







前言
经过2节对MovieLens数据集的学习,想必读者对MovieLens数据集认识的不错了;同时也顺带回顾了些Spark编程技巧,Python数据分析技巧。
本节将是让人兴奋的一节,它将实现一个基于Spark的推荐系统引擎。
PS1:关于推荐算法的理论知识,请读者先自行学习,本文仅介绍基于ALS矩阵分解算法的Spark推荐引擎实现。
PS2:全文示例将采用Scala语言。
第一步:提取有效特征
1. 首先,启动spark-shell并分配足够内存:

2. 载入用户对影片的评级数据:
1 // 载入评级数据 2 val rawData = sc.textFile("/home/kylin/ml-100k/u.data") 3 // 展示一条记录 4 rawData.first()
结果为:

3. 切分记录并返回新的RDD:
1 // 格式化数据集 2 val rawRatings = rawData.map(_.split("\t").take(3)) 3 // 展示一条记录 4 rawRatings.first()

4. 接下来需要将评分矩阵RDD转化为Rating格式的RDD:
1 // 导入rating类 2 import org.apache.spark.mllib.recommendation.Rating 3 // 将评分矩阵RDD中每行记录转换为Rating类型 4 val ratings = rawRatings.map { case Array(user, movie, rating) => Rating(user.toInt, movie.toInt, rating.toDouble) }
这是因为MLlib的ALS推荐系统算法包只支持Rating格式的数据集。
第二步:训练推荐模型
接下来可以进行ALS推荐系统模型训练了。MLlib中的ALS算法接收三个参数:
- rank:对应的是隐因子的个数,这个值设置越高越准,但是也会产生更多的计算量。一般将这个值设置为10-200;
- iterations:对应迭代次数,一般设置个10就够了;
- lambda:该参数控制正则化过程,其值越高,正则化程度就越深。一般设置为0.01。
1. 首先,执行以下代码,启动ALS训练:
1 // 导入ALS推荐系统算法包 2 import org.apache.spark.mllib.recommendation.ALS 3 // 启动ALS矩阵分解 4 val model = ALS.train(ratings, 50, 10, 0.01)
这步将会使用ALS矩阵分解算法,对评分矩阵进行分解,且隐特征个数设置为50,迭代10次,正则化参数设为了0.01。
相对其他步骤,训练耗费的时间最多。运行结果如下:

2. 返回类型为MatrixFactorizationModel对象,它将结果分别保存到两个(id,factor)RDD里面,分别名为userFeatures和productFeatures。
也就是评分矩阵分解后的两个子矩阵:

上面展示了id为4的用户的“隐因子向量”。请注意ALS实现的操作都是延迟性的转换操作。
第三步:使用ALS推荐模型
1. 预测用户789对物品123的评分:

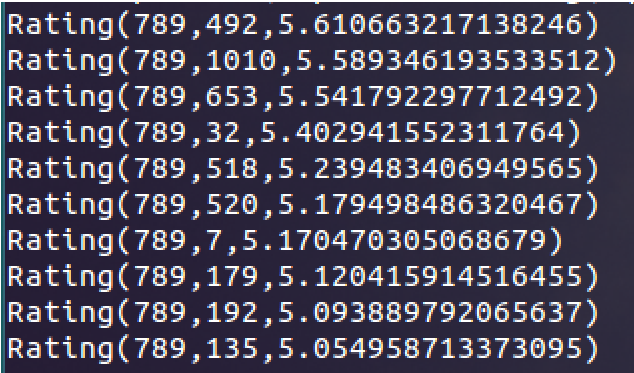
2. 为用户789推荐前10个物品:

1 val userId = 789 2 val K = 10 3 4 // 获取推荐列表 5 val topKRecs = model.recommendProducts(userId, K) 6 // 打印推荐列表 7 println(topKRecs.mkString("\n"))
结果为:
3. 初步检验推荐效果
获取到各个用户的推荐列表后,想必大家都想先看看用户评分最高的电影,和给他推荐的电影是不是有相似。
3.1 创建电影id - 电影名字典:
1 // 导入电影数据集 2 val movies = sc.textFile("/home/kylin/ml-100k/u.item") 3 // 建立电影id - 电影名字典 4 val titles = movies.map(line => line.split("\\|").take(2)).map(array => (array(0).toInt, array(1))).collectAsMap() 5 // 查看id为123的电影名 6 titles(123)
结果为:

这样后面就可以根据电影的id找到电影名了。
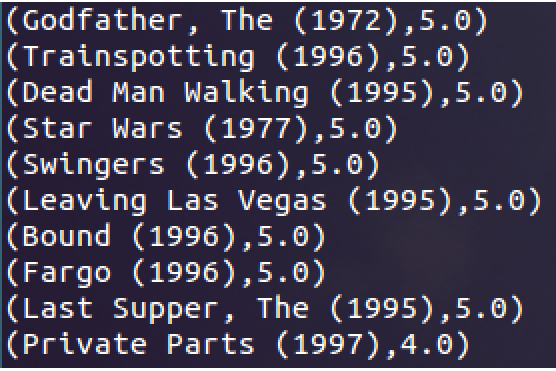
3.2 获取某用户的所有观影记录并打印:
1 // 建立用户名-其他RDD,并仅获取用户789的记录 2 val moviesForUser = ratings.keyBy(_.user).lookup(789) 3 // 获取用户评分最高的10部电影,并打印电影名和评分值 4 moviesForUser.sortBy(-_.rating).take(10).map(rating => (titles(rating.product), rating.rating)).foreach(println)
结果为:
3.3 获取某用户推荐列表并打印:
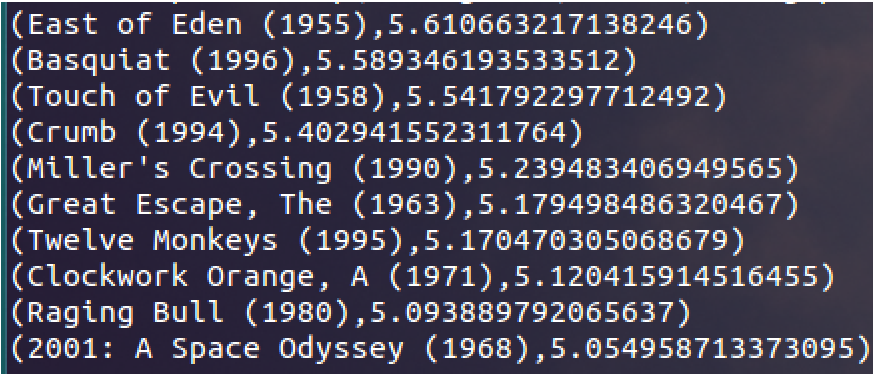
读者可以自行对比这两组列表是否有相似性。
第四步:物品推荐
很多时候还有另一种需求:就是给定一个物品,找到它的所有相似物品。
遗憾的是MLlib里面竟然没有包含内置的函数,需要自己用jblas库来实现 = =#。
1. 导入jblas库矩阵类,并创建一个余弦相似度计量函数:
1 // 导入jblas库中的矩阵类 2 import org.jblas.DoubleMatrix 3 // 定义相似度函数 4 def cosineSimilarity(vec1: DoubleMatrix, vec2: DoubleMatrix): Double = { 5 vec1.dot(vec2) / (vec1.norm2() * vec2.norm2()) 6 }
2. 接下来获取物品(本例以物品567为例)的因子特征向量,并将它转换为jblas的矩阵格式:
1 // 选定id为567的电影 2 val itemId = 567 3 // 获取该物品的隐因子向量 4 val itemFactor = model.productFeatures.lookup(itemId).head 5 // 将该向量转换为jblas矩阵类型 6 val itemVector = new DoubleMatrix(itemFactor)
3. 计算物品567和所有其他物品的相似度:
1 // 计算电影567与其他电影的相似度 2 val sims = model.productFeatures.map{ case (id, factor) => 3 val factorVector = new DoubleMatrix(factor) 4 val sim = cosineSimilarity(factorVector, itemVector) 5 (id, sim) 6 } 7 // 获取与电影567最相似的10部电影 8 val sortedSims = sims.top(K)(Ordering.by[(Int, Double), Double] { case (id, similarity) => similarity }) 9 // 打印结果 10 println(sortedSims.mkString("\n"))
结果为:
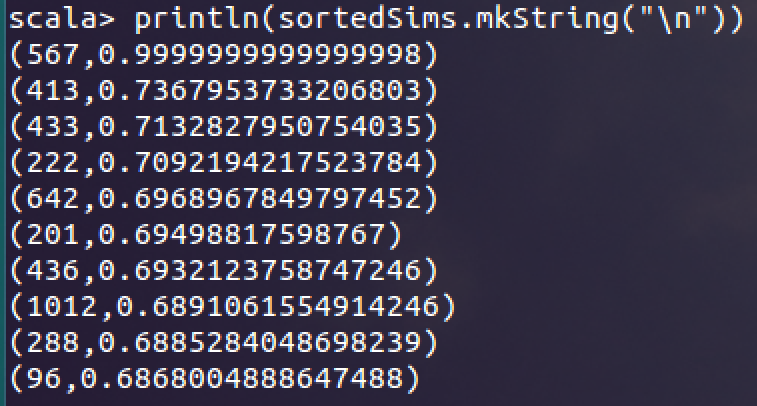
其中0.999999当然就是自己跟自己的相似度了。
4. 查看推荐结果:
1 // 打印电影567的影片名 2 println(titles(567)) 3 // 获取和电影567最相似的11部电影(含567自己) 4 val sortedSims2 = sims.top(K + 1)(Ordering.by[(Int, Double), Double] { case (id, similarity) => similarity }) 5 // 再打印和电影567最相似的10部电影 6 sortedSims2.slice(1, 11).map{ case (id, sim) => (titles(id), sim) }.mkString("\n")
结果为:
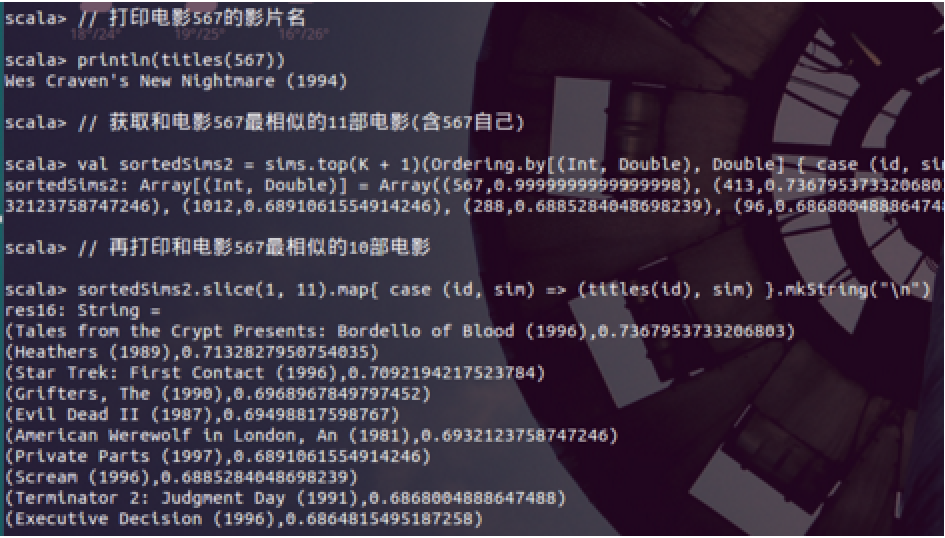
看看,这些电影是不是和567相似?
第五步:推荐效果评估
在Spark的ALS推荐系统中,最常用到的两个推荐指标分别为MSE和MAPK。其中MSE就是均方误差,是基于评分矩阵的推荐系统的必用指标。那么MAPK又是什么呢?
它称为K值平均准确率,最多用于TopN推荐中,它表示数据集范围内K个推荐物品与实际用户购买物品的吻合度。具体公式请读者自行参考有关文档。
本文推荐系统就是一个[基于用户-物品评分矩阵的TopN推荐系统],下面步骤分别用来获取本文推荐系统中的这两个指标。
PS:记得先要导入jblas库。
1. 首先计算MSE和RMSE:
1 // 创建用户id-影片id RDD 2 val usersProducts = ratings.map{ case Rating(user, product, rating) => (user, product)} 3 // 创建(用户id,影片id) - 预测评分RDD 4 val predictions = model.predict(usersProducts).map{ 5 case Rating(user, product, rating) => ((user, product), rating) 6 } 7 // 创建用户-影片实际评分RDD,并将其与上面创建的预测评分RDD join起来 8 val ratingsAndPredictions = ratings.map{ 9 case Rating(user, product, rating) => ((user, product), rating) 10 }.join(predictions) 11 12 // 导入RegressionMetrics类 13 import org.apache.spark.mllib.evaluation.RegressionMetrics 14 // 创建预测评分-实际评分RDD 15 val predictedAndTrue = ratingsAndPredictions.map { case ((user, product), (actual, predicted)) => (actual, predicted) } 16 // 创建RegressionMetrics对象 17 val regressionMetrics = new RegressionMetrics(predictedAndTrue) 18 19 // 打印MSE和RMSE 20 println("Mean Squared Error = " + regressionMetrics.meanSquaredError) 21 println("Root Mean Squared Error = " + regressionMetrics.rootMeanSquaredError)
基本原理是将实际评分-预测评分扔到RegressionMetrics类里,该类提供了mse和rmse成员,可直接输出获取。
结果为:

2. 计算MAPK:
// 创建电影隐因子RDD,并将它广播出去 val itemFactors = model.productFeatures.map { case (id, factor) => factor }.collect() val itemMatrix = new DoubleMatrix(itemFactors) val imBroadcast = sc.broadcast(itemMatrix) // 创建用户id - 推荐列表RDD val allRecs = model.userFeatures.map{ case (userId, array) => val userVector = new DoubleMatrix(array) val scores = imBroadcast.value.mmul(userVector) val sortedWithId = scores.data.zipWithIndex.sortBy(-_._1) val recommendedIds = sortedWithId.map(_._2 + 1).toSeq (userId, recommendedIds) } // 创建用户 - 电影评分ID集RDD val userMovies = ratings.map{ case Rating(user, product, rating) => (user, product) }.groupBy(_._1) // 导入RankingMetrics类 import org.apache.spark.mllib.evaluation.RankingMetrics // 创建实际评分ID集-预测评分ID集 RDD val predictedAndTrueForRanking = allRecs.join(userMovies).map{ case (userId, (predicted, actualWithIds)) => val actual = actualWithIds.map(_._2) (predicted.toArray, actual.toArray) } // 创建RankingMetrics对象 val rankingMetrics = new RankingMetrics(predictedAndTrueForRanking) // 打印MAPK println("Mean Average Precision = " + rankingMetrics.meanAveragePrecision)
结果为:

比较坑的是不能设置K,也就是说,计算的实际是MAP...... 正如属性名:meanAveragePrecision。
小结
感觉MLlib的推荐系统真的很一般,一方面支持的类型少 - 只支持ALS;另一方面支持的推荐系统算子也少,连输出个RMSE指标都要写好几行代码,太不方便了。
唯一的好处是因为接近底层,所以可以让使用者看到些实现的细节,对原理更加清晰。














 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









