







机器学习:浅谈先验概率,后验概率
在学习贝叶斯网络模型的时候,接触到好多比较麻烦的概念,今天又复习了一下,就写一下笔记,用来巩固一下。
主题模型LDA算法是自PLSA之后一个重大提升。PLSA的model如下:
P(di) ------>P(z|di)--------->P(wj|zk)
上面的P(di)被认为是文档的概率,P(z|di)是在给定第i篇文档的情况下,这篇文档的主题是Z的概率,P(wj|zk)表示的是在第k个主题上的第j个单词。上面主要是引入了一个主题Z的中间变量,被认为是隐变量。PLSA的model有点简单,并没有加入任何的先验概率,使得我们并不能人为的去控制它,所以就在这个基础之上提出了LDA主题模型。
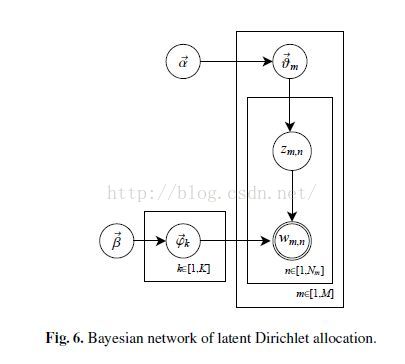
上面就是LDA的整体架构,区别于PLSA主要就是他加入了两个超参数阿尔法和贝塔。整个model解释:阿尔法是一个文档的主题分布,这个分布式是叫做多项式的共轭先验分布--狄利克雷分布,通俗点说就是分布之上的分布。从阿尔法中找一个主题分布(文档的主题分布),这个分布对应着很多的主题。然后我们从贝塔分布-->词分布(主题的词分布). Zmn可以认为是一个索引,叫做第m篇文档中的第n个词属于的那个主题。
在实际的应用中,我们去取阿尔法和贝塔相同的数值会达到相对较好的结果。下面先来介绍一下共轭分布:
想一下,正常情况下我们是如何计算参数呢?MLP极大似然估计是 假定我们给定的样本有一个存在的额固定的分布,但是这个分布鬼也不知道他是啥东西,但是人家却的确存在,那么我们就去求目标函数的最大值,来估计到底是什么样的参数可以使得我们这个目标函数得到最大值,这个参数就是我么想要的参数---这是频率学派的观点。有些同学感觉说的不明白,那就简单点说,假如想知道某个学校的男女人数,你就取学校门口蹲守,发现30秒之内出来了8个女生,2个男生,你会认为这个学校的男生比女生的人数少,看看,这个时候你已经无形的使用了极大似然函数啦。学校的那女比例可定是一个确定的参数,但是你不知道,通过观察你发现,只有在男女比例是0.2的情况下才符合目标函数(8女两男)的结果,这就是极大似然估计。但是注意这里我们假设这个参数固定的,固定的,固定的。假设参数固定是频率学派的观点。所以啊,这里就要说说了,谁告你人家的参数是固定的呢?这样就引出了bayesian学派:贝叶斯学派认为参数也是变化的,参数本身也服从某一个分布。所以我们可以认为频率学派是贝叶斯学派的一个特殊的点。不过,在大数据时代,频率学派会更加吃香,因为简化了model。
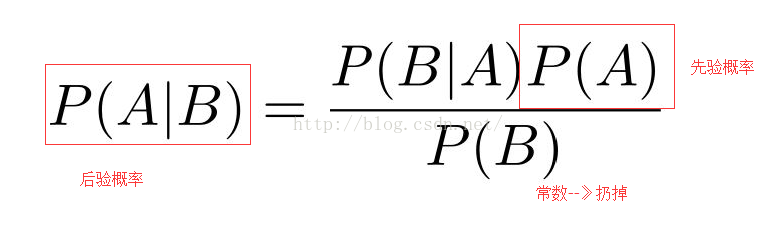
这么大的一个公式,好显眼。我们这里假设,B是可观测的变量,也就是数据变量,A表示B的分布的参数。
p(A)表示就是参数服从的分布,我们叫他先验概率
p(B|A)表示的是在知道分布的参数的条件下,数据B的概率;这里类似于我们的MLE,就是找那个参数会使得目标函数最大化。
P(A|B)表示的是在数据B的支持下,参数的概率,我们叫他后验概率。
这里我国P(A)是均匀分布,那么就会从bayesian学派退化到频率学派
说了这么长时间,到底什么是共轭分布啊。很简单,把上面表达式的常数去掉,会得到一个等式.我们要做的就是如何找到一个分布p(B|A)会使得先验概率和后验概率是同一个分布。能让先验和后验概率是同一个分布就是我们要找的。共轭分布就是两个分布的参数相同,就这么简单。那么你闲的没事儿干啊,为啥要提出他呢?
哈哈,这里我们就回到上面谈到的那个问题:假如在学校门口看到了2个男生,8个女生,你回估计这个学校的男女比例是2:8,但是这样真的好吗?这个假设就是我们前面谈到的频率学派的观点,该学派认为这个个数据的分布参数是固定的,简单粗暴,但是存在一个问题,就是不能人为的控制(我们把加先验参数定义为人为控制)。谈到这里就好说了,那么也就是说贝叶斯学派的观点就是认为原始数据服从的分布的参数是会变化的,也就是说,参数也是建立在一个分布之上,但是这个参数服从的分布的这个参数需要人为的定义,大家都叫他“上帝之手".想要处理上面过拟合的问题,我们可以把原来的2/10和8/10变成(2+5)/(10+10)和(8+5)/(10+10),那么男女比例就变成了0.35:0.65,哈哈,感觉这个数据有点靠谱吧?但是问题是对分子和分母同时加上5和10有什么理论依据呢?这里就是我们要谈谈的共轭分布啦。哈哈,当存在一个极大似然(MLE)使得先验和后验属于同一个分布(极大后验概率=先验概率*极大似然),那是多么的美好。在这里需要再申明一下先验和后验的物理意义:
先验:表示的是在有一定量的数据的前提下,我们对参数的估计概率,就是直接看到的数据
极大似然: 找到一个参数,使得我们观测到的data出现的概率最大
后验:就是在最合适的那个参数的前提下,data出现的最大概率
如果先验和后验是同一个分部,那么我们在分子和分母上面加上相同的数据,得到的结果就不会受到太大的影响。再看看,加入原来的采样的数据特别的多,有10000人,那么加上的5和10 就没有实际的作用了,对吧。这样就解释了过拟合的现象。这里对分子和分母加上一个数据的本质和最小二乘的目标函数后面加上L2正则化的本质相同,因为L2正则化也是假设这里的数据服从正态分布,都起到了解决过拟合的效果。

我们从上面知道贝塔分布是二项分布的共轭分布。直观的解释就是:贝塔分布是分布之上的分布,为啥这样说呢?这样看,原始的数据服从一个分布A分布,但是A分布的参数也有自己的分布B,B就是属于分布之上的分布。刚刚说过,那么贝塔分布的超参数ab对于结果有什么影响呢?看下图,这里假设只有两个主题:
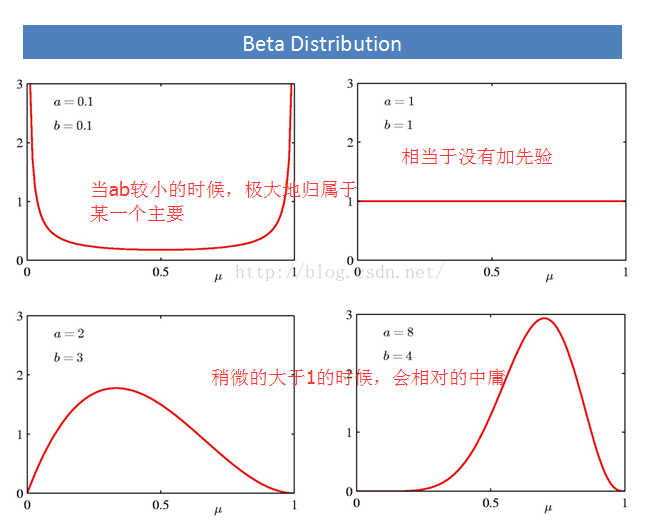
哈哈,后面看到狄利克雷分布的时候,会更加的鲜明。就先记录这么多吧。。。














 792
792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









