程序学习)通过简单的随机的program对概念进行表达,通过part subpart relation 的组合函数来描述生成模型(generative model)即表示概念,通过对part subpart relation的不同组合能够产生新的概念,再根据这个概念就能够产生新的样本,最后再将样本从符号水平的变量转换成原始数据格式进行输出。
就手写字符来说解释上边的概念
part 从笔放在纸面上开始书写作为开始,以笔抬离纸面作为结束
subpart part中笔在纸面上短暂停顿作为划分
因为subpart只是停顿,笔没有离开纸面,所以下一个subpart开始的地方就是上一个subpart结束的地方,relation表示的是part之间的位置关系,即下一笔开始的地方开始是上一笔开始的地方结尾的地方或者中间的某一部分。
文章选择了一个来自30个字母表的字符作为背景集,主要是使模型生成新概念时part subpart relation 的条件分布于该背景集一致,(也就是为了使产生的新概念符合实际吧)该背景集包括图像和笔画先后顺序,这些数据都不用做测试集,测试集是新生成的新型的字符的原始数据。
模型主要分为两部分:1.构建新的类型(type)2.根据新的概念产生样本
先介绍构建新类型
(1)从原始数据库中取样k个part,从每个part中取样n个subpart,取样服从通过背景集得到的经验分布。
(2)通过对一个离散笔画集的取样,构造一个part的模板,该离散笔画集是通过背景集得到的,也满足经验分布,因此,下一笔画的概率依赖于前一笔画。
(3)通过采样每个subpart的一些控制点和尺度参数,将part表示成参数化的曲线。(到这步已经得到的笔画的轮廓,轨迹)
(4)根据relation得到笔画间粗略的位置关系(独立放置,开始,结束,还是沿着之前的subpart)
具体算法过程如下:

得到一个新概念(种类)的生成模型。
根据新的概念产生样本
(1)进入到表征水平(书写水平?),引入适当的噪声来来生成笔画曲线S(m)
(2)笔画开始位置L的精确选定,从背景集中能够得到笔画的空间位置关系,结合上一笔,取样即可得到part的开始位置。通过一个函数f将开始位置L,subpart序列转换成精确的轨迹曲线。
(3)进行全局取样,包括放射弯曲A(m)以及适当的噪声来减缓概率推理(?)。
(4)通过随机补偿函数即可得到二值图像,用灰色墨水画出轨迹。
具体算法过程如下:

(确定笔画顺序)接下来需要大量的组合来生成原始图像,选择最速下降法,得到一些候选的解析,通过连续优化、局部搜索形成后验分布的离散逼近,得到最佳候选。
训练和测试
给出一个训练图像,5个program的解析以及得分,每个program都能够改造成测试图像,根据上述方法得到最佳解析,正确分类的得分高,重构图像清晰。(得分是计算log后预测概率)log posterior predictive probability。
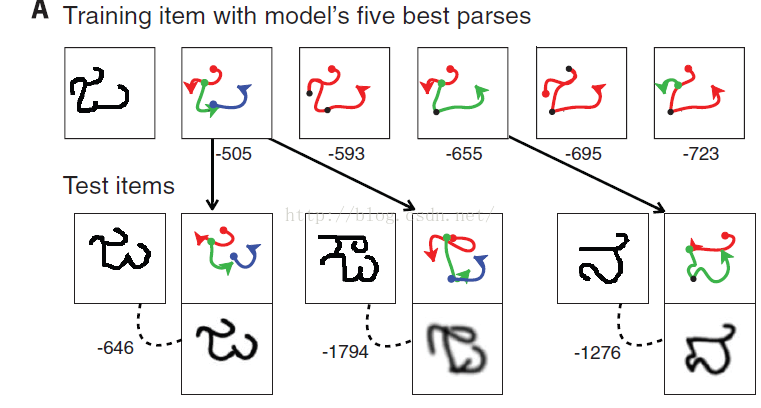
可以很明显的看出分类正确的得分高重构清晰。
后边部分主要是一些图灵试验去说明模型的智能性,并在学习新概念与生成新样本两个方面与深度学习进行对比,表明该模型能够达到世界领先水平。














 4102
4102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









