









spark机器学习:
spark现如今在大数据领域有着很重的地位,lz最喜欢的是基于spark之上的机器学习,也就是MlIB,这是基于分布式环境下的机器学习的开发库,简单的来说就是开发及机器学习的API。稍微的提及一下,分布式环境下的机器学习算法的开发,算法核心原理并不会发生变化,但是由于是大量的数据,我们需要的是注意如何减小系统IO流的压力。举个例子来说,我们知道随机森林下面会涉及到每一个决策树会随机的选取特征和数据,问题来了,怎样设计数据的读取,这里介绍一篇大牛的文章,spark随机森林算法原理和源码解析。下面我们主要是看看环境的搭建和运行。
spark开发环境搭建:
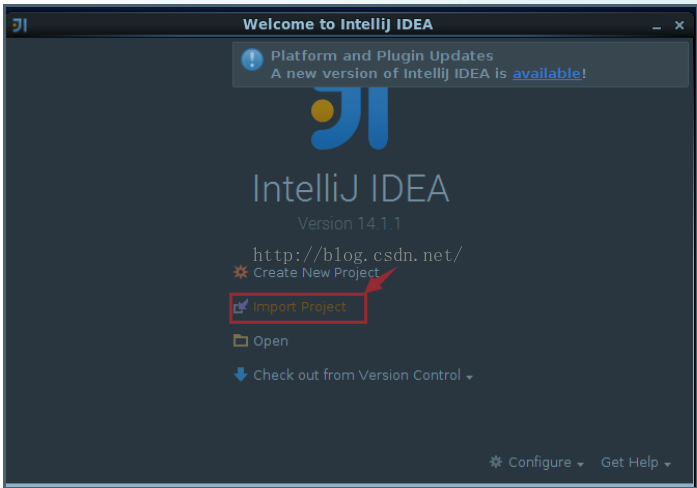
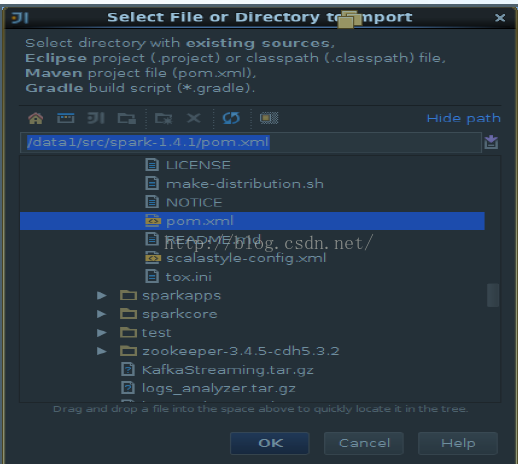
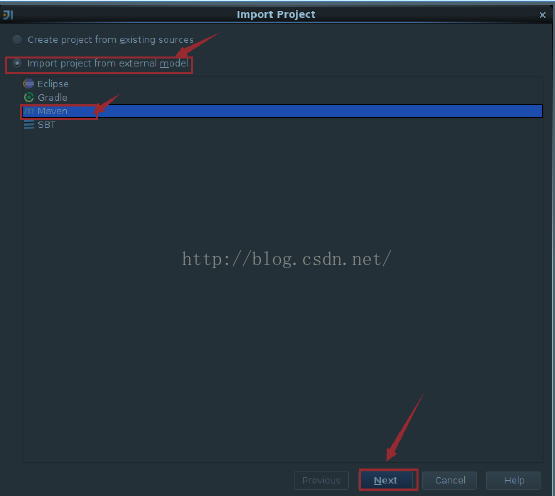
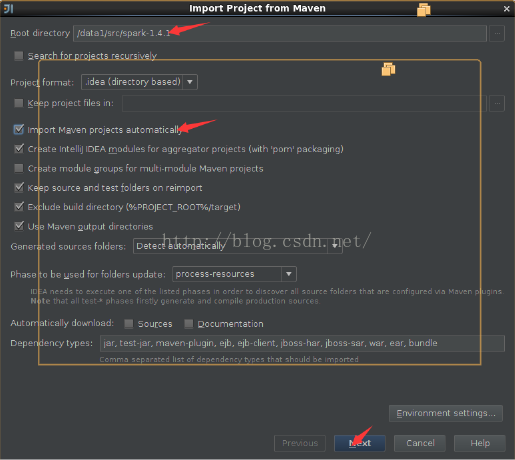
我们使用IDEA来开发spark环境,这里的需要引入scala的插件。按照以下的步骤先把下载到的spark源代码用IDEA打开。
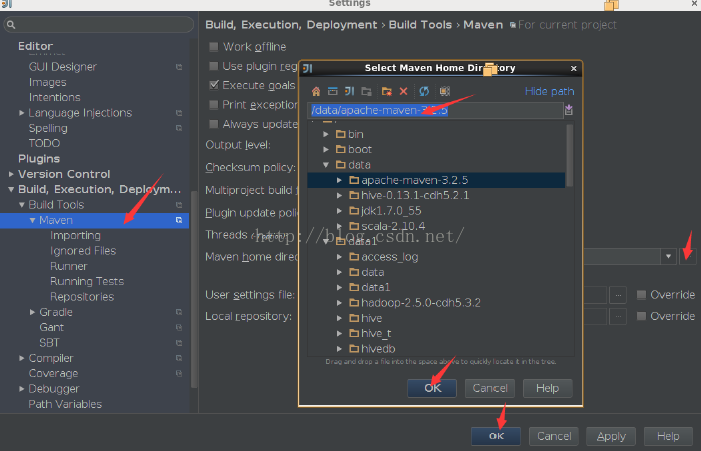
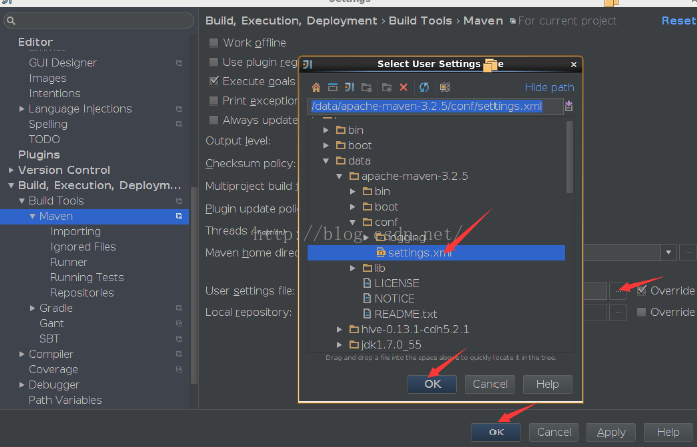
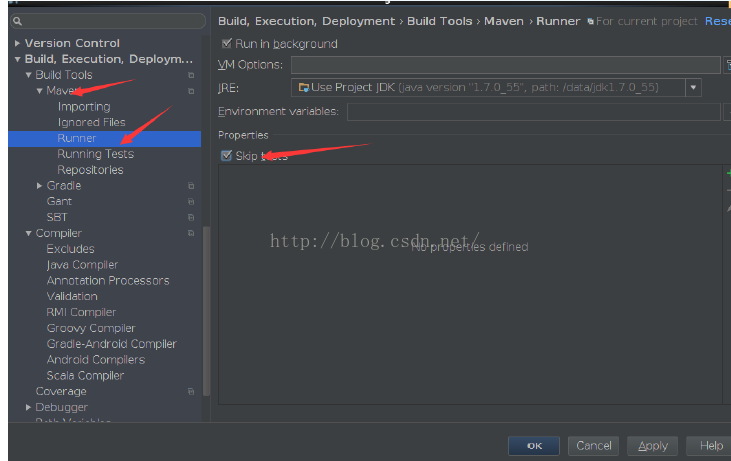
下面的这些步骤分别是把spark的源代码引入IDEA,配置maven相关环境,然后对spark的源代码进源代码编译,生成可执行的二进制文件。
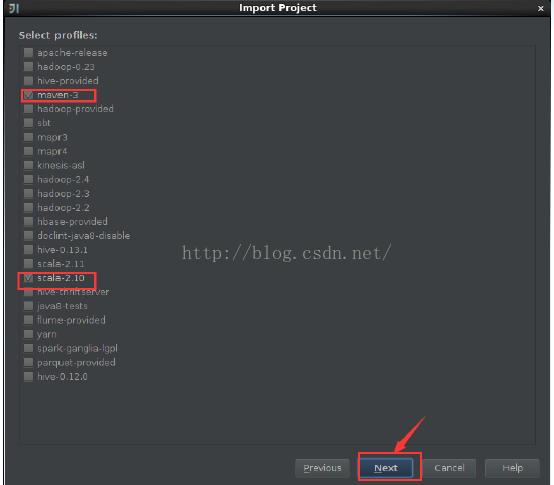
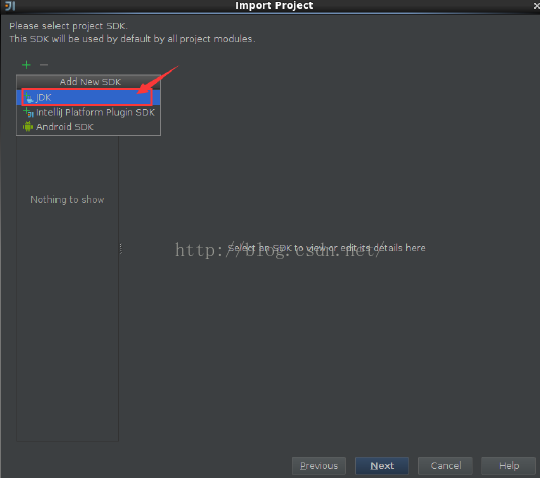
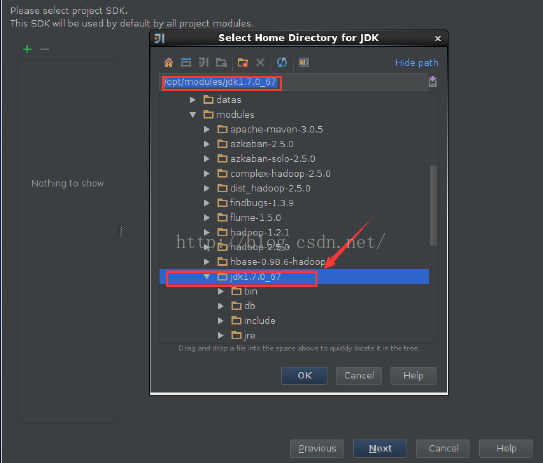
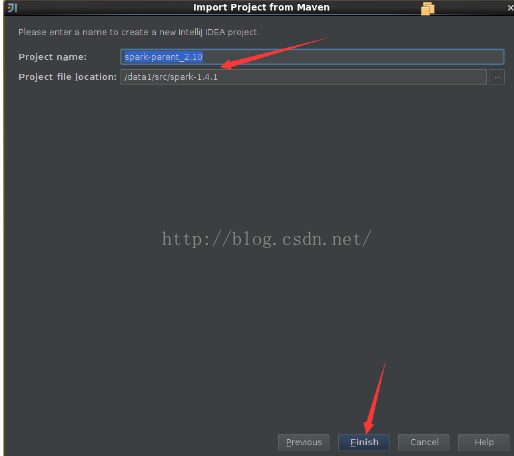

基于spark上的k-means均值聚类算法的运行
k均值聚类算法是一切聚类算法基础,我们在这里的代码进行了一定的注释,后面会谈到最大密度聚类,谱聚类等等
点击这里下载相关的数据
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
import org.apache.spark.mllib.linalg.Vectors
object KMeansClustering {
def main(args: Array[String]) {
//配置spark的运行环境,这里我们让他运行在本地
val conf = new SparkConf().setAppName("K-Means Clustering").setMaster("local")
//用conf创建一个sparkContex
val sc = new SparkContext(conf)
//获取trainData--sc.testFile( )
val rawTrainingData = sc.textFile("C:\\Users\\dell\\Downloads\\train.csv")
//数据的格式处理,并把数据缓存在内存
val parsedTrainingData = rawTrainingData.filter(!isColumnNameLine(_))
.map(line => {
Vectors.dense(line.split(",")
.map(_.trim)
.filter(!"".equals(_))
.map(_.toDouble))
}).cache()
//初始化参数
val numClusters = 8.toInt
val numIterations =30.toInt
val runTimes = 3.toInt
var clusterIndex: Int = 0
//函数的训练--函数的返回值就是clustCenter
val clusters: KMeansModel = KMeans.train(parsedTrainingData, numClusters, numIterations, runTimes)
println("Cluster Number:" + clusters.clusterCenters.length)
println("Cluster Centers Information Overview:")
clusters.clusterCenters.foreach(x =>
{
println("Center Point of Cluster " + clusterIndex + ":")
println(x)
clusterIndex += 1
})
//加载测试数据
val rawTestData = sc.textFile("C:\\Users\\dell\\Downloads\\test.csv")
val parsedTestData = rawTestData.map(line =>
{
Vectors.dense(line.split(",").map(_.trim).filter(!"".equals(_)).map(_.toDouble))
})
parsedTestData.collect().foreach(testDataLine =>
{
val predictedClusterIndex: Int = clusters.predict(testDataLine)
println("The data " + testDataLine.toString + " belongs to cluster " + predictedClusterIndex)
})
println("Spark MLlib K-means clustering test finished.")
}
//函数的作用就是判断去除第一行的数据--列名称
private def isColumnNameLine(line: String): Boolean = {
if (line != null && line.contains("Channel"))
true
else
false
}
}
在创建scala项目完成之后,我们需要把上面编译的源码包添加到libraries目录下面去,因为只有这样,我们才能在引入spark的先关包的时候不会出错。如图所示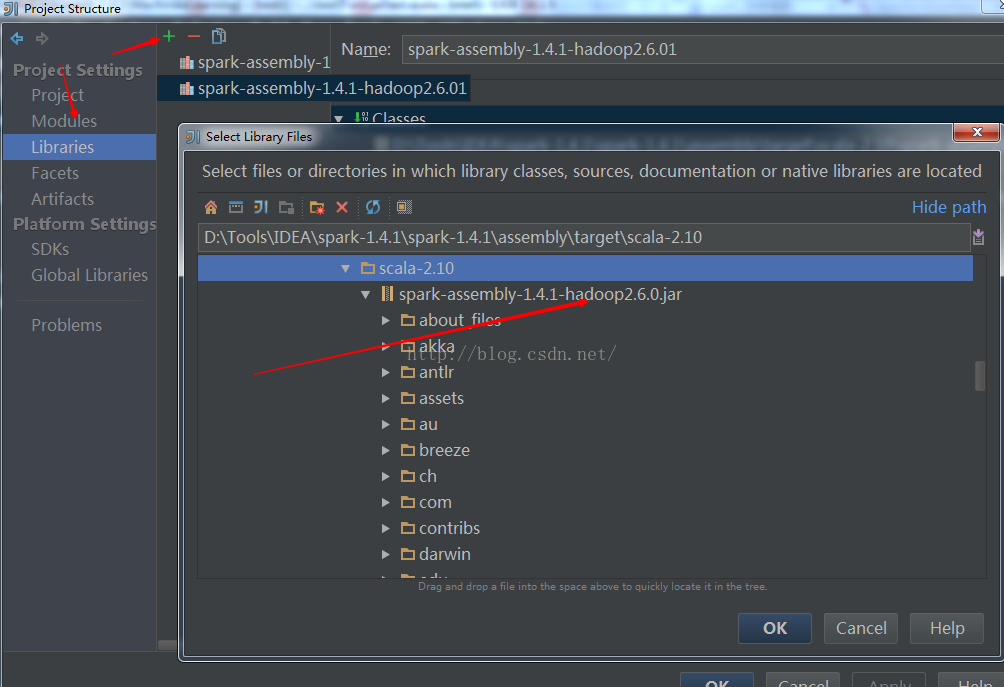
到这里之后,配置好文件的目录之后,编译运行就会得到需要的结果,注意,我们这里设置
val conf = new SparkConf().setAppName("K-Means Clustering").setMaster("local"),spark程序是运行在本地目录中的。













 6573
6573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









